


C++ の配列 |宣言する |初期化 |配列へのポインタの例
配列とは
配列は、同じデータ型の要素を順番に格納するデータ構造です。 C++ 配列のサイズは固定です。
配列は、同様のデータ型の変数のコレクションと見なすことができます。各変数を宣言して個別に値を割り当てる代わりに、1 つの変数 (配列) を宣言して、さまざまな変数の値をそれに追加できます。配列に追加された各値は、インデックスによって識別されます。
この C++ チュートリアルでは、次のことを学びます:
- 配列とは?
- なぜ配列が必要なのですか?
- C++ で配列を宣言する
- 配列の初期化
- 配列の種類
- 一次元配列
- 多次元配列
- 二次元配列
- 三次元配列
- 配列へのポインタ
- 配列の値へのアクセス
- C++ における配列の利点
- C++ における配列の欠点
配列が必要な理由
配列は、どのプログラミング言語でも非常に重要です。これらは、変数または同様のデータ型のデータのコレクションを個別に格納するのではなく、一緒に格納するためのより便利な方法を提供します。配列の各値は個別にアクセスされます。
C++ で配列を宣言する
C++ での配列宣言には、配列によって格納される要素の数だけでなく、型の指定も含まれます。構文:
type array-Name [ array-Size ];
C++ で 1 次元配列を宣言するための規則。
- タイプ: 型は、配列に格納される要素の型であり、有効な C++ データ型である必要があります。
- 配列名: array-Name は、アレイに割り当てられる名前です。
- 配列サイズ: array-Size は、配列に格納される要素の数です。 0 より大きい整数でなければなりません。
たとえば、age という名前の配列を作成し、次のように 5 人の生徒の年齢を格納できます:
int age[5];
配列 age には、さまざまな学生の年齢を表す 5 つの整数が格納されます。
配列の初期化
配列の初期化は、要素を配列に割り当て/格納するプロセスです。初期化は、単一のステートメントで行うことも、1 つずつ行うこともできます。配列の最初の要素はインデックス 0 に格納され、最後の要素はインデックス n-1 に格納されることに注意してください。ここで、n は配列内の要素の総数です。
age 配列の場合、最初の要素はインデックス 0 に格納され、最後の要素はインデックス 4 に格納されます。
age 配列を使用して、配列の初期化を行う方法を示しましょう:
int age[5] = {19, 18, 21, 20, 17};
{ } 内の要素の総数は、[ ] 内に記述された値を超えることはできません。要素 19 はインデックス 0、インデックス 1 は 18、インデックス 2 は 21、インデックス 3 は 20、インデックス 4 は 17 です。配列に格納する要素の数を [ ] 内に指定しない場合、配列{ } 内に追加された要素を保持するのに十分な大きさになります。例:
int age[] = {19, 18, 21, 20, 17};
上記のステートメントは、前のものとまったく同じ配列を作成します。インデックスを使用して、1 つの要素を配列に割り当てることもできます。例:
age[3] = 20;
上記のステートメントは、age という名前の配列のインデックス 3 に値 20 を格納します。これは、20 が 4 になることを意味します。 配列の要素。
配列の種類
C++ 配列には次の 2 種類があります。
- 一次元配列
- 多次元配列
- 配列へのポインタ
一次元配列
これは、データ項目が 1 次元のみで直線的に配置された配列です。これは一般に 1 次元配列と呼ばれます。構文:
datatype array-name[size];
- array-name は、アレイの名前です。
- サイズは、配列に格納されるアイテムの数です。
例:
#include <iostream>
using namespace std;
int main()
{
int age[5] = { 19, 18, 21, 20, 17 };
for (int x = 0; x < 5; x++)
{
cout <<age[x]<<"\n";
}
}
出力:

コードのスクリーンショットは次のとおりです:
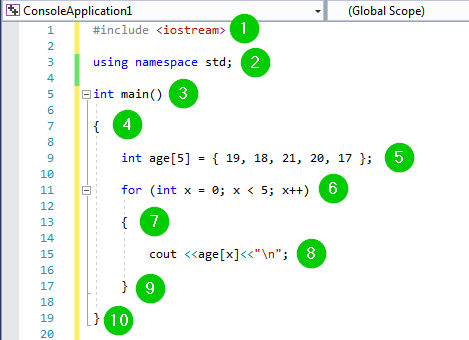
コードの説明:
<オール>多次元配列
これは、配列の配列を形成するようにデータ項目が配置された配列です。多次元配列は任意の数の次元を持つことができますが、2 次元配列と 3 次元配列が一般的です。構文:
datatype array-name[d1][d2][d3]...[dn];
array-name は、n 次元を持つ配列の名前です。例:
二次元配列
2D 配列は、データを 1D 配列のリストに格納します。これは、行と列を持つマトリックスです。 2D 配列を宣言するには、次の構文を使用します:
type array-Name [ x ][ y ];
型は有効な C++ データ型である必要があります。 2D 配列をテーブルと見なします。ここで、x は行数を表し、y は列数を表します。これは、a[x][y] の形式を使用して 2D 配列の各要素を識別することを意味します。ここで、x は要素が属する行の数、y は列の数です。
以下は、2D 配列を初期化する方法の例です:
int a[2][3] = {
{0, 2, 1} , /* row at index 0 */
{4, 3, 7} , /* row at index 1 */
};
上記の例では、2×3 行列として見ることができる 2D 配列があります。 2 行 3 列です。要素 0 は、インデックス 0 の行とインデックス 1 の列の交点にあるため、a[0][1] としてアクセスできます。要素 3 は、行インデックス 1 と列インデックス 2 の交点。
要素の異なる行を区別するために中括弧を追加しただけであることに注意してください。初期化は次のように行うこともできます:
int a[2][3] = {0, 2, 1, 4, 3, 7};
};
次の C++ の例は、2D 配列を初期化してトラバースする方法を示しています:
#include <iostream>
using namespace std;
int main()
{
// a 2x3 array
int a[3][2] = { {0, 2}, {1, 4}, {3, 7} };
// traverse array elements
for (int i=0; i<3; i++)
for (int j=0; j<2; j++)
{
cout << "a[" <<i<< "][" <<j<< "]: ";
cout << a[i][j] << endl;
}
return 0;
}
出力:
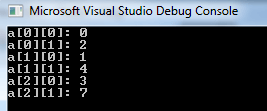
上記のコードのスクリーンショットは次のとおりです:
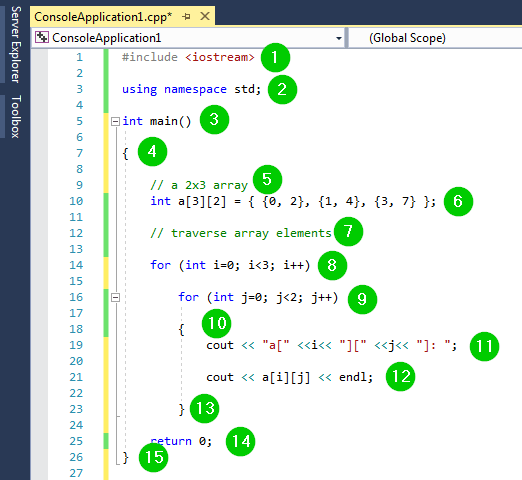
コードの説明:
<オール>三次元配列
3D 配列は配列の配列です。 3D 配列の各要素は、3 つのインデックスのセットによって識別されます。 3D 配列の要素にアクセスするには、3 つの for ループを使用します。例:
#include<iostream>
using namespace std;
void main()
{
int a[2][3][2] = {{{4, 8},{2, 4},{1, 6}}, {{3, 6},{5, 4},{9, 3}}};
cout << "a[0][1][0] = " << a[0][1][0] << "\n";
cout << "a[0][1][1] = " << a[0][1][1] << "\n";
}
出力:
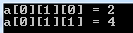
コードのスクリーンショットは次のとおりです:
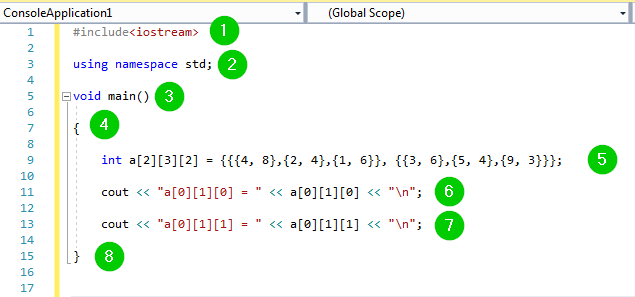
コードの説明:
<オール>配列へのポインタ
ポインタは、アドレスを保持する変数です。ポインターを使用して変数のアドレスを格納する以外に、ポインターを使用して配列セルのアドレスを格納できます。配列の名前は常に最初の要素を指します。以下の宣言を検討してください:
int age[5];
age は、age という名前の配列の最初の要素のアドレスである $age[0] へのポインターです。次の例を考えてみましょう:
#include <iostream>
using namespace std;
int main()
{
int *john;
int age[5] = { 19, 18, 21, 20, 17 };
john = age;
cout << john << "\n";
cout << *john;
}
出力:
上記の出力の最初の値は、コンピューターのメモリ内の配列の最初の要素に割り当てられたアドレスに応じて、異なる値を返す場合があることに注意してください。
コードのスクリーンショットは次のとおりです:
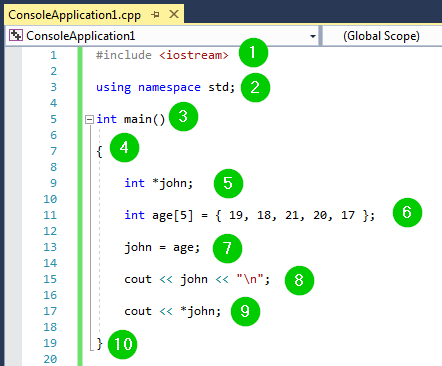
コードの説明:
<オール>配列名は定数ポインターとして使用でき、その逆も同様です。これは、配列 age のインデックス 3 に格納された値に *(age + 3) でアクセスできることを意味します。例:
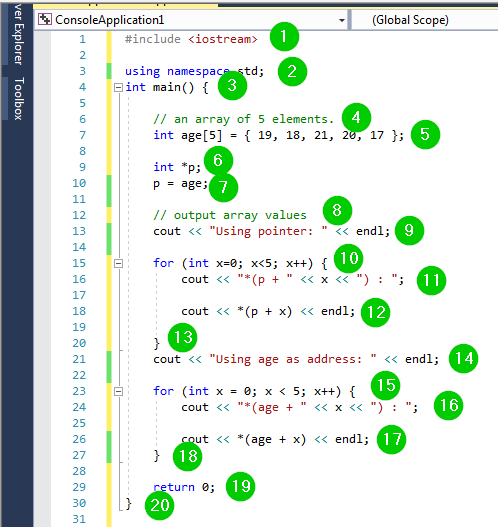
#include <iostream>
using namespace std;
int main() {
// an array of 5 elements.
int age[5] = { 19, 18, 21, 20, 17 };
int *p;
p = age;
// output array values
cout << "Using pointer: " << endl;
for (int x=0; x<5; x++) {
cout << "*(p + " << x << ") : ";
cout << *(p + x) << endl;
}
cout << "Using age as address: " << endl;
for (int x = 0; x < 5; x++) {
cout << "*(age + " << x << ") : ";
cout << *(age + x) << endl;
}
return 0;
}
出力:
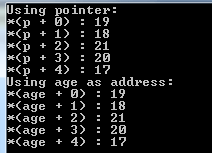
コードのスクリーンショットは次のとおりです:
コードの説明:
<オール>配列の値へのアクセス
配列の要素は、それぞれのインデックスを使用してアクセスされます。アクセスする要素のインデックスは、配列名の直後に角括弧 [ ] 内に追加されます。例:
int john = age[2];
上記の例では、単に john の年齢が age という名前の配列のインデックス 2 に格納されていることを示しています。これは、ジョンの年齢が 3 であることを意味します 配列 age の値。以下は、この値にアクセスして出力する方法を示す完全な C++ の例です:
#include<iostream>
using namespace std;
int main()
{
int age[5] = { 19, 18, 21, 20, 17 };
int john = age[2];
cout << "The age of John is:"<<john;
}
出力:

コードのスクリーンショットは次のとおりです:
コードの説明:
<オール>C++ における配列の利点
ここでは、C++ で配列を使用することの長所/利点を示します:
- 配列要素は簡単にトラバースできます。
- 配列データの操作が簡単。
- 配列要素はランダムにアクセスできます。
- 配列はコードの最適化を容易にします。したがって、少ないコードで多くの作業を実行できます。
- 配列データの並べ替えが簡単。
C++ における配列の欠点
- 配列のサイズは固定です。したがって、初期化後に新しい要素を追加することはできません。
- 必要以上のメモリを割り当てるとメモリ スペースが浪費され、メモリの割り当てが少なくなると問題が発生する可能性があります。
- 配列に格納される要素の数は、事前にわかっている必要があります。
まとめ
- 配列は、同じデータ型の要素を格納するデータ構造です。
- 配列要素は順番に格納されます。
- 配列要素は、それぞれのインデックスを使用して示されます。最初の要素はインデックス 0 にあり、最後の要素はインデックス n-1 にあります。ここで、 は配列要素の総数です。
- 配列の宣言には、配列要素のデータ型と、配列に格納される要素の数の定義が含まれます。
- 1 次元配列は要素を順番に格納します。
- 2 次元配列は、要素を行と列に格納します。
- 3 次元配列は配列の配列です。
- インデックスを使用して要素を配列に追加できます。
- 配列要素は、インデックスを使用してアクセスされます。
- 多次元配列には複数の次元があります。
- 配列名はその最初の要素を指します。
- 配列のサイズは固定されています。つまり、初期化後に配列に新しい要素を追加することはできません。
C言語