


Python RegEx:re.match()、re.search()、re.findall() と例
Python の正規表現とは
正規表現 (RE) プログラミング言語では、検索パターンを記述するために使用される特別なテキスト文字列です。コード、ファイル、ログ、スプレッドシート、さらにはドキュメントなどのテキストから情報を抽出するのに非常に役立ちます。
Python の正規表現を使用する際、最初に認識することは、すべてが本質的に文字であり、文字列とも呼ばれる特定の文字列に一致するパターンを記述していることです。 Ascii またはラテン文字はキーボード上にあるものであり、Unicode は外国語のテキストと一致させるために使用されます。数字と句読点、および $#@!% などのすべての特殊文字が含まれます。
この Python RegEx チュートリアルでは、次のことを学びます-
- 正規表現の構文
- w+ および ^ 式の例
- re.split 関数の \s 式の例
- 正規表現メソッドの使用
- re.match() の使用
- テキスト内のパターンの検索 (re.search())
- テキストに re.findall を使用する
- Python フラグ
- re.M または複数行フラグの例
たとえば、Python の正規表現は、文字列から特定のテキストを検索し、それに応じて結果を出力するようにプログラムに指示できます。式には次のものを含めることができます
- テキスト マッチング
- 繰り返し
- 分岐
- パターン構成など
Python の正規表現または RegEx は RE として示されます (RE、正規表現、または正規表現パターン) は re モジュール を介してインポートされます . Python は、ライブラリを通じて正規表現をサポートしています。 Python の正規表現は、修飾子、識別子、空白文字などのさまざまなものをサポートしています .
| 識別子 | 修飾子 | 空白文字 | エスケープが必要 |
|---|---|---|---|
| \d=任意の数字 (数字) | \d は数字を表します。例:\d{1,5} 424,444,545 などの 1 と 5 の間の数字を宣言します。 | \n =改行 | 。 + * ? [] $ ^ () {} | \ |
| \D=数字以外 (数字以外) | + =1 つ以上に一致 | \s=スペース | |
| \s =スペース (タブ、スペース、改行など) | ? =0 または 1 に一致 | \t =タブ | |
| \S=スペース以外 | * =0 以上 | \e =エスケープ | |
| \w =文字 (「_」を含む英数字に一致) | $ は文字列の最後にマッチ | \r =改行 | |
| \W =文字以外 (「_」を除く英数字以外の文字に一致) | ^ 文字列の先頭に一致 | \f=フォーム フィード | |
| . =文字 (ピリオド) 以外 | |または x/y に一致 | ——————– | |
| \b =改行を除く任意の文字 | [] =範囲または「分散」 | ——————- | |
| \. | {x} =この前のコードの量 | ——————– |
正規表現 (RE) 構文
import re
- 主に文字列の検索と操作に使用される Python に含まれる「re」モジュール
- Web ページの「スクレイピング」(Web サイトから大量のデータを抽出する)にも頻繁に使用されます
式 (w+) と (^) を使用して、この簡単な演習で式のチュートリアルを開始します。
w+ および ^ 式の例
- 「^」: この式は文字列の先頭に一致します
- 「w+」 “:この式は、文字列内の英数字と一致します
ここでは、コードで w+ および ^ 式を使用する方法の Python RegEx の例を示します。 Python の関数 re.findall() については、このチュートリアルの後半で説明しますが、しばらくの間、\w+ と \^ 式だけに焦点を当てます。
たとえば、文字列「guru99、教育は楽しい」の場合、w+ と ^ を使用してコードを実行すると、「guru99」という出力が得られます。
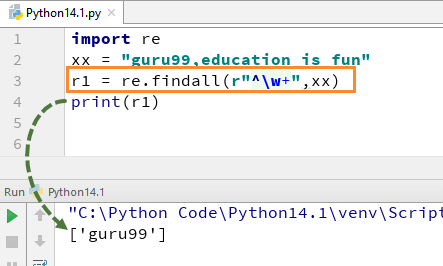
import re xx = "guru99,education is fun" r1 = re.findall(r"^\w+",xx) print(r1)
w+ から +sign を削除すると、出力が変化し、最初の文字の最初の文字、つまり [g] のみが表示されることに注意してください。
re.split 関数の \s 式の例
- 「s」:この表現は、文字列にスペースを作成するために使用されます
この Python の正規表現がどのように機能するかを理解するために、分割関数の単純な Python 正規表現の例から始めます。この例では、「re.split」関数を使用して各単語を分割し、同時に、文字列内の各単語を個別に解析できる式 \s を使用しています。
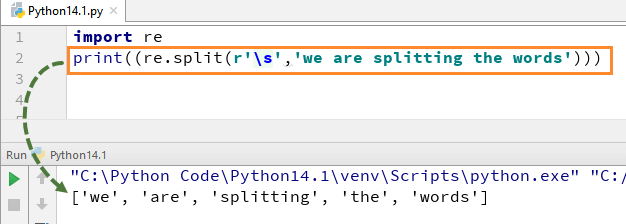
このコードを実行すると、出力 [「we」、「are」、「splitting」、「the」、「words」] が得られます。
では、s から「\」を削除するとどうなるか見てみましょう。出力に「s」のアルファベットはありません。これは、文字列から「\」を削除したためです。「s」は通常の文字として評価され、文字列内で「s」が見つかった場所で単語が分割されます。
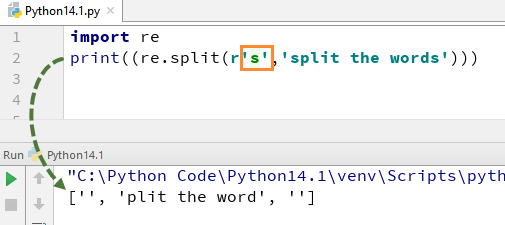
同様に、\d、\D、$、\.、\b など、Python でさまざまな方法で使用できる一連の他の Python 正規表現があります。
これが完全なコードです
import re xx = "guru99,education is fun" r1 = re.findall(r"^\w+", xx) print((re.split(r'\s','we are splitting the words'))) print((re.split(r's','split the words')))
次に、Python で正規表現で使用されるメソッドの種類を見ていきます。
正規表現メソッドの使用
「re」パッケージは、入力文字列に対して実際にクエリを実行するためのいくつかのメソッドを提供します。 Python での re のメソッドを見てみましょう:
- re.match()
- re.search()
- re.findall()
注意 :正規表現に基づいて、Python は 2 つの異なるプリミティブ操作を提供します。 match メソッドは文字列の先頭でのみ一致をチェックしますが、検索は文字列内の任意の場所で一致をチェックします。
re.match()
re.match() Python の re の関数は、正規表現パターンを検索し、最初に見つかったものを返します。 Python RegEx Match メソッドは、文字列の先頭でのみ一致をチェックします。したがって、最初の行で一致が見つかった場合、一致オブジェクトが返されます。ただし、他の行で一致が見つかった場合、Python RegEx Match 関数は null を返します。
たとえば、次の Python re.match() 関数のコードを考えてみましょう。 「w+」および「\W」という表現は、文字「g」で始まる単語と一致し、その後、「g」で始まらないものは識別されません。リストまたは文字列の各要素の一致を確認するには、この Python re.match() の例で forloop を実行します。
re.search():テキスト内のパターンの検索
re.search() 関数は正規表現パターンを検索し、最初に見つかったものを返します。 Python re.match() とは異なり、入力文字列のすべての行をチェックします。 Python の re.search() 関数は、パターンが見つかった場合は一致オブジェクトを返し、パターンが見つからない場合は「null」を返します
search() の使い方
search() 関数を使用するには、最初に Python re モジュールをインポートしてからコードを実行する必要があります。 Python re.search() 関数は、メイン文字列からスキャンする「パターン」と「テキスト」を取ります
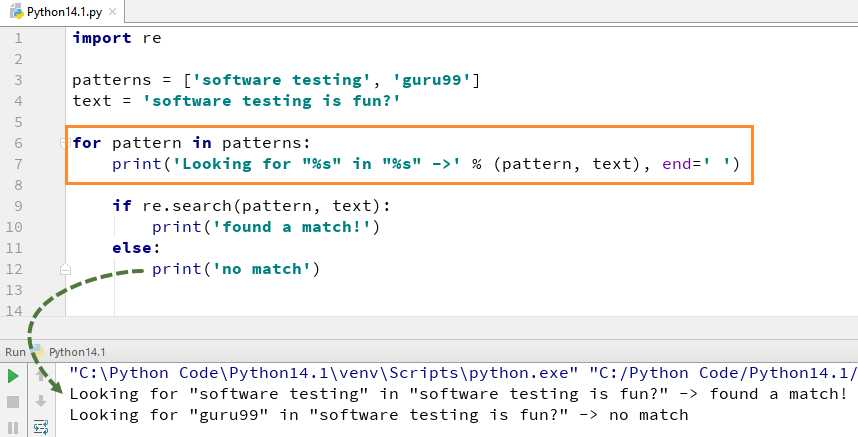
たとえば、ここでは、「Software Testing is fun」というテキスト文字列で、「Software testing」「guru99」という 2 つのリテラル文字列を探します。 「ソフトウェア テスト」では一致が見つかったため、Python re.search() の例の出力を「一致が見つかりました」として返しますが、単語「guru99」については文字列で見つからなかったため、「一致なし」として出力を返します。
re.findall()
findall() モジュールは、特定のパターンに一致する「すべて」の出現を検索するために使用されます。対照的に、search() モジュールは、指定されたパターンに一致する最初のオカレンスのみを返します。 findall() は、ファイルのすべての行を反復処理し、パターンの重複しないすべての一致を 1 つのステップで返します。
Python で re.findall() を使用する方法
ここに電子メール アドレスのリストがあり、リストからすべての電子メール アドレスを取得する必要があるため、Python でメソッド re.findall() を使用します。リストからすべての電子メール アドレスが検索されます。
re.findall() の例の完全なコードは次のとおりです
import re
list = ["guru99 get", "guru99 give", "guru Selenium"]
for element in list:
z = re.match("(g\w+)\W(g\w+)", element)
if z:
print((z.groups()))
patterns = ['software testing', 'guru99']
text = 'software testing is fun?'
for pattern in patterns:
print('Looking for "%s" in "%s" ->' % (pattern, text), end=' ')
if re.search(pattern, text):
print('found a match!')
else:
print('no match')
abc = 'guru99@google.com, careerguru99@hotmail.com, users@yahoomail.com'
emails = re.findall(r'[\w\.-]+@[\w\.-]+', abc)
for email in emails:
print(email) Python フラグ
多くの Python 正規表現メソッドと正規表現関数は、Flags と呼ばれるオプションの引数を取ります。このフラグは、指定された Python 正規表現パターンの意味を変更できます。これらを理解するために、これらのフラグの例を 1 つまたは 2 つ見ていきます。
Python インクルードで使用されるさまざまなフラグ
| 正規表現フラグの構文 | このフラグの機能 |
|---|---|
| [re.M] | 開始/終了を各行に考慮する |
| [re.I] | 大文字と小文字を区別しません |
| [re.S] | [ . ] |
| [re.U] | { \w,\W,\b,\B} を Unicode ルールに準拠させる |
| [re.L] | {\w,\W,\b,\B} をロケールに合わせる |
| [re.X] | 正規表現でコメントを許可 |
re.M または複数行フラグの例
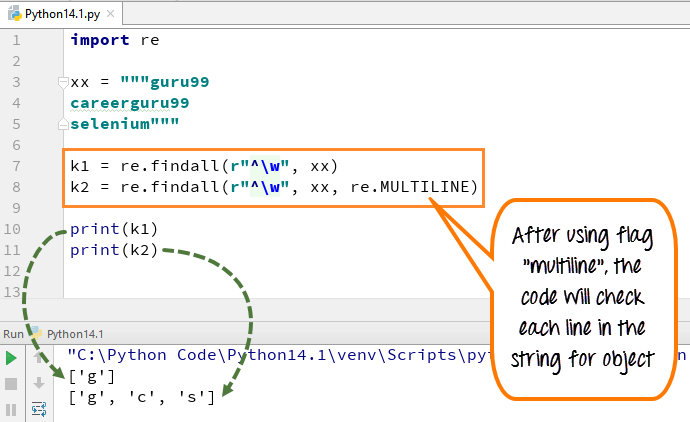
複数行では、パターン文字 [^] は文字列の最初の文字と各行の先頭 (各改行の直後) に一致します。一方、小文字の「w」は、スペースを文字でマークするために使用されます。コードを実行すると、最初の変数「k1」は単語 guru99 の文字「g」のみを出力しますが、複数行フラグを追加すると、文字列内のすべての要素の最初の文字がフェッチされます。
コードはこちら
import re xx = """guru99 careerguru99 selenium""" k1 = re.findall(r"^\w", xx) k2 = re.findall(r"^\w", xx, re.MULTILINE) print(k1) print(k2)
- 文字列「guru99…」の変数 xx を宣言しました。キャリアグル99….セレン」
- 複数行のフラグを使用せずにコードを実行すると、行から「g」のみが出力されます
- フラグ「multiline」を指定してコードを実行します。「k2」を出力すると、「g」、「c」、および「s」として出力されます
- 上記の例で複数行を追加した後と追加する前の違い
同様に、re.U (Unicode)、re.L (ロケールに従う)、re.X (コメントを許可) などの他の Python フラグも使用できます。
Python 2 の例
上記のコードは Python 3 の例です。Python 2 で実行する場合は、次のコードを検討してください。
# Example of w+ and ^ Expression
import re
xx = "guru99,education is fun"
r1 = re.findall(r"^\w+",xx)
print r1
# Example of \s expression in re.split function
import re
xx = "guru99,education is fun"
r1 = re.findall(r"^\w+", xx)
print (re.split(r'\s','we are splitting the words'))
print (re.split(r's','split the words'))
# Using re.findall for text
import re
list = ["guru99 get", "guru99 give", "guru Selenium"]
for element in list:
z = re.match("(g\w+)\W(g\w+)", element)
if z:
print(z.groups())
patterns = ['software testing', 'guru99']
text = 'software testing is fun?'
for pattern in patterns:
print 'Looking for "%s" in "%s" ->' % (pattern, text),
if re.search(pattern, text):
print 'found a match!'
else:
print 'no match'
abc = 'guru99@google.com, careerguru99@hotmail.com, users@yahoomail.com'
emails = re.findall(r'[\w\.-]+@[\w\.-]+', abc)
for email in emails:
print email
# Example of re.M or Multiline Flags
import re
xx = """guru99
careerguru99
selenium"""
k1 = re.findall(r"^\w", xx)
k2 = re.findall(r"^\w", xx, re.MULTILINE)
print k1
print k2
まとめ
プログラミング言語の正規表現は、検索パターンを記述するために使用される特別なテキスト文字列です。数字、句読点、および $#@!% などのすべての特殊文字が含まれます。式にはリテラルを含めることができます
- テキスト マッチング
- 繰り返し
- 分岐
- パターン構成など
Python では、正規表現は RE として示されます (RE、正規表現、または正規表現パターン) は、Python re モジュールを通じて埋め込まれます。
- 主に文字列の検索と操作に使用される Python に含まれる「re」モジュール
- ウェブページの「スクレイピング」(ウェブサイトから大量のデータを抽出する)にも頻繁に使用
- 正規表現メソッドには以下が含まれます re.match()、re.search()&re.findall()
- その他の Python RegEx 置換メソッドは、re 内の一致する文字列を置換するために使用される sub() および subn() です
- Python フラグ 多くの Python 正規表現メソッドと正規表現関数は、フラグと呼ばれるオプションの引数を取ります
- このフラグは、指定された正規表現パターンの意味を変更できます
- 正規表現メソッドで使用されるさまざまな Python フラグは、re.M、re.I、re.S などです。
Python