


Python XML パーサー チュートリアル:xml ファイルの例を読む (Minidom、ElementTree)
XML とは?
XML は eXtensible Markup Language の略です。少量から中量のデータを保存および転送するように設計されており、構造化された情報を共有するために広く使用されています。
Python を使用すると、XML ドキュメントを解析および変更できます。 XML ドキュメントを解析するには、XML ドキュメント全体をメモリに格納する必要があります。このチュートリアルでは、Python で XML minidom クラスを使用して XML ファイルを読み込んで解析する方法を説明します。
このチュートリアルでは、次のことを学びます-
- minidom を使用して XML を解析する方法
- XML ノードの作成方法
- ElementTree を使用して XML を解析する方法
minidom を使用して XML を解析する方法
解析するサンプル XML ファイルを作成しました。
ステップ 1) ファイル内には、名、姓、自宅、専門分野 (SQL、Python、テスト、ビジネス) が表示されます
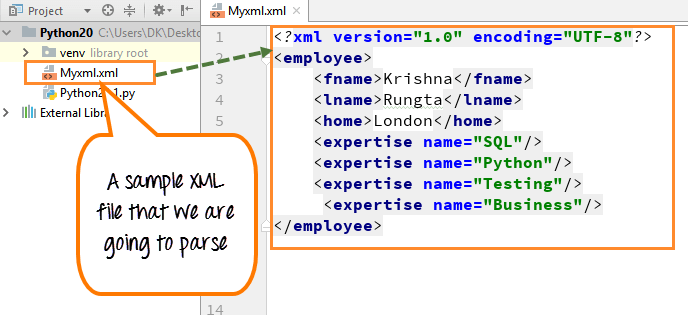
ステップ 2) ドキュメントを解析したら、「ノード名」を出力します ドキュメントのルートと「firstchild タグ名」 .タグ名とノード名は、XML ファイルの標準プロパティです。

- xml.dom.minidom モジュールをインポートし、解析する必要があるファイル (myxml.xml) を宣言します
- このファイルには、姓、名、家、専門知識など、従業員に関する基本的な情報が含まれています。
- XML minidom の parse 関数を使用して、XML ファイルを読み込んで解析します
- 変数 doc があり、doc は解析関数の結果を取得します
- ファイルからノード名と子タグ名を出力したいので、print 関数で宣言します
- コードを実行 - XML ファイルからノード名 (#document) を出力し、XML ファイルから最初の子タグ名 (employee) を出力します
注意 :
ノード名と子タグ名は、XML dom の標準的な名前またはプロパティです。これらのタイプの命名規則に慣れていない場合に備えて。
ステップ 3) XML ドキュメントから XML タグのリストを呼び出して出力することもできます。ここでは、SQL、Python、テスト、ビジネスなどの一連のスキルを出力しました。
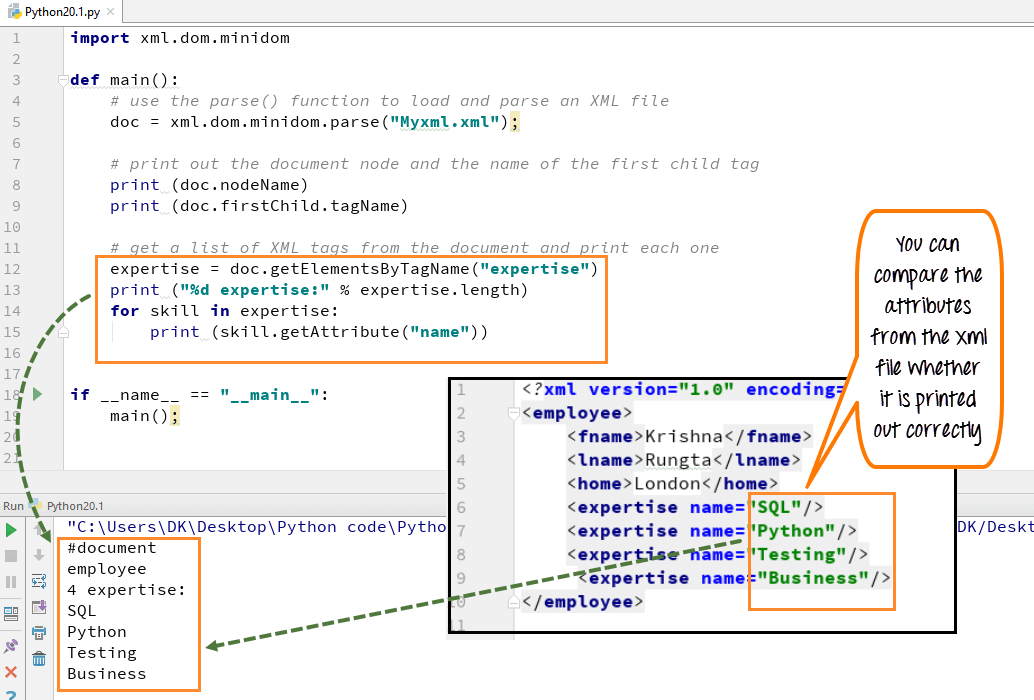
- 従業員が持っているすべての専門知識名を抽出する変数の専門知識を宣言します
- 「getElementsByTagName」という DOM 標準関数を使用する
- skill という名前のすべての要素を取得します
- スキルタグごとにループを宣言します
- コードを実行 - 4 つのスキルのリストが表示されます
XML ノードの作成方法
「createElement」関数を使用して新しい属性を作成し、この新しい属性またはタグを既存の XML タグに追加できます。 XML ファイルに新しいタグ「BigData」を追加しました。
<オール> 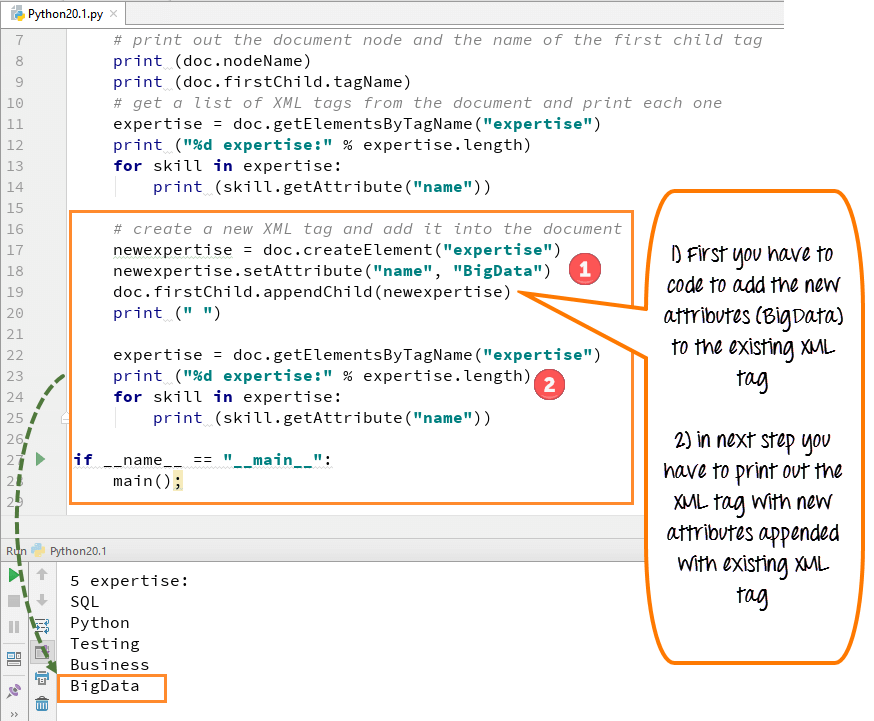
- 新しい XML を追加してドキュメントに追加するには、コード「doc.create elements」を使用します
- このコードは、新しい属性「ビッグデータ」の新しいスキル タグを作成します
- このスキル タグをドキュメントの最初の子 (従業員) に追加します
- コードを実行します。新しいタグ「ビッグデータ」が他の専門知識のリストとともに表示されます
XML パーサーの例
Python 2 の例
import xml.dom.minidom
def main():
# use the parse() function to load and parse an XML file
doc = xml.dom.minidom.parse("Myxml.xml");
# print out the document node and the name of the first child tag
print doc.nodeName
print doc.firstChild.tagName
# get a list of XML tags from the document and print each one
expertise = doc.getElementsByTagName("expertise")
print "%d expertise:" % expertise.length
for skill in expertise:
print skill.getAttribute("name")
# create a new XML tag and add it into the document
newexpertise = doc.createElement("expertise")
newexpertise.setAttribute("name", "BigData")
doc.firstChild.appendChild(newexpertise)
print " "
expertise = doc.getElementsByTagName("expertise")
print "%d expertise:" % expertise.length
for skill in expertise:
print skill.getAttribute("name")
if name == "__main__":
main(); Python 3 の例
import xml.dom.minidom
def main():
# use the parse() function to load and parse an XML file
doc = xml.dom.minidom.parse("Myxml.xml");
# print out the document node and the name of the first child tag
print (doc.nodeName)
print (doc.firstChild.tagName)
# get a list of XML tags from the document and print each one
expertise = doc.getElementsByTagName("expertise")
print ("%d expertise:" % expertise.length)
for skill in expertise:
print (skill.getAttribute("name"))
# create a new XML tag and add it into the document
newexpertise = doc.createElement("expertise")
newexpertise.setAttribute("name", "BigData")
doc.firstChild.appendChild(newexpertise)
print (" ")
expertise = doc.getElementsByTagName("expertise")
print ("%d expertise:" % expertise.length)
for skill in expertise:
print (skill.getAttribute("name"))
if __name__ == "__main__":
main(); ElementTree を使用して XML を解析する方法
ElementTree は、XML を操作するための API です。 ElementTree は XML ファイルを処理する簡単な方法です。
次の XML ドキュメントをサンプル データとして使用しています:
<data>
<items>
<item name="expertise1">SQL</item>
<item name="expertise2">Python</item>
</items>
</data>
ElementTree を使用した XML の読み取り:
最初に xml.etree.ElementTree モジュールをインポートする必要があります。
import xml.etree.ElementTree as ET
それでは、ルート要素を取得しましょう:
root = tree.getroot()
上記の xml データを読み取るための完全なコードは次のとおりです
import xml.etree.ElementTree as ET
tree = ET.parse('items.xml')
root = tree.getroot()
# all items data
print('Expertise Data:')
for elem in root:
for subelem in elem:
print(subelem.text)
出力:
Expertise Data: SQL Python
まとめ:
Python を使用すると、一度に 1 行ずつではなく、XML ドキュメント全体を一度に解析できます。 XML ドキュメントを解析するには、ドキュメント全体をメモリに保持する必要があります。
- XML ドキュメントを解析するには
- xml.dom.minidom をインポート
- 関数「parse」を使用してドキュメントを解析します ( doc=xml.dom.minidom.parse (ファイル名);
- コード (=doc.getElementsByTagName( “xml タグの名前”) を使用して、XML ドキュメントから XML タグのリストを呼び出します
- XML ドキュメントに新しい属性を作成して追加するには
- 関数「createElement」を使用
Python
- Python ファイル I/O
- Java BufferedReader:例を使用して Java でファイルを読み取る方法
- 例を使用した Python 文字列 strip() 関数
- Python 文字列の長さ | len() メソッドの例
- Yield in Python チュートリアル:Generator &Yield vs Return の例
- 例を使用したコレクション内の Python カウンター
- Python の Enumerate() 関数:ループ、タプル、文字列 (例)
- Python ファイルが存在するかどうかを確認します。 Python でディレクトリが存在するかどうかを確認する方法
- Python JSON:JSON ファイルのエンコード (ダンプ)、デコード (ロード)、読み取り
- Python List index() と例
- Python - ファイル I/O