


カスタム音声エージェントへの移行の背後にあるものは何ですか?
自動化は未来への道です。私たちは今の時代に生きており、すべてが迅速に答えられ、達成され、受け取られることを望んでいます。この根本的な変化にもかかわらず、多くの人々はテクノロジーを受け入れていません。一部の人にとっては、それはライフスタイルに関連しています。大企業はシステムを変革するには不格好すぎる可能性があり、個人はタッチスクリーンの操作方法を学びたくないという自分のやり方で立ち往生する可能性があります。ただし、ほとんどの場合、データは誰が所有し、どのように安全に保つかによって決まります。
ソリューション?声と同じくらい簡単です。音声対応テクノロジーは、データを近くに保ちながら自動化の必要性を解き放つことができます。これは、場所やプラットフォームに関係なく、私たちが毎日使用しているものです。デジタルトランスフォーメーションがますます多くのアプリケーションに影響を与え続けるにつれて、音声エージェントがその答えです。 AlexaやGoogleVoiceのような人気のある音声エージェントの一般的な名前とは別に、テクノロジーに組み込まれたカスタム音声プラットフォームの構築を模索している企業が増えています。独自の音声プラットフォームは、独自のデータを保持および制御しようとしている企業にとって前進の道となるでしょう。
混乱の背後には自動化があります
モノのインターネット(IoT)が人工知能(AI)から構築されるにつれて、自動化の必要性が高まり始めています。 IoTがAIと連携すると、膨大で幅広いインターネットデバイスのコレクションに対するユーザーの制御が向上します。 Google Voice、Amazon Alexa、Microsoft Cortana、または独自に作成されたプラットフォームなどのプラットフォームを介して、家庭内外で音声の有効化が拡大し始めています。 Harman Embedded Audioでは、地球上のすべての音声エンジンと連携し、市場の幅を直接理解しています。独自のカスタム音声アシスタントプラットフォームで音声対応製品を構築しようとしている企業が増えているため、データを管理できます。
音声制御の需要が高まっています
これは、オーディオで最も注目されているトレンドの1つです。タッチスクリーンなどの機能がほぼユビキタスになっているユーザーインターフェイスの次の重要な点は、デバイスと通信できることです。 Voiceは、次世代の人間のコラボレーションをリードしています。コンピューターでの自然言語処理について考えてみてください。音声は、マシンが聞きたいものに合うように処理されますが、同じ処理済みファイルを再生すると、機械的で不自然になります。電話で話す場合も同じです。誰かと一緒に部屋にいるような印象を与えることはありません。これは音声が行く必要がある場所であり、上記のユニークな音声プラットフォームが続く場所です。
カスタム音声エージェントの外観とビルドの内容
すべての音声ソリューションは異なりますが、すべてのソリューションが、ユーザーデータを収集および保護しながら、ユースケースの必要な要件に適応するのに十分な柔軟性を備えていることが重要です。これを実現するために、音声エージェントの構築と統合には3つの主要な要素が関係しています。
1つ目は遠方場アルゴリズムです。遠方界の音声をキャプチャする最上位のアルゴリズムを使用します。私の会社では、Soniqueアルゴリズムの4つの主要なソフトウェアアルゴリズムを使用しています。ノイズ抑制、音響ノイズキャンセル、音の分離、ビーム形成、および音声アクティビティの検出です。これらのアルゴリズムは、音声対応アプリケーションをサポートするために相互に組み合わせて使用するために特別に開発されました。
それらはどのように機能しますか?スマートスピーカーと人間を比較することを考えてください。 DSP / SOCはスピーカーの「頭脳」として機能し、マイクは耳であり、スピーカーは口です。私たちにとって、誰かが私たちの名前を呼ぶとき、私たちの脳は私たちの周りのすべてのノイズをキャンセルし、そのキーワードにすべてのエネルギーを注ぎます。これは、スマートスピーカーで達成したことです。キーワードが検出されると、マイクはさまざまなノイズ抑制技術を使用し、すべての電力を音源に向けます。その過程で、周囲のノイズのほとんどをキャンセルします。音響環境では、周囲のノイズ、ローカルスピーカー、HVACなど、スピーカーからマイクにフィードバックをエコーする多くのノイズ源があります。これらのノイズ源にはそれぞれ独自のソリューションが必要です。 Soniqueアルゴリズムは、ノイズを抑制し、可能な限り最高のクリアな音声コマンドをキャプチャします。
また、キーワードスポッティング(KWS)エンジンを構築することも重要です。 KWSは、「Alexa」や「OK Google」などのキーワードを検出して、会話を開始します。私はほぼすべてのKWSエンジンプロバイダーと協力してきましたが、それぞれが高度なカスタマイズ可能で、常にリッスンし、軽量で組み込み型のディープニューラルネットワークを利用しています。遠方界の音声アプリケーションで優れたカスタマーエクスペリエンスを実現するための重要な要素は、本人拒否率と本人拒否率です。現実の世界では、テレビ、家電製品、シャワーなどの外部ノイズが多く、オーディオ再生のキャンセルが不完全になるため、本人拒否率を低く維持することは非常に困難です。経験豊富な開発者は、KWSエンジンを調整して、False AcceptRateを低く抑えます。
最後に、自動音声認識(ASR)エンジンが音声をテキストに変換します。 ASRは、コアの音声認識(STT)ツールと、生のテキストをデータに変換する自然言語理解(NLU)で構成されています。エンジンには、スキル、つまり、回答を提供できる知識ベースと、逆テキスト読み上げツールも必要です。たとえば、E-NOVAと呼ばれるASRエンジンを開発しました。これは、マルチプラットフォームのオンプレミス統合を提供し、複数の言語(現在、7つの言語と成長中)をサポートし、トレーニング可能なモデル、サードパーティの統合サポート、および話者の識別を含みます。
ASRは、Amazon Alexa、OK Google、Cortana、または顧客などの音声テクノロジーが、「ロサンゼルスの天気はどうですか?」というプロンプトが表示されたときに応答できるようにする最初のステップです。これは、話された音を検出し、それらを単語として認識し、特定の言語の音と照合し、最終的に私たちが言う単語を識別する重要な部分です。 ASRエンジンのおかげで、会話は自然に感じられます。また、最新のテクノロジーでは、ほとんどのASRエンジンがクラウドコンピューティングを利用しています。 NLUのような追加のテクノロジーにより、人間とコンピューターの間の会話はよりスマートで複雑になっています。
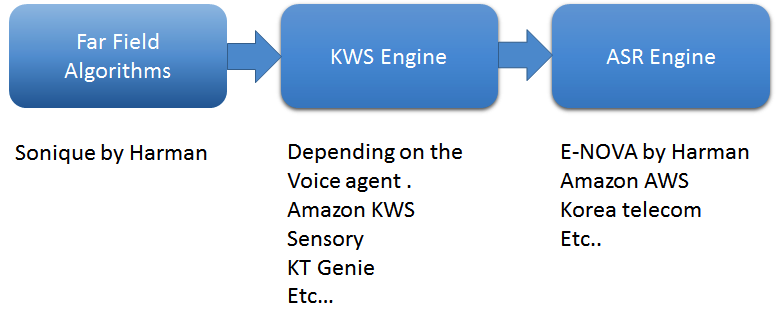
図1:音声エージェントの基本的な処理パイプライン。 (出典:Harman Embedded Audio)
ただし、カスタム音声エージェントの構築には、多くの固有の課題があります。製品の環境を理解することは、プロセスの重要な課題の1つであり、各アプリケーションは特定のユースケースに基づいて異なります。たとえば、家で料理をしていると想像してみてください。手が忙しくていっぱいです。水を沸騰させるときは、配管スペースに接続されている音声エージェントに「水をx度に沸騰させて」とすばやくリクエストするだけです。ここでの課題は、デバイスがあなたの言ったことを聞くことができるかどうか、そしてクリーンな信号を取得してあなたを正しく聞くためにデバイスがキャンセルするノイズの量です。これを確実にするには、音声アルゴリズムを敵対的な環境に合わせて調整する必要があり、マイクの位置を調整して音を拾うことができるようにする必要があります。また、マイクのSNRを高くするには、低THDスピーカーを使用する必要があります。これにより、ASRエンジンに可能な限り明瞭な音声が届き、質問に対する正しい答えが得られます。
さらに、クルーズ船に乗っていることを想像してみてください。周囲の騒音は、居間や台所で聞こえる騒音とはまったく異なります。最大の課題は、これらのノイズを抑制し、正確な応答のためにシステムにクリーンなオーディオ信号を送るためのアルゴリズムをトレーニングすることです。適切に実装されたMSCクルーズ用に開発したような仮想パーソナルクルーズアシスタントシステムは、図2に示す手順を確実に完了することができます。
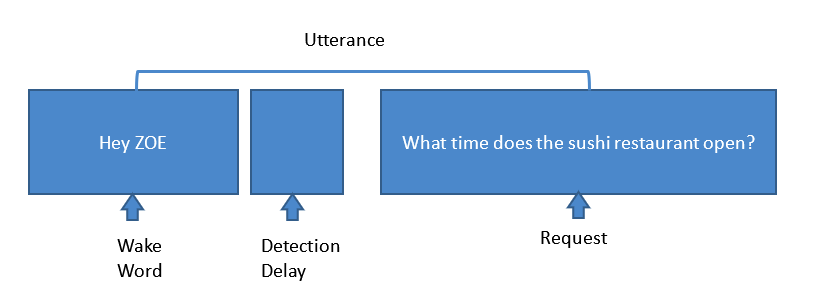
図2:一般的な音声アシスタントのリクエストに関連する手順。 (出典:Harman Embedded Audio)
ここでは、客室の音声アシスタントユニットが「HeyZoe」のウェイクワードを検出します。次に、KWSがキーワードを検出すると、ノイズ抑制アルゴリズムに基づいてマイク全体がエネルギーをソースに向け、ACノイズ、TV、無相関ノイズ、プロペラとエンジンノイズ、風切り音、AECなどの周囲のノイズをキャンセルします。など。Soniqueアルゴリズムは、これらのノイズをすべてキャンセルし、システムに可能な限りクリーンな信号を送信するように調整されています。次に、システムが要求を受け取ると、ASRエンジンはこの音声をテキストに変換します。次に、NLUエンジンは、このテキストを生データに変換して答えを取得します。しかし、まだ終わっていません。探している答えを得るために、知識スキルが要求に対する答えを提供し、ASRエンジンがそのデータテキストを音声に変換してスピーカーから出力します。
もう1つの課題は、偽陽性率拒否(FRR)を取り巻くことです。スマートスピーカーのパフォーマンスを測定するために使用されるチェックポイントの1つであるWakeWord FRRを達成するプロセスは、時間とコストの両方がかかります。このシステムは、ウェイクワードが検出されるたびに製品が適切にウェイクアップできるかどうかを検証するために使用されます。 FRRを達成するには、訓練されたキーワードが不可欠です。私たちの経験では、トレーニングされたモデルを一流のアルゴリズムと組み合わせることで、開発チームは課題を克服し、可能な限り最高のFRRを達成できます。ウェイクワード応答は、システムが業界標準に合格していることを確認するために、実験室でさまざまな条件下でさらにテストされます。
独自の音声エージェントを採用する利点
音声エージェントは、ユーザーエクスペリエンスに大きな価値を提供します。音楽は最大で最も単純なユースケースですが、音声エージェントの価値は、Spotifyアカウントをリモートで開くことをはるかに超えています。音声は、物事をオンにしたり、電化製品を操作したり、水を沸騰させたり、蛇口をオンにしたりすることができます。 Voiceは強力であり、エージェントはユーザーについて多くのことを知っています。そのため、企業は独自のデータを入手し、所有し、保存し、保護しようとしています。
音声ソリューションには幅広いアプリケーションがありますが、重要なのは、プラットフォーム間で機能するテクノロジー(Apple、Windows、またはAndroidのスマートスピーカー、ラップトップ、スマートフォンに関連するテクノロジー)を活用し、収集したデータを活用して、常にユーザーのニーズを学習し、記憶しています。独自の音声エージェントを作成すると、この柔軟性のある使用が可能になり、同時にデータが内部に保持されます。
埋め込み