


スタートアップは1000個のRISC-VコアをAIアクセラレータチップにパックします
スタートアップのエネルギー効率の高いチップは、データセンターの推奨モデルを高速化するためのM.2アクセラレータソケットを対象としています。
Hot Chipsカンファレンスに合わせて、スタートアップのエスペラントは今週、これまでで最高のパフォーマンスを発揮する商用RISC-Vチップ(ハイパースケールデータセンター向けに設計された1000コアのAIアクセラレータ)を備えたステルスモードから抜け出しました。チップは10〜60 Wのさまざまな電圧および電力プロファイルで実行できますが、その「スイートスポット」は、チップあたり20 Wの電力であり、6つのチップをGlacierPointアクセラレータカードにマウントして維持できる構成です。 120W未満の総消費量。6つのチップからの総性能は約800TOPSです。
エスペラントのET-SoC-1は、これまでで最も多くのRISC-Vコアをシングルチップ上に構築したものとして請求されています:1,093。この数には、エネルギー効率の高いAI加速エンジンとして機能する1,088個のET-MinionカスタムRISC-Vコアが含まれています。 4つのET-MaxionRISC-VコアとRISC-Vサービスプロセッサも含まれています。全体の設計はエネルギー効率に向けられています。
ホットチップの前に、 EE Times エスペラントの創設者兼会長である業界のベテラン、デイブ・ディッツェルと話をしました。 (Ditzelの資格には、1980年に発行された独創的な論文「TheCase for the Reduced Instruction SetComputer」のDavidPattersonとの共著が含まれます。)

Dave Ditzel(出典:エスペラント)
「私たちは、1000個のRISC-Vコアを1つのチップに搭載した最初の製品です」とDitzel氏は述べています。 「人々は何年もの間メニーコアCPUについて話してきましたが、私たちはそれをあまり見ていません。そこにあるRISC-Vのもののほとんどは組み込み用です。
「 『RISC-Vがハイエンドで実行できることを示しましょう...実際に熟練したCPU設計者がここで実行できることを示します。』
お客様の要件
DitzelのCPU設計者チームは、ハイパースケールのデータセンターオペレーターから要件について詳細を引き出すことができました。
「彼らはトレーニングチップを望んでいませんでした。トレーニングに問題はありません」とDitzel氏は述べています。 AIトレーニングはオフラインの問題であることが多く、ハイパースケーラーのx86CPU容量が常にピーク負荷になるとは限りません。したがって、その容量は、利用可能な場合はトレーニングに使用できます。 「彼らの本当の問題は推論です」とDitzelは付け加えました。 「それが彼らの広告を推進するものです。 10ミリ秒以内に回答が必要です。」
したがって、オンライン広告の推奨推論エンジンを高速化することが、データセンターチップの焦点となりました。このタイプのモデルを加速するためのハイパースケーラーの要件はかなり明確でした。
「私たちの顧客は、100メガバイトのメモリをオンチップで望んでいました。推論でやりたいことはすべて100メガバイトに収まります」と彼は言いました。顧客は、オフチップメモリ用の外部インターフェイスも望んでいました。 「本当の問題は、アクセルカードをどれだけ保持できるかです」とディッツェルは説明しました。 「カードは、チップではなく、コンピューティングの単位と考えてください。カードにメモリを搭載できるようになると、PCIeバスを経由してホストに到達するよりもはるかに高速にアクセスできます。」
クリックしてフルサイズの画像を表示

エスペラントは、グレイシャーポイントのアクセラレータカードに、それぞれ1つのチップを備えた6枚のデュアルM.2カードを取り付けます。 (出典:エスペラント)
オンチップメモリシステムには、L1、L2、およびL3キャッシュと、合計100MBをわずかに超えるレジスタファイルを備えたフルメインメモリシステムがあります。オンカードメモリシステムは、モデル内のほとんどのウェイトとアクティベーションを約100GBで保持できます。
レコメンデーションモデルは、高速化が難しいことで有名です。これが、既存のCPUサーバーで実行されている理由の1つです。
「1億人の顧客と彼らが最近購入したものから選ぶとき、あなたはこれにアクセスしなければなりません…カード上のメモリ、そしてあなたはあらゆる種類のランダムメモリアクセスをしているので、キャッシュはしません仕事。本当にもっとクラシックなコンピューターが必要だ」とディッツェル氏は語った。 「x86サーバーは大量のメモリを処理し、プリフェッチを備えています。汎用CPUはそのワークロードを非常にうまく処理します。そのため、どのアクセラレーターもレコメンデーションビジネスに参入するのは困難でした。」
また、FP16およびFP32データ型とともにINT8のサポートも必要です。浮動小数点演算の要件は、可能な限り最高の予測精度を維持する必要性と、低精度の演算のためにプログラムを移植または書き換える傾向がないことの両方に起因します。 Ditzel氏によると、主要なx86サーバーチップメーカーは、サーバーCPUに8ビットのベクトル拡張機能を最近追加したばかりです。
「100万台のx86サーバーで[ハイパースケールデータセンター]で行われている推論のほとんどは、依然として32ビット浮動小数点です」と彼は言いました。
デュアルM.2カード上のEsperantoのチップは、既存のx86CPUサーバーインフラストラクチャ内のアクセラレータスロットに収まるように設計されています。その結果、電力制限は120 Wになり、空冷が必要になります。
Ditzel氏は、エスペラントの設計は、GoogleTPUやAmazonWebServicesのInferentiaなどの社内の取り組みと直接競合しないと述べました。ハイパースケーラーは、「コミュニティ全体にアクセラレータチップを構築させようとしています。これらの企業の多くは、オープンコンピュートと[オープンコンピュートプロジェクト]を信じています。」したがって、「彼らはOCPサーバーを購入し、標準化されたものをそこに入れたいと考えています。競争がある場合、彼らはそれを気に入っています…彼らは競争を奨励し、人々に何が可能かを示しようとしています。」
それでも、このスタートアップは、ビッグデータセンターのオペレーターが加速器チップの外部サプライヤーを必要としていると主張しています。 「それでも、常に意思決定と購入の決定です。」たとえば、あるエスペラントの顧客は、別の部門で使用されている社内で開発されたチップにアクセスできませんでした。 「彼らが持っているものを打ち負かすなら、これらの会社のいずれかに参入することが可能です。」
新しいアプローチ
エスペラントは、競合他社の巨大な電力を消費するチップアクセラレータに対して反対のアプローチを取り、複数で使用できる低電力チップを提供しています。このアプローチは、高価なHBMに頼ることなく、より多くのピンをメモリI / Oに使用できるため、メモリ帯域幅の要件に対応します。
エスペラントのハードウェアも汎用コンピューターとして設計されています。 Ditzel氏によると、推奨モデルに重点を置いているにもかかわらず、このチップは並列処理を高速化できます。 6チップアクセラレータカードには約6,000のパラレルコアが含まれており、各コアは2つのスレッドを実行でき、「任意の問題でスローされる」可能性があります。
エスペラントの袖のもう1つのトリックは、積極的なエネルギー効率の高い設計です。お客様の要件により、電力バジェットは合計120 Wに設定されましたが、Glacier Pointカードで確立された最大スペースは6チップ、つまりチップあたり20Wでした。比較すると、AI推論アクセラレータはその10倍以上の量で動作します。
エスペラントはいくつかの角度からこの問題に取り組んだ。クロック周波数は約1GHzの最適レベルに下げられました。供給電圧は、SRAMの限界を超えて約0.4Vに低下しました。スイッチング容量は、トランジスタの数を減らすために、商業的に実行可能な最小の命令セットを備えたリーンRISC-Vコアを使用することによって支援されました。高度でありながら安定したプロセス技術であるTSMC7nmが選択されました。
クリックしてフルサイズの画像を表示
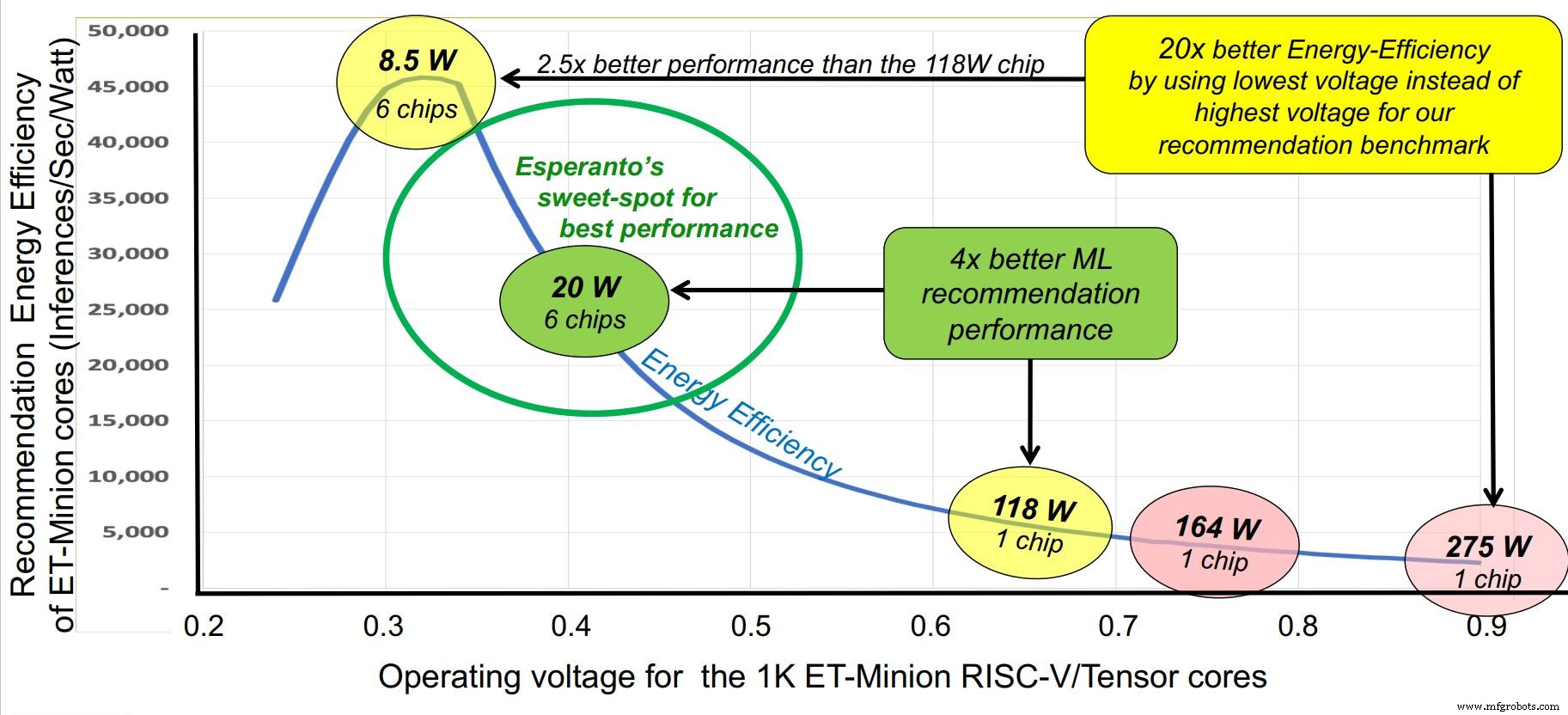
エスペラントは、約1GHzで動作するための「スイートスポット」を特定しました。 (出典:エスペラント)
コアデザイン
エスペラントのチップには、AIワークロードを処理する1,088個のET-Minionコアが含まれています。コアは64ビットのインオーダーRISC-Vプロセッサであり、エスペラント独自のAI最適化ベクトルおよびテンソルユニットがチップ領域の大部分を占めています。浮動小数点MACが構成を支配します。異常なことに、整数MACの処理幅は浮動小数点の2倍です(顧客の要件によると、Ditzel氏は述べています)。また、深層学習モデルで一般的なシグモイド関数などのベクトル超越命令もサポートされています。コアは単一の低電圧ドメインで実行されるため、堅牢なパフォーマンスを確保するために、小さなL1キャッシュでSRAMとともにより多くのトランジスタが使用されました。
クリックしてフルサイズの画像を表示
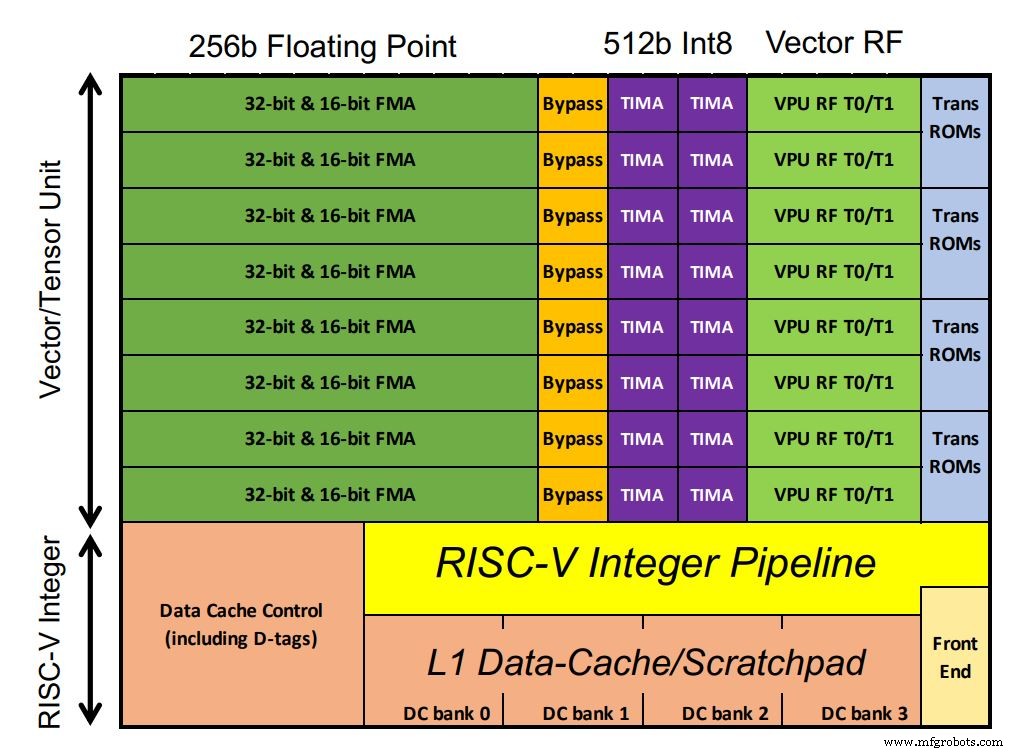
エスペラントのチップには1,088個のET-Minionコアが含まれています(画像をクリックすると拡大します)(出典:エスペラント)
各コアは、GHzあたり128GOPSに対応しています。カスタムマルチサイクルテンソル命令は、512ビット幅全体を使用して最大512サイクルを引き継ぎ、実行する別のコントローラーで大規模な行列乗算を実行します。これにより、コントローラーが次のRISC-V命令をフェッチする前に、単一のテンソル命令で64,000を超える算術演算を実行できます。ワークロードの大部分がテンソル命令を使用するため、これにより命令帯域幅が減少します。したがって、512クロックサイクルごとに1つの命令のみが必要です。
8つのET-Minionコアは「近隣」を構成し、変更された命令はそれらの物理的な近接性を利用します。 「協調ロード」と呼ばれる別の機能により、コアはキャッシュフェッチなしで相互に直接データを転送できます。その構成は電力を節約します。 8つのコアは、エネルギー効率のために大きなL2キャッシュも共有しています。
もう一度ズームアウトすると、4つの8コアの近傍が「ミニオンシャイア」を構成し、各チップに34のシャイア、合計1,088のコアがあります。 (歩留まりを改善するために1,024コアのみで計算することも可能です、とDitzelは言いました)。 4つのET-Maxionコアは、それぞれがArm A-72とほぼ同等のパフォーマンスを備えており、現在のアクセラレータ構成ではなく、将来のスタンドアロン操作を目的としています。
しきい値電圧の変動は、個々の電圧を微調整できるように、各Shireに独自の電圧供給を提供することで軽減されます。
メモリシステム
各チップには4つの64ビットDDRインターフェイスがあり、実際には、各インターフェイスは4つの16ビットチャネルを表し、合計96x16ビットチャネルになります。このデザインは、スマートフォン用の低電力メモリとして開発されたLPDDR4xを使用しています。ビットあたりのエネルギーはHBMとほぼ同等ですが、6チップアクセラレータカードのメモリインターフェイス全体で合計を1,536ビットに維持すると、合計メモリ帯域幅が大きくなります。
エスペラントはそのチップをデュアルソケットM.2カードにマウントしました。 6つはOCPGlacier Point v2アクセラレータカードに適合します(前面に3つ、背面に3つ)。これにより、1GHzで動作するチップで約800のTOPSが提供されます。また、ロープロファイル(ハーフハイト、ハーフレングス)PCIeカードにマウントして、各チップの電力バジェットを約60Wに増やすこともできます。チップはアプリケーションに応じて300MHz〜2GHzで動作できます。
ハードウェアエミュレーションの結果に基づいて、Ditzelは、GlacierPointカード上の6つのエスペラントチップが競合他社をしのぐことができると主張しました。低電圧設計に重点を置いた結果、メモリシステムの設計とワットあたりのパフォーマンスの数値を考慮した場合、スタートアップの利点は推奨ベンチマークで顕著になります。
将来のバージョンには、エッジアプリケーション用の縮小バージョンのET-SoC-1が含まれる可能性があります。 Ditzelは、現在のバージョンは「今後数か月」でリリースされるはずだと述べました。
>>この記事は、もともと姉妹サイトEEで公開されました。タイムズ。
>
関連コンテンツ:
- AI対応のSoCは複数のビデオストリームを処理します
- ザイリンクスは、「コンポーザブル」ハードウェアを使用してデータセンターのオフロードをターゲットにしています
- NNA機能カバレッジのためのオペレーションセットコンピューティング(ROSC)の削減
- ハイブリッドアーキテクチャはAI、ビジョンワークロードを高速化します
- ハードウェアアクセラレータはAIアプリケーションに対応します
Embeddedの詳細については、Embeddedの週刊メールニュースレターを購読してください。
埋め込み