


データのパックおよびアンパックのためのC言語の共用体
C言語の共用体を使用したデータのパックとアンパックについて学習します。
C言語の共用体を使用したデータのパックとアンパックについて学習します。
前回の記事では、ユニオンの元々のアプリケーションは、相互に排他的な変数用の共有メモリ領域を作成していたことを説明しました。ただし、時間の経過とともに、プログラマーは完全に異なるアプリケーションにユニオンを広く使用してきました。つまり、大きなデータオブジェクトからデータの小さな部分を抽出することです。この記事では、この特定の組合の適用について詳しく見ていきます。
データのパック/アンパックにユニオンを使用する
ユニオンのメンバーは、共有メモリ領域に格納されます。これは、組合向けの興味深いアプリケーションを見つけるための重要な機能です。
以下のユニオンについて考えてみましょう:
union {uint16_t word; struct {uint8_t byte1; uint8_t byte2; };} u1; このユニオン内には2つのメンバーがあります。最初のメンバーである「word」は2バイトの変数です。 2番目のメンバーは、2つの1バイト変数の構造です。ユニオンに割り当てられた2バイトは、その2つのメンバー間で共有されます。
割り当てられるメモリスペースは、下の図1に示すようになります。
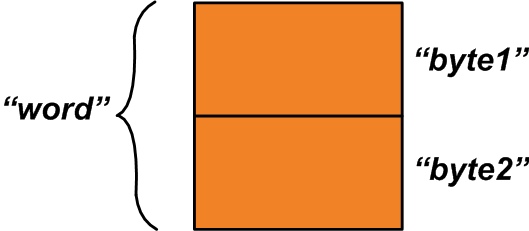
図1
「word」変数は割り当てられたメモリスペース全体を参照しますが、「byte1」および「byte2」変数は「word」変数を構成する1バイト領域を参照します。この機能をどのように使用できますか? 2つの1バイト変数「x」と「y」があり、これらを組み合わせて1つの2バイト変数を生成するとします。
この場合、上記の和集合を使用して、次のように構造体メンバーに「x」と「y」を割り当てることができます。
u1.byte1 =y; u1.byte2 =x; これで、ユニオンの「word」メンバーを読み取って、「x」変数と「y」変数で構成される2バイトの変数を取得できます(図2を参照)。
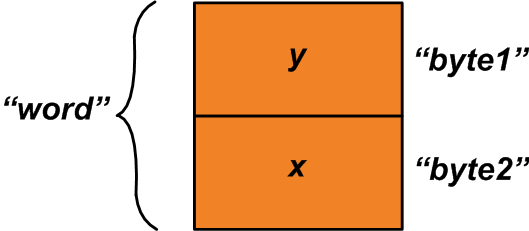
図2
上記の例は、2つの1バイト変数を1つの2バイト変数にパックするための共用体の使用を示しています。逆のこともできます。2バイトの値を「word」に書き込み、「x」変数と「y」変数を読み取って2つの1バイト変数に解凍します。ユニオンの1つのメンバーに値を書き込み、そのメンバーの別のメンバーを読み取ることは、「データしゃれ」と呼ばれることもあります。
プロセッサのエンディアン
データのパック/アンパックにユニオンを使用する場合、プロセッサのエンディアンに注意する必要があります。エンディアンに関するRobertKeimの記事で説明されているように、この用語は、データオブジェクトのバイトがメモリに格納される順序を指定します。プロセッサは、リトルエンディアンまたはビッグエンディアンにすることができます。ビッグエンディアンプロセッサでは、最上位ビットを含むバイトのメモリアドレスが最小になるようにデータが格納されます。リトルエンディアンシステムでは、最下位ビットを含むバイトが最初に格納されます。
図3に示されている例は、シーケンス0x01020304のリトルエンディアンとビッグエンディアンのストレージを示しています。
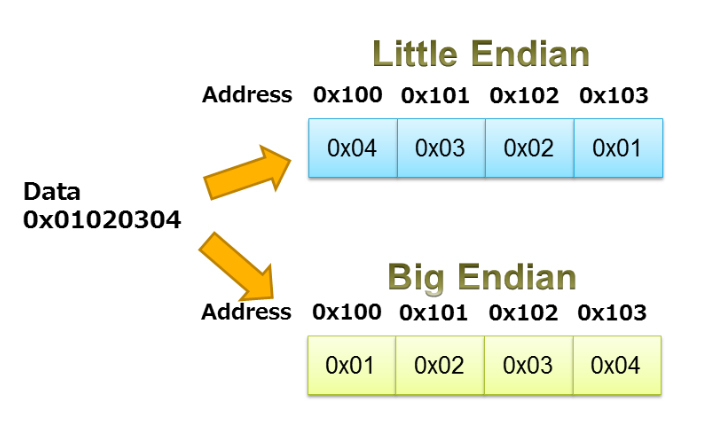
図3。 画像提供:IAR。
次のコードを使用して、前のセクションの結合を試してみましょう。
#include&ltstdio.h&gt#include&ltstdint.h&gtint main(){union {struct {uint8_t byte1; uint8_t byte2; }; uint16_tワード; } u1; u1.byte1 =0x21; u1.byte2 =0x43; printf( "Word is:%#X"、u1.word); return 0;} このコードを実行すると、次の出力が得られます:
単語は:0X4321
これは、共有メモリスペースの最初のバイト(「u1.byte1」)が「word」変数の最下位バイト(0X21)を格納するために使用されることを示しています。つまり、コードの実行に使用しているプロセッサはリトルエンディアンです。
ご覧のとおり、この特定のユニオンのアプリケーションは、実装に依存する動作を示す可能性があります。ただし、このような低レベルのコーディングでは、通常、プロセッサのエンディアンがわかっているため、これは深刻な問題にはなりません。これらの詳細がわからない場合は、上記のコードを使用して、データがメモリ内でどのように編成されているかを確認できます。
代替ソリューション
共用体を使用する代わりに、ビット演算子を使用してデータのパックまたはアンパックを実行することもできます。たとえば、次のコードを使用して、2つの1バイト変数「byte3」と「byte4」を組み合わせ、単一の2バイト変数(「word2」)を生成できます。
word2 =(((uint16_t)byte3)<<8)| ((uint16_t)byte4); リトルエンディアンとビッグエンディアンの場合のこれら2つのソリューションの出力を比較してみましょう。以下のコードを検討してください:
#include&ltstdio.h&gt#include&ltstdint.h&gtint main(){union {struct {uint8_t byte1; uint8_t byte2; }; uint16_t word1; } u1; u1.byte1 =0x21; u1.byte2 =0x43; printf( "Word1 is:%#X \ n"、u1.word1); uint8_t byte3、byte4; uint16_t word2; byte3 =0x21; byte4 =0x43; word2 =(((uint16_t)byte3)<<8)| ((uint16_t)byte4); printf( "Word2 is:%#X \ n"、word2); 0を返す;} このコードを TMS470MF03107 などのビッグエンディアンプロセッサ用にコンパイルすると、 、出力は次のようになります:
Word1は次のとおりです: 0X2143
Word2は次のとおりです: 0X2143
ただし、 STM32F407IE などのリトルエンディアンプロセッサ用にコンパイルすると 、出力は次のようになります:
Word1は次のとおりです: 0X4321
Word2は次のとおりです: 0X2143
ユニオンベースの方法はハードウェアに依存する動作を示しますが、シフト操作に基づく方法では、プロセッサのエンディアンに関係なく同じ結果が得られます。これは、後者のアプローチでは、変数の名前( "word2")に値を割り当て、コンパイラがデバイスで使用されるメモリ構成を処理するためです。ただし、ユニオンベースの方法では、「word1」変数を構成するバイトの値を変更しています。
ユニオンベースの方法はハードウェアに依存する動作を示しますが、読みやすく、保守しやすいという利点があります。そのため、多くのプログラマーはこのアプリケーションにユニオンを使用することを好みます。
「データしゃれ」の実際的な例
一般的なシリアル通信プロトコルを使用する場合、データのパックまたはアンパックを実行する必要がある場合があります。各通信シーケンス中に1バイトのデータを送受信するシリアル通信プロトコルについて考えてみます。 1バイトの長さの変数を使用している限り、データを転送するのは簡単ですが、通信リンクを経由する必要がある任意のサイズの構造がある場合はどうでしょうか。この場合、データオブジェクトを1バイト長の変数の配列として何らかの形で表現する必要があります。このバイト配列表現を取得したら、通信リンクを介してバイトを転送できます。次に、レシーバー側で、それらを適切にパックして、元の構造を再構築できます。
たとえば、UART通信を介してfloat変数「f1」を送信する必要があるとします。 float変数は通常4バイトを占めます。したがって、次のユニオンを「f1」の4バイトを抽出するためのバッファとして使用できます。
union {float f; struct {uint8_t byte [4]; };} u1; トランスミッタは、変数「f1」をユニオンのフロートメンバーに書き込みます。次に、「バイト」配列を読み取り、通信リンクにバイトを送信します。受信者は逆のことを行います。受信したデータを自身のユニオンの「バイト」配列に書き込み、ユニオンのfloat変数を受信値として読み取ります。この手法を実行して、任意のサイズのデータオブジェクトを転送できます。次のコードは、この手法を検証するための簡単なテストです。
#include&ltstdio.h&gt#include&ltstdint.h&gtint main(){float f1 =5.5;ユニオンバッファ{floatf; struct {uint8_t byte [4]; }; };ユニオンバッファbuff_Tx;ユニオンバッファbuff_Rx; buff_Tx.f =f1; buff_Rx.byte [0] =buff_Tx.byte [0]; buff_Rx.byte [1] =buff_Tx.byte [1]; buff_Rx.byte [2] =buff_Tx .byte [2]; buff_Rx.byte [3] =buff_Tx.byte [3]; printf( "受信したデータは次のとおりです:%f"、buff_Rx.f); 0を返す;} 以下の図4は、説明した手法を視覚化したものです。バイトは順番に転送されることに注意してください。
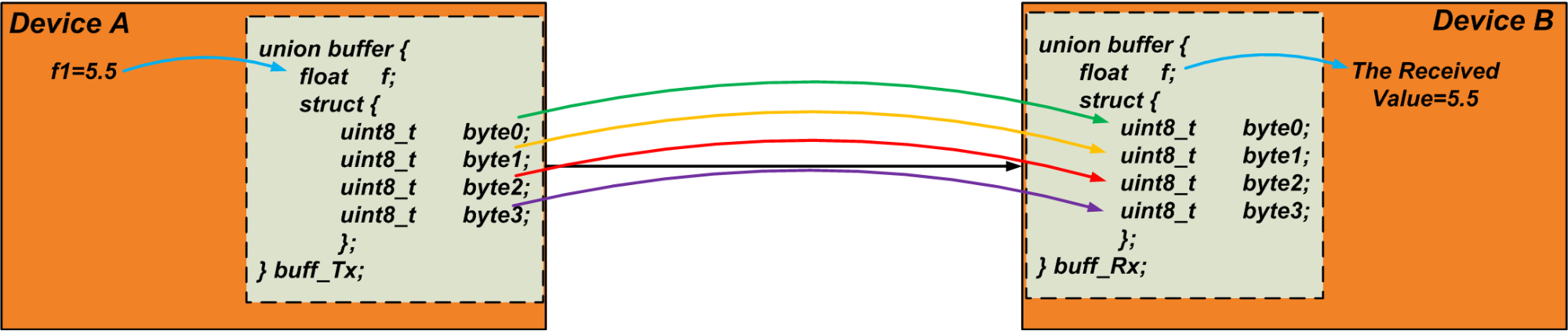
図4
結論
ユニオンの元のアプリケーションは相互に排他的な変数用の共有メモリ領域を作成していましたが、時間の経過とともに、プログラマーはデータのパック/アンパックにユニオンを使用するというまったく異なるアプリケーションにユニオンを広く使用してきました。ユニオンのこの特定のアプリケーションには、ユニオンの1つのメンバーに値を書き込み、その別のメンバーを読み取ることが含まれます。
「データのしゃれ」またはデータのパック/アンパックにユニオンを使用すると、ハードウェアに依存する動作が発生する可能性があります。ただし、読みやすく、保守しやすいという利点があります。そのため、多くのプログラマーはこのアプリケーションにユニオンを使用することを好みます。 「データのしゃれ」は、シリアル通信リンクを経由する必要のある任意のサイズのデータオブジェクトがある場合に特に役立ちます。
私の記事の完全なリストを表示するには、このページにアクセスしてください。
埋め込み
- CyrusOneのユーザーと顧客のアプリケーションパフォーマンスを向上させる
- セマフォ:ユーティリティサービスとデータ構造
- 状態ベースのメンテナンスのための陸軍の戦略とソリューション
- IIoTおよびデータ分析ソリューションをEHSに適応させることの利点
- 責任ある信頼できるAIの構築
- フォグコンピューティングとは何ですか?それはIoTにとって何を意味しますか?
- C - 組合
- データとコンテキストがサプライチェーンの可視性に不可欠である理由
- フリート管理の場合、AIとIoTは一緒に優れています
- インダストリーAIoT:インダストリー4.0向けの人工知能とIoTの組み合わせ
- スマートマニュファクチャリングのためのLitmusおよびOdenヒューズIIoTソリューション