


データが信頼性の基盤である理由
 今日のテクノロジーの時代では、データが意思決定の鍵となります。この専門分野は「データサイエンス」として知られています。企業は、データを収集、分析、利用して情報に基づいた意思決定を行うことで、テクノロジーを活用できます。
今日のテクノロジーの時代では、データが意思決定の鍵となります。この専門分野は「データサイエンス」として知られています。企業は、データを収集、分析、利用して情報に基づいた意思決定を行うことで、テクノロジーを活用できます。
ある研究グループは、現在のデータの増加率では、2025年までにデータのサイズは163ゼタバイトになると予測しています。この数をよりよく理解するために、1ゼタバイトが1兆ギガバイトに等しいと考えてください。これにより、データの保存、品質、管理について疑問が生じます。
この記事では、有意義な信頼性調査を実施する上でのデータの重要性とその使用法について説明します。信頼性の一般的な定義は、特定の動作条件下で、機器、システム、または施設が特定の期間、障害なく動作する確率です。したがって、信頼性分析には、正確な履歴障害データとその適切な分析が不可欠です。
データ分析は、膨大な量のデータを調査し、より良い意思決定をサポートできる有用な情報を抽出する機会を提供します。これは、データに合理的な自信がある場合にのみ可能です。データが不十分だと、意思決定が不十分になる可能性があるためです。
データ分析の利点
信頼性分析は、管理者とエンジニアが技術的および財務的な意思決定を行うのに役立つ効果的な方法です。特に、データ分析は、プロジェクト設計の最適化、コストの削減、コンポーネントの寿命の予測、障害の調査、保証間隔の評価、効果的な検査期間の実装、および主要業績評価指標(KPI)の決定に役立ちます。包括的な信頼性調査を実施するには、正確なデータが不可欠です。
データのフィルタリングと収集は、信頼性エンジニアの重要な責任です。データ収集は、関心のある変数に関する情報を収集および評価して、特定の調査質問に回答し、仮説を評価し、結果を推定およびサポートするための体系的なモデルを確立する方法です。
したがって、データ収集はすべての研究に共通のフェーズです。正確で正直なデータ収集を保証することは、これらの研究の共通の要因であり、同じ目的です。
信頼性分析の全体的な結果を歪める可能性のある外れ値を排除するなど、データをより正確で信頼性の高い方法で処理するために、多くのツールと手法を利用できます。
堅牢なデータの確立
どの運用施設でも、資産の保守と障害の記録、運用ウィンドウなどを含む正確で信頼性の高いデータは、信頼性工学研究の基盤を提供できます。残念ながら、すべての企業がデータの収集と管理に必要なシステム、プロセス、文化を持っているわけではありません。
堅牢なデータベースを確立するための1つの要件は、すべての意味のあるデータポイントが収集および保存されるようにすることです。一部の重要なデータのみを収集するデータベースは、現在の運用と資産の状態について、不完全で、おそらく誤解を招く可能性さえある画像を提供する可能性があります。
評価された信頼できるデータを収集するための方法である検証済みのツールを利用することは、有用な実践となる可能性があります。たとえば、フィンランドの大企業は、クローズドメンテナンスレポートの約6分の1(17.2%)に障害モードが含まれていないと報告しました。
また、クローズドメンテナンスレポートには、スペアパーツの数と種類が記録されていませんでした。これらの観察結果は、この特定の会社のデータベースが限られていることを示唆しており、障害の場所やその影響などの重要な情報が欠落しているため、機器の障害とメンテナンス履歴に関する狭い視点しか提供しません。
効果的なデータ分析の追加要件は、データのタイムリーなレポートです。調査結果を毎週または毎月報告する保守部門は、データを継続的に統合する動的システムを展開する組織よりも、重要なデータとアクティビティを失う可能性が高くなります。
もう1つのベストプラクティスは、データ収集およびストレージシステムが、高品質のデータインスタンスおよび値と見なされるものを定義し、可能な限り自動化して、レポートとデータベースの検索機能の一貫性を促進することです。オープンテキストフィールドに依存するメンテナンスレポートシステムは、基本的にデータ分析を手動プロセスに変換します。
オープンテキストフィールドは、適切に設計されたデータベースに配置されますが、詳細と説明を提供するために使用する必要があります。
代わりに、データ収集およびストレージシステムは、説明とレポートの一貫性を確保するために、可能な限り多くのドロップダウンメニューを利用して、意味のあるデータポイントごとに個別のセルを用意する必要があります。信頼性エンジニアは、データが検索可能であり、システム全体で一貫して記述されている場合にのみ、広範な信頼性調査を実行できます。
データベースから必要なレポートと分析のタイプを定義すると、含めるデータフィールドが決まります。したがって、高品質のデータを取得するための最初のステップは、回答する質問を定義し、収集したデータがその目的に適していることを確認することです。
信頼性の研究のために、データベースシステムの分野では、スペアパーツ、故障モード、工数、主要な検査結果、損傷したコンポーネント、および日常業務に関する保守情報を収集する必要があります。さらに、包括的なドロップダウンメニューを使用してこれらのフィールドのレポートの一貫性を制御することで、ソフトウェアアプリケーションは、平均故障間隔(MTBF)、可用性、その他の信頼性KPIの計算などの主要な機能を実行できるようになります。
データ品質要因
ツールとテクノロジー
重複を減らし、プラットフォーム間およびプラットフォーム間でデータを統合および移行し、データ分析を実行するためのツールなど、データ品質の目標を達成するために無数のツールを利用できます。
データ分析ツールを使用すると、データを組み合わせて分類し、傾向やパターンを明らかにするなど、データから意味を抽出できます。現在、多くのテクノロジーがモバイル対応になっています。これらのテクノロジーは、データ収集における人的およびシステムエラーを最小限に抑えることができます。これらの新しいツールとテクノロジーの採用は、データ品質の向上に役立ちます。
人とプロセス
保守要員からエンジニアや管理者に至るまで、会社の業務のあらゆるレベルの各従業員は、会社におけるデータの役割についての共通の理解を共有する必要があります。これには、収集されるデータ、データが使用される頻度と目的が含まれます。トレーニングに加えて、信頼性が高く一貫性のあるデータ収集と保存を確実にするために、明確なプロセスを確立する必要があります。
組織文化
管理サポートと企業文化は、データ品質において重要な役割を果たします。管理者に報告されるKPIは、データ品質を監視する必要があります。組織がパフォーマンスの向上、機会の数の増加、または重要な問題への対処のために新しいプロジェクトまたはイニシアチブを立ち上げたい場合、プロセス、職務、組織の構造と種類、テクノロジーの使用などの変更を行う必要があります。 。
手順と作業プロセスを更新し、ベストプラクティスに合わせる必要があります。継続的な改善が成功の原動力になります。データの質と量がこのドライバーの鍵となります。継続的なトレーニングを通じて、データの重要性を担当者間で発展させることができ、組織文化の強化に役立ちます。
信頼性に対するデータの影響
データ品質の重要性を説明するために、次のケーススタディを検討してください。ある施設は、原油安定化装置を備えた新しい軽油分離パッケージ(GOSP)を設置することにより、石油生産を増やすプロジェクトを開始しました。 GOSPは、分離トラップ、ウェット原油処理施設、水油分離器、ガス圧縮施設、フレアシステム、移送/輸送ポンプ、および安定化施設で構成されます。
施設の生産可用性を予測し、それを目標可用性と比較するために、信頼性、可用性、および保守性(RAM)の調査が実施されました。この調査は、本番スループットを制限する領域を特定し、本番ビジネスの目標を達成するために必要な可用性を実現するための対策を推奨し、システム全体の可用性を満たすために採用された運用および保守の哲学を確認し、是正措置または潜在的な設計変更を定義するためにも使用されます。 。
生のメンテナンスデータを表1にまとめています。これは、既存の運用施設のメンテナンスクルーへのインタビューに基づいています。調査のために収集されたデータには、古い資産のメンテナンスデータを誤って比較して新しい施設の運用範囲を決定するなど、多くの分野で問題がありました。
たとえば、表1は、メカニカルシールの問題により、10か月ごとにコンプレッサーが30日間使用できなくなることを示しています。この見積もりでは、コンプレッサーは、メカニカルシールの問題により、寿命の10%をメンテナンスに費やすと想定しています。施設は新しい技術を採用するため、この仮定は正しくありません。さらに、古い施設から学んだ多くの教訓が新しい設計に反映されます。
データから抽出されたもう1つの誤った仮定は、腐食の影響です。生データは、シャフトのピッチングの結果として、コンプレッサーが4年(48か月)ごとに30日間メンテナンスされていることを示唆しているようです。コンプレッサーシャフトにアップグレードされた材料を使用すると、これらのタイプの問題が解消されます。
表1はさらに、振動による平均修理時間(MTTR)が60日であることを示しています。この仮定を、スペアパーツ管理の改善により、わずか4日間の新しいコンプレッサーの平均予想MTTRと比較してください。
この例が示すように、古い機器を備えた老朽化した施設で正確である可能性のあるデータから抽出された仮定は、アップグレードされた材料とより効率的な技術で設計された新しい施設に適用された場合、正確ではありません。
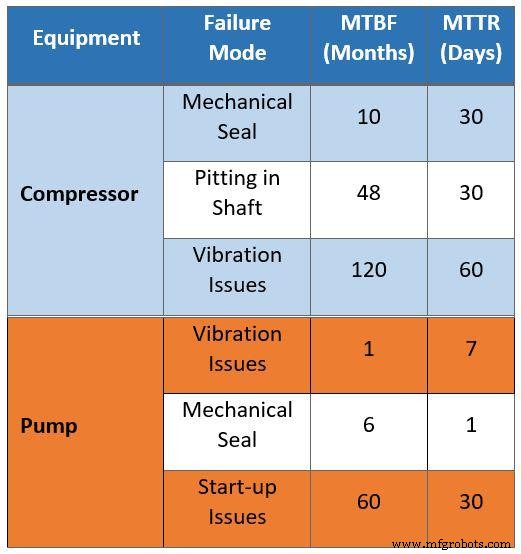
表1.信頼性、可用性、保守性の調査のために収集された生のフィールドデータ
表2は、信頼性エンジニアによって修正された同じデータセットをまとめたものです。エンジニアは、サードパーティベンダーに提供されたものと同じデータにアクセスし、生データをフィルタリングして、プロセス計装によって自動的に修正される可能性のあるすべてのメンテナンスの問題を排除しました。次に、データを保守および運用管理戦略によって分類して、ボトルネック、容量の制限、可用性などの設計上の欠陥に関連する問題を特定しました。
修正されたデータを新しい施設に適用し、設計の最適化を決定するために使用できます。たとえば、ガスコンプレッサーの故障モードは、ドライシールと3日間のMTTRにより、現在8年のMTBFを示しています。また、シャフトコンプレッサーの腐食の仮定は、新しい施設設計のアップグレードされた材料によって排除されました。
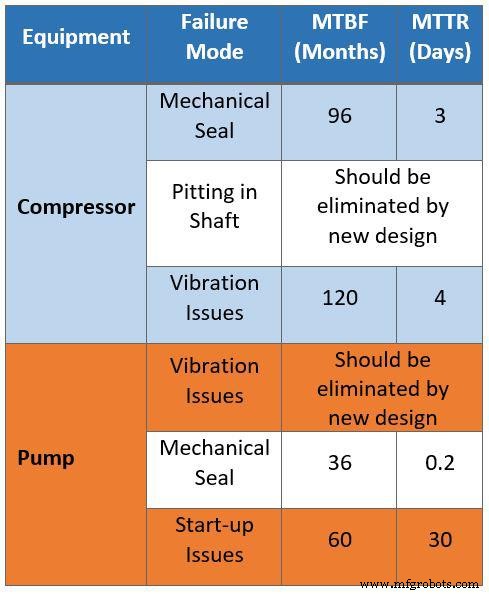
表2.信頼性、可用性、保守性の調査のために収集されたフィルタリングされたデータ
両方の設計の可用性と容量を図1に示します。これは、提供されたデータセットに基づく2つのモデル間の結果の違い、および可用性と容量の結果の違いを示しています。元のデータでは、MTTRが長くMTBFが短いため、新しい施設の可用性は77.34%でしたが、修正されたデータセットでは、全体の可用性が99%と計算されました。これは、実際の状況を表しています。
同じプロジェクトで、他の機器についても同様の方法が行われました。プロジェクト管理チーム(PMT)は、可用性が高いため、予備の機器を排除するように指示されました。結果は、システムを完全に利用するための設計構成を最適化するために使用されました。このケーススタディが示すように、修正されたデータを使用すると、不要な機器を排除し、プロジェクトの完了時間を短縮してコストを回避することにより、新しいプロジェクトの資本コストと建設コストに大きな影響を与える可能性があります。
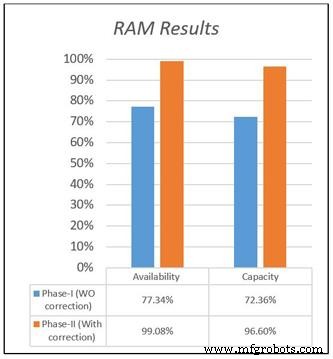
図1.信頼性、可用性、保守性(RAM)の調査結果
図2.入力データ、設計、シミュレーターの結果の関係
信頼性ソフトウェアまたはシミュレーターの意味のある結果は、入力データと設計の品質によって異なります。ことわざにあるように、「ガベージイン、ガベージアウト」。図2は、設計データと入力データの関係とRAMシミュレーションの結果を示しています。入力データに基づいてRAMモデルが構築されると、潜在的な最適化を導入できます。データは、モデルおよびその他の信頼性パフォーマンス測定の重要な要素です。
焦点を絞った信頼性研究についても同じことが言えます。信頼性エンジニアは、運用におけるデータの分析に多くの時間を費やしています。たとえば、エンジニアは、メンテナンスコストが高く、故障率が高いコンポーネント、機器、またはシステムとして定義されている特定の悪役アイテムの信頼性調査を実施する場合があります。
この評価の結果は、限られたリソースを影響の大きいアイテムに集中させるために使用され、メンテナンスコストと可用性の点でフィールド運用に最大のメリットがあります。エンジニアが代表的でないデータを持っているか、十分なデータがない場合、すべての結果と推奨事項が実際の問題に対処するわけではありません。
これは、保守計画、スペアパーツ管理、保守予算、および技術的課題に付加価値を与える機会を失ったことを表しています。したがって、質の高いデータには、組織が下さなければならない意思決定をサポートするために必要なデータの種類と量を明確に識別する効率的なデータ収集システムが必要です。
データ品質を向上させるための3つの重要なステップ
1。適切なデータベースプラットフォームを導入する
組織用に選択されたソリューションは、すべての必須フィールドが完了するまで、メンテナンス通知または作業指示を閉じてはなりません。つまり、選択したプラットフォームは、収集されたデータの一貫性を確保するためにショートカットを無効にする必要があります。
2。既存の機能を包括的なソリューションに統合する
プラットフォームは、すべての信頼性機能を1つのソリューションに組み込んで、データをより適切に統合し、組織に導入されるシステムの数を減らす必要があります。たとえば、スペアパーツが倉庫から取り出された場合、特定の通知に対して課金する必要があります。これには、スペアパーツの管理とメンテナンス作業を同化するプラットフォームが必要になります。
3。データ品質保証プログラムを実装する
展開されたソリューションの品質保証活動には、組織全体のデータ品質の定期的な監査を含める必要があります。たとえば、品質保証チームは、収集されたデータの品質を評価するために、各運用施設の保守通知と作業指示の5%をランダムに監査できます。この評価の結果は、ソリューションの利用率をさらに向上させ、効果的なデータベースを確保するために使用できます。
データは礎石です
完全な資産の保守と修理の履歴データを正しく収集、保存、分析する必要があります。データ収集に関与する保守要員や運用担当者を含む最前線の従業員も、データ品質における彼らの役割の重要性を理解する必要があります。
データはどの企業でも意思決定の基礎であり、データ品質はすべての信頼性研究の中心であることを忘れないでください。高品質のデータがあれば、効果的なアドボカシー、有意義な調査、戦略的計画、および管理の提供に自信を持って利用できます。
著者について
Khalid A. Al-Jabrは、サウジアラムコの信頼性エンジニアリングスペシャリストであり、機器の信頼性と課題に焦点を当てた18年以上の産業経験があります。彼は博士号を取得し、公認技術者であり、エンジニアリング管理とデータ分析の専門家として認定されています。
Qadeer Ahmedは、サウジアラムコのコンサルティング信頼性エンジニアとして働いており、信頼性エンジニアリングで18年の経験があります。公認技術者であり、博士号を取得しています。認定メンテナンス&信頼性プロフェッショナル(CMRP)およびシックスシグマブラックベルトです。
Dahham Al-Anaziは、サウジアラムコのコンサルティングサービス部門の信頼性エンジニアリングリーダーです。彼は25年以上の技術的経験があり、機械工学の博士号を取得しています。
モノのインターネットテクノロジー