


機能安全の異星人の世界のコンパイラ
セクターを超えて、機能安全の世界は開発者に新しい要件を課しています。機能的に安全なコードには、さまざまな原因から生じる可能性のある予期しないイベントから防御するための防御コードを含める必要があります。たとえば、コーディングエラーや宇宙線イベントによるメモリの破損は、コードのロジックに従って「不可能」なコードパスの実行につながる可能性があります。高水準言語、特にCおよびC ++には、コードが準拠する言語仕様で動作が規定されていない驚くべき数の機能が含まれています。この未定義の動作は、機能的に安全なアプリケーションでは受け入れられない、予期しない、潜在的に悲惨な結果につながる可能性があります。これらの理由から、標準では、防御的なコーディングが適用され、コードがテスト可能であり、適切なコードカバレッジを照合できること、およびアプリケーションコードが要件にトレース可能であり、システムがそれらを完全かつ一意に実装することを保証する必要があります。
コードはまた、高レベルのコードカバレッジを達成する必要があり、一部のセクター(特に自動車)では、設計で高度な外部診断、キャリブレーション、および開発ツールが必要になるのが一般的です。発生する問題は、防御的なコーディングや外部データアクセスなどのプラクティスが、コンパイラーが認識する世界の一部ではないということです。たとえば、CもC ++もメモリの破損を考慮に入れていないため、そのような破損がないときにそれから保護するように設計されたコードにアクセスできない限り、コードが最適化されるときに無視される可能性があります。したがって、防御コードを「最適化」しない場合は、構文的および意味的に到達可能である必要があります。
未定義の動作のインスタンスも、驚きを引き起こす可能性があります。それらを単に避けるべきであると示唆するのは簡単ですが、それらを特定することはしばしば困難です。それらが存在する場合、コンパイルされた実行可能コードの動作が開発者の意図と一致するという保証はありません。デバッグツールで使用されるデータへの「バックドア」アクセスは、言語が許容しないさらに別の状況を表しており、予期しない結果をもたらす可能性があります。
コンパイラの最適化は、これらすべての領域に大きな影響を与える可能性があります。これらの領域はいずれもコンパイラベンダーの権限の一部ではないためです。最適化により、「実行不可能性」に関連する場合、つまり、可能な入力値のセットではテストおよび検証できないパス上に存在する場合、明らかに健全な防御コードが排除される可能性があります。さらに驚くべきことに、ユニットテスト中に存在することが示された防御コードは、システム実行可能ファイルが構築されるときに排除される可能性があります。したがって、単体テスト中に防御コードのカバレッジが達成されたからといって、それが完成したシステムに存在することを保証するものではありません。
機能安全のこの奇妙な土地では、コンパイラはその要素から外れている可能性があります。そのため、オブジェクトコード検証(OCV)は、障害に関連する悲惨な結果が生じるシステムのベストプラクティスであり、実際、ベストプラクティスだけで十分なシステムのベストプラクティスです。
コンパイルの前後
機能安全、セキュリティ、およびIEC 61508、ISO 26262、IEC 62304、MISRA C、C ++などのコーディング標準によって支持されている検証と妥当性確認の実践は、要件ベースのテスト中に実行されるアプリケーションソースコードの量を示すことにかなり重点を置いています。
>経験によれば、コードが正しく機能することが示されている場合、現場での失敗の可能性はかなり低くなります。しかし、この称賛に値する取り組みの焦点は(言語に関係なく)高レベルのソースコードにあるため、このようなアプローチは、開発者が正確に再現するオブジェクトコードを作成するコンパイラの機能に大きな信頼を置いています。意図されました。最も重要なアプリケーションでは、その暗黙の仮定を正当化することはできません。
オブジェクトコードの制御とデータフローは、それが派生したソースコードの正確なミラーではないことは避けられません。したがって、すべてのソースコードパスを確実に実行できることを証明しても、オブジェクトコードと同じことを証明することはできません。 。オブジェクトコードとアセンブラの間に1:1の関係があるとすると、ソースコードとアセンブリコードの比較がわかります。図1に示す例を考えてみましょう。ここでは、右側のアセンブラコードが、左側のソースコードから生成されています(最適化が無効になっているTIコンパイラを使用)。

図1:右側のアセンブラコードは左側のソースコードから生成されており、ソースコードとアセンブリコードの比較を示しています。 (出典:LDRA)
後で説明するように、このソースコードをコンパイルすると、結果のアセンブラコードのフローグラフは、ソースのフローグラフとはまったく異なります。これは、CまたはC ++コンパイラが従うルールにより、バイナリが提供された場合に、コードを任意の方法で変更できるためです。 「同じように」動作します。
ほとんどの場合、その原則は完全に受け入れられますが、異常があります。コンパイラの最適化は、基本的に、コードの内部表現に適用される数学的変換です。これらの変換は、仮定が成り立たない場合に「失敗」します。たとえば、コードベースに未定義動作のインスタンスが含まれている場合などです。
航空宇宙産業で使用されているDO-178Cのみが、開発者の意図と実行可能動作の間の危険な不一致の可能性に焦点を当てています。それでも、これらの不一致を検出されないままにする可能性のある回避策の支持者を見つけることは難しくありません。ただし、そのようなアプローチは許されますが、ソースコードとオブジェクトコードの違いが重要なアプリケーションに壊滅的な結果をもたらす可能性があるという事実は変わりません。
開発者の意図と実行可能な動作
ソースコードフローとオブジェクトコードフローの明確な違いにもかかわらず、それらは主要な関心事ではありません。コンパイラは一般的に信頼性の高いアプリケーションであり、他のソフトウェアと同様にバグがある可能性がありますが、コンパイラの実装は一般にその設計要件を満たします。問題は、これらの設計要件が機能的に安全なシステムのニーズを常に反映しているとは限らないことです。
要するに、コンパイラーは、その作成者の目的に機能的に忠実であると見なすことができます。しかし、CLANGコンパイラを使用したコンパイルの結果の例を示す以下の図2に示すように、それは完全に望まれている、または期待されているものではない場合があります。

図2は、CLANGコンパイラを使用したコンパイルを示しています(出典:LDRA)
「エラー」関数への防御的な呼び出しがアセンブラコードで表現されていないことは明らかです。
'state'オブジェクトは、初期化されたとき、および 'S0'と 'S1'の場合にのみ変更されるため、コンパイラーは、 'state'に指定された値が 'S0'と 'S1'のみであると推論できます。破損がないと仮定すると、「state」は他の値を保持しないため、「default」は不要であると結論付けます。実際、コンパイラはまさにその仮定を行います。
コンパイラーは、実際のオブジェクト(13と23)の値は数値コンテキストでは使用されないため、0と1の値を使用して状態を切り替え、排他的論理和を使用して更新することも決定しました。状態値。バイナリは「あたかも」の義務を順守し、コードは高速でコンパクトです。その参照条件の範囲内で、コンパイラーは良い仕事をしました。
この動作は、リンカーメモリマップファイルを使用してオブジェクトに間接的にアクセスする「キャリブレーション」ツール、およびデバッガを介したダイレクトメモリアクセスに影響します。繰り返しになりますが、このような考慮事項はコンパイラの権限の一部ではないため、最適化やコード生成中には考慮されません。
ここで、コードは変更されていないが、図3のように、コンパイラーに提示されるコード内のコンテキストがわずかに変更されているとします。
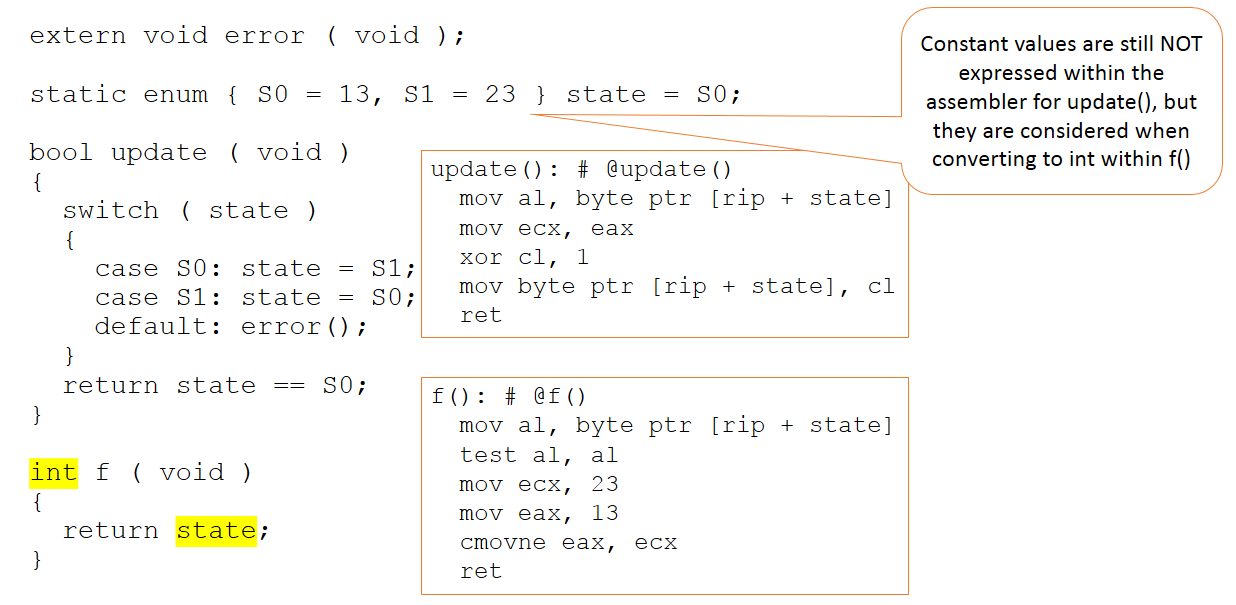
図3:コードは変更されていませんが、コンパイラーに提示されるコードのコンテキストがわずかに変更されています。 (出典:LDRA)
状態変数の値を整数として返す追加の関数が追加されました。今回は、コンパイラに送信されるコードで絶対値13と23が重要になります。それでも、これらの値は更新関数(変更されないまま)内で操作されず、新しい「f」関数内でのみ表示されます。
要するに、コンパイラーは(正しく)13と23の値をどこで使用すべきかについて価値判断を続けます。そして、それらが使用される可能性のあるすべての状況に適用されるわけではありません。
新しい関数を変更して状態変数へのポインターを返すと、アセンブラーコードが大幅に変更されます。ポインタを介したエイリアスアクセスの可能性があるため、コンパイラは状態オブジェクトで何が起こっているかを推測できなくなります。以下の図4に示すように、13と23の値が重要でないと結論付けることはできないため、これらはアセンブラー内で明示的に表現されるようになりました。
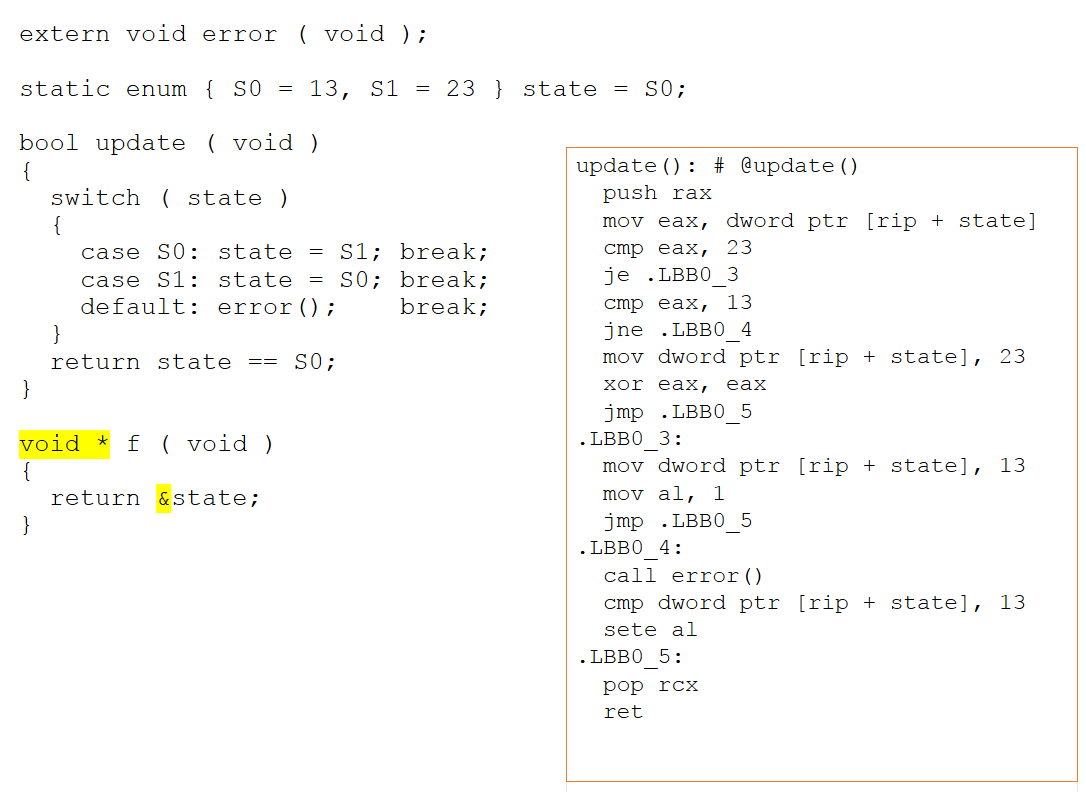
図4:状態変数へのポインターを返すように新しい関数を変更すると、アセンブラーコードが大幅に変更されます。 13と23の値は重要ではないと結論付けることはできないため、これらはアセンブラー内で明示的に表現されるようになりました(出典:LDRA)。
ソースコードの単体テストへの影響
ここで、架空のユニットテストハーネスのコンテキストでの例を考えてみましょう。テスト対象のコードにアクセスするためのハーネスが必要な結果として、状態変数の値が操作され、その結果、デフォルトは「最適化」されません。このようなアプローチは、ソースコードの残りの部分に関連するコンテキストがなく、すべてにアクセスできるようにするために必要なテストツールでは完全に正当化されますが、副作用として、コンパイラによる防御コードの正当な省略を隠すことができます。
コンパイラーは、ポインターを介して任意の値が状態変数に書き込まれていることを認識します。また、13と23の値が重要でないと結論付けることはできません。その結果、それらはアセンブラ内で明示的に表現されるようになりました。この場合、S0とS1が状態変数の唯一の可能な値を表すと結論付けることはできません。これは、デフォルトのパスが実行可能である可能性があることを意味します。図5に示すように、状態変数の操作はその目的を達成し、エラー関数の呼び出しがアセンブラーで明らかになります。

図5:状態変数の操作はその目的を達成し、エラー関数の呼び出しがアセンブラーで明らかになります。 (出典:LDRA)
ただし、この操作は製品内に出荷されるコードには含まれないため、error()の呼び出しは実際には完全なシステムにはありません。
オブジェクトコード検証の重要性
オブジェクトコードの検証がこの難問の解決にどのように役立つかを説明するために、図6に示す最初のサンプルコードスニペットをもう一度検討してください。

図6:これは、オブジェクトコードの検証が、エラーの呼び出しがシステム全体にないことを解決するのにどのように役立つかを示しています。 (出典:LDRA)
このCコードは、1回の呼び出しで100%のソースコードカバレッジを達成することを実証できます。
f_while4(0,3);
コードは、行ごとに1つの操作に再フォーマットされ、フローグラフ上で「基本ブロック」ノードのコレクションとして表されます。各ノードは、一連の直線コードです。基本ブロック間の関係は、ノード間の有向エッジを使用して図7に示されています。
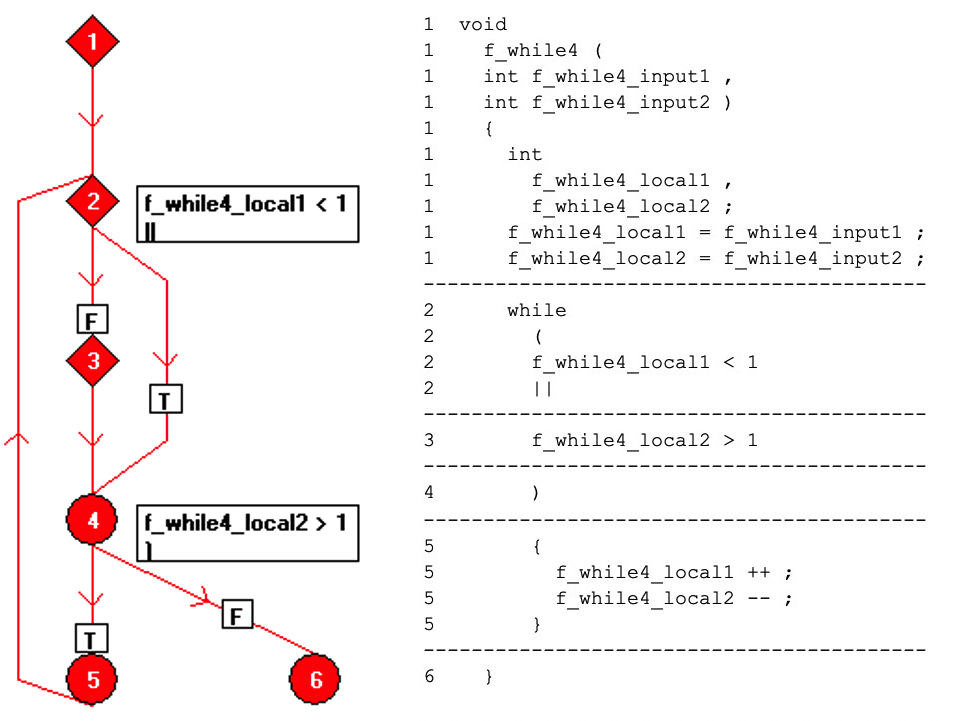
図7:これは、ノード間の有向エッジを使用した基本ブロック間の関係を示しています。 (出典:LDRA)
コードをコンパイルすると、結果は次のようになります(図8)。フローグラフの青い要素は、f_while4(0,3)の呼び出しによって実行されていないコードを表しています。
このメカニズムは、オブジェクトコードとアセンブラコードの1対1の関係を活用することで、オブジェクトコードのどの部分が実行されていないかを明らかにし、テスターに追加のテストを考案して完全なアセンブラコードカバレッジを実現するよう促します。したがって、オブジェクトコードの検証を実現します。
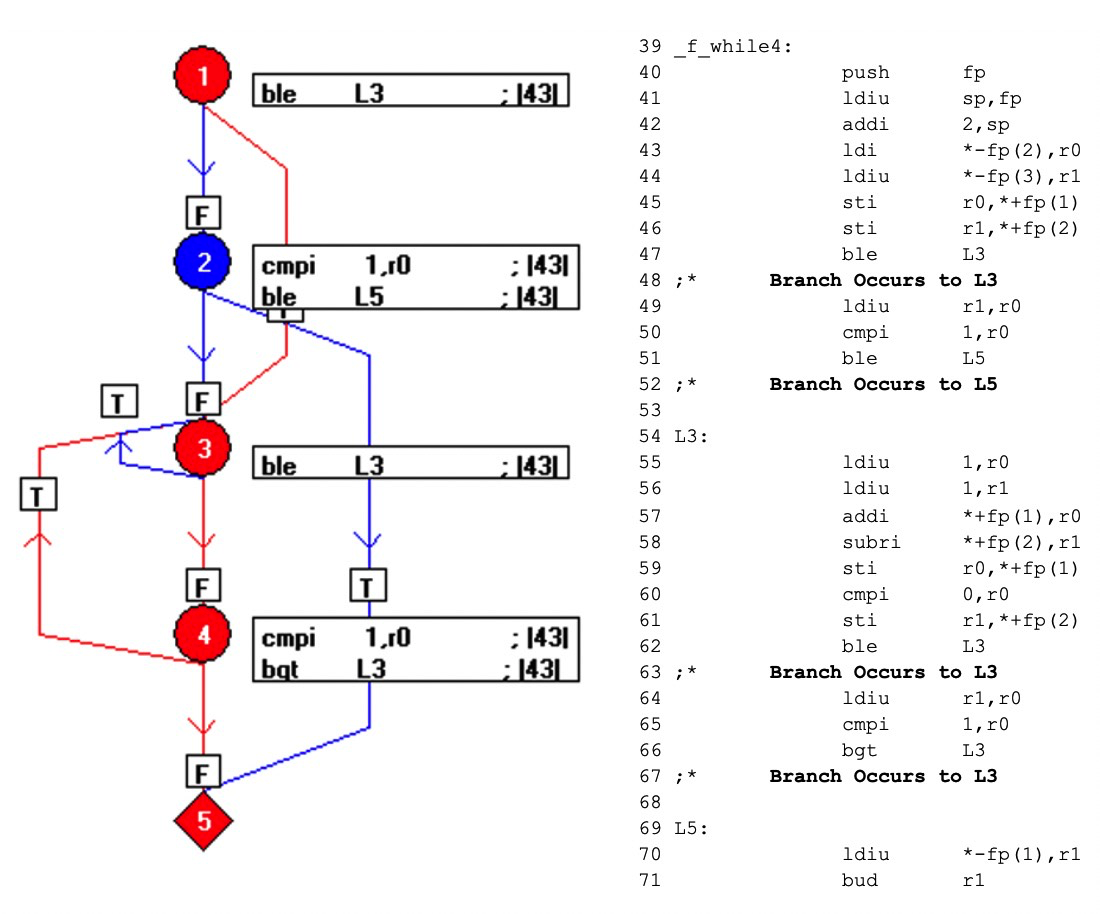
図8:これはコードがコンパイルされたときの結果を示しています。フローグラフの青い要素は、f_while4(0,3)の呼び出しによって実行されていないコードを表しています。 (出典:LDRA)
明らかに、オブジェクトコードの検証には、コンパイラがその設計ルールに従い、開発者の最善の意図をうっかり回避することを防ぐ力がありません。しかし、それはそのような不一致を不注意な人の注意を引く可能性があり、実際にそうします。
ここで、前の「エラーの呼び出し」の例のコンテキストでその原則を検討します。もちろん、完成したシステムのソースコードは、単体テストレベルで証明されたものと同じであるため、それを比較しても何もわかりません。しかし、完成したシステムにオブジェクトコード検証を適用することは、開発者が意図したとおりに本質的な動作が表現されていることを保証する上で非常に貴重です。
あらゆる世界でのベストプラクティス
コンパイラがテストハーネスでユニットテストとは異なる方法でコードを処理する場合、ソースコードのユニットテストカバレッジは価値がありますか?答えは、修飾された「はい」です。多くのシステムは、そのようなアーティファクトの証拠で認定されており、サービスにおいて安全で信頼できることが証明されています。ただし、すべてのセクターで最も重要なシステムの場合、開発プロセスが最も詳細な精査に耐え、ベストプラクティスに準拠することである場合、ソースレベルのユニットテストカバレッジはOCVによって補完される必要があります。設計基準を満たしていると想定するのは妥当ですが、これらの基準には機能安全に関する考慮事項は含まれていません。オブジェクトコードの検証は、現在、コンパイラの動作が標準に準拠している機能安全の世界への最も確実なアプローチを表していますが、それでも重大な悪影響を与える可能性があります。
埋め込み