


AI対応のSoCは複数のビデオストリームを処理します
Ambarellaは、セキュリティカメラとスマートシティシステムの複数または単一の入力から、コンピュータービジョンとAI処理用の2つのデバイスを発売します。
画像処理のスペシャリストであるAmbarellaは、シングルセンサーおよびマルチセンサーのセキュリティカメラ用に2つの新しいSoCを発売しました。それぞれのSoCは、同社のCVflowAIアクセラレータエンジンによって実現される新しいAI機能を備えています。どちらも4Kビデオエンコーディングと、顔認識やナンバープレート認識などの高度なAI処理をサポートしています。
CV5S SoCは、各4K画像ストリームで高度なAIを実行しながら、それぞれ30フレーム/秒(fps)で最大8MP / 4K解像度の4つのイメージャーチャネルをエンコードするマルチセンサーカメラシステムを対象としています。最大14の入力を処理できます。 SoCファミリは、Ambarellaの前世代の製品のエンコーディング解像度とメモリ帯域幅を2倍にし、消費電力を30%削減します。 5W未満を消費し、12個のeTOPS(GPUと同等のTOPS、同じAI処理タスクを実行するために必要なGPU馬力の量のAmbarellaの測定値)を提供します。
もう1つの新しいSoCであるCV52Sは、シングルセンサーカメラを対象とし、60fpsで4K解像度をサポートします。前世代のAmbarellaSoCと比較して、この新しいデバイスはAIパフォーマンスを4倍にし、CPUスループットを2倍にし、メモリ帯域幅を50%増やします。 <3 Wを消費し、6つのeTOPSを提供します。
パフォーマンスの向上は、5 nmプロセスノードへの移行と、Ambarellaの社内CVflowAIアクセラレータブロックの改善および拡大に起因します。
アンバレラのマーケティング担当シニアディレクターであるジェロームギゴットは、次のように述べています。 「しかし、それはカメラを作りません、それは製品を作りません。 AIアクセラレーターだけを持っているのなら、AIアクセラレーターを持っているだけです。」
Gigotは、4Kまたは8Kビデオのイメージングパイプラインは複雑であり、大量のデータを処理し、ビッグデータボリュームをエンコードし、それらのデータをAI処理用の特別なブロックに転送し、おそらくLinuxスタックを最上位で実行していると述べました。ビデオ品質を維持しながら、低電力予算でこれを達成することは困難です。
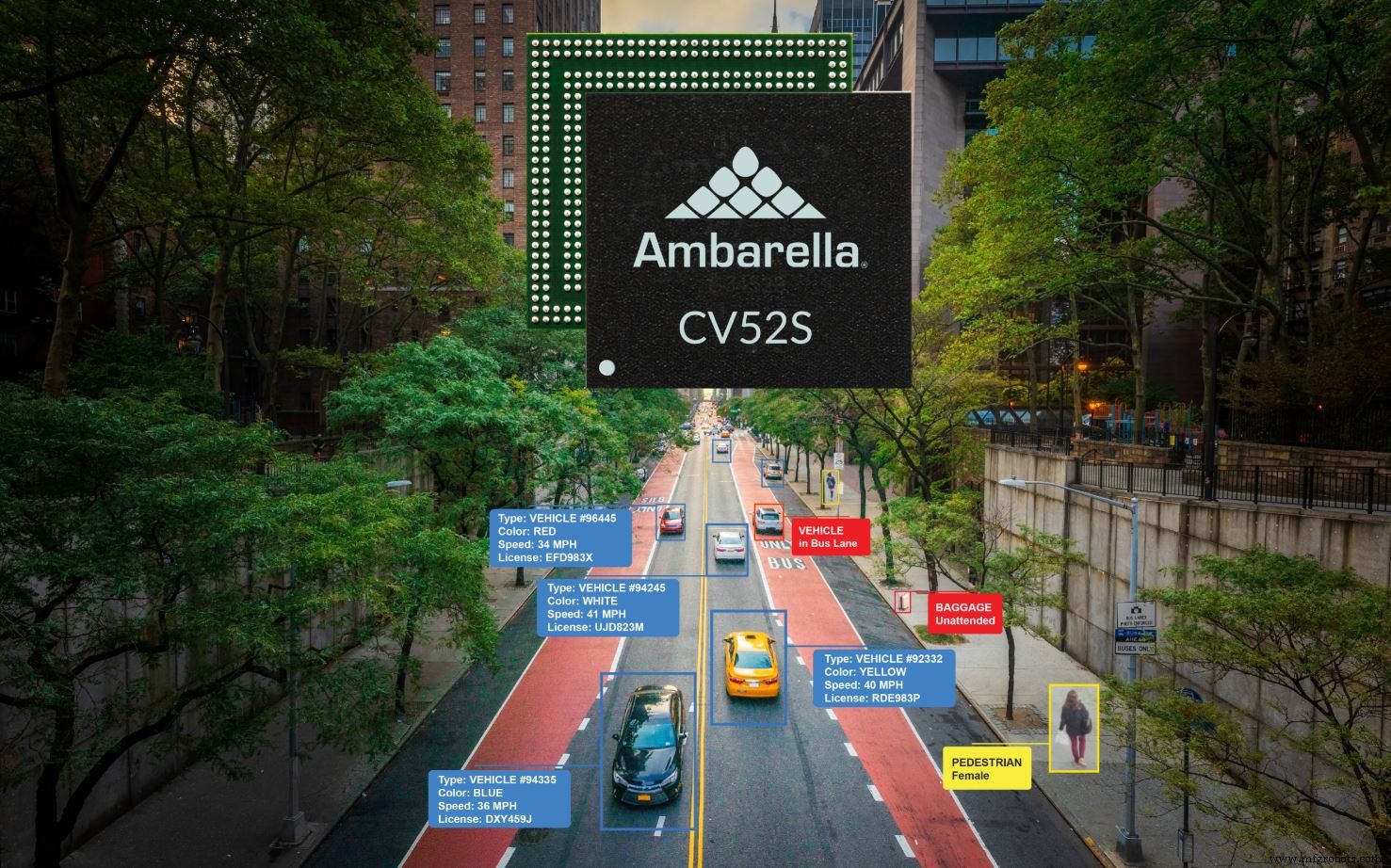
CV52Sは、交通監視やその他のスマートシティアプリケーションで見られるような単一センサー設計を対象としています(出典:Ambarella)
CVflow AIアクセラレータに加えて、両方の新しいSoCには、カラー処理、自動露出、自動ホワイトバランス、ノイズフィルタリングなどの機能を処理するAmbarellaの画像信号プロセッサ(ISP)が含まれています。
「私たちが16年間開発してきたこのブロック」とギゴットは言いました。 「だからこそ、スタートアップにはまだ長い道のりがあると私たちは考えています。 [他の場所からのISPブロック]のライセンスを取得することはできますが、メモリアクセスやその他すべての点で、システムの他の部分と実際には統合されていません。」
メモリシステムは、同社のIPの重要な要素の1つです。
「メモリコントローラーが1つあり、データをオンチップで取得するときにすべてを調整します。コピーを作成しないようにしています」とGigot氏は述べています。 「ポインタを移動しますが、データは移動しません。これは、チップが何をするのかを正確に把握して、アーキテクチャ全体を最初から設計する場合にのみ可能です。」
アクセラレータエンジン
AIアクセラレーターは、畳み込みやその他の一般的なAI機能を高速化できる、または従来のコンピュータービジョンワークロードに使用できるベクトルプロセッサーです。ユーザーは、ニューラルネットワークの一部(シングルショット検出器ネットワークでの並べ替えアルゴリズムなど)を実行するか、オンチップのデュアルコアArm Cortex-A76CPUを介して実行するかを選択することもできます。
ソフトウェアスタックを使用すると、アプリケーションで係数のスパース性を利用できます。これは、値がゼロに近いネットワーク係数をゼロに切り捨てる手法です。このアプローチでは、計算要件を大幅に削減するために、アルゴリズムから計算の「分岐」全体を「整理」できます。
「スパース化は、係数がゼロの場合、私たちのアーキテクチャでは操作を行わないため、スキップ[関数]があるため、非常に効果的な手法です」と彼は言いました。 「したがって、その係数の結果は計算しません。ほぼゼロサイクルかかります。」
ギゴット氏によると、このプロセスでは通常、係数の50〜80パーセントがスパース化のターゲットとして識別されます。プロセス中に失われた予測精度を取り戻すために、通常、スパース化後にいくつかのマイナーな再トレーニングが必要です。 Gigotによると、再トレーニングは通常、元のモデルの1%以内の精度をもたらす可能性があります。これは、特に最大5倍のモデルサイズの縮小を考えると、ほとんどの顧客にとって許容できるトレードオフです。 Ambarellaは、アーキテクチャをより意識したスパース化および量子化ツールにも取り組んでいます。
クリックしてフルサイズの画像を表示
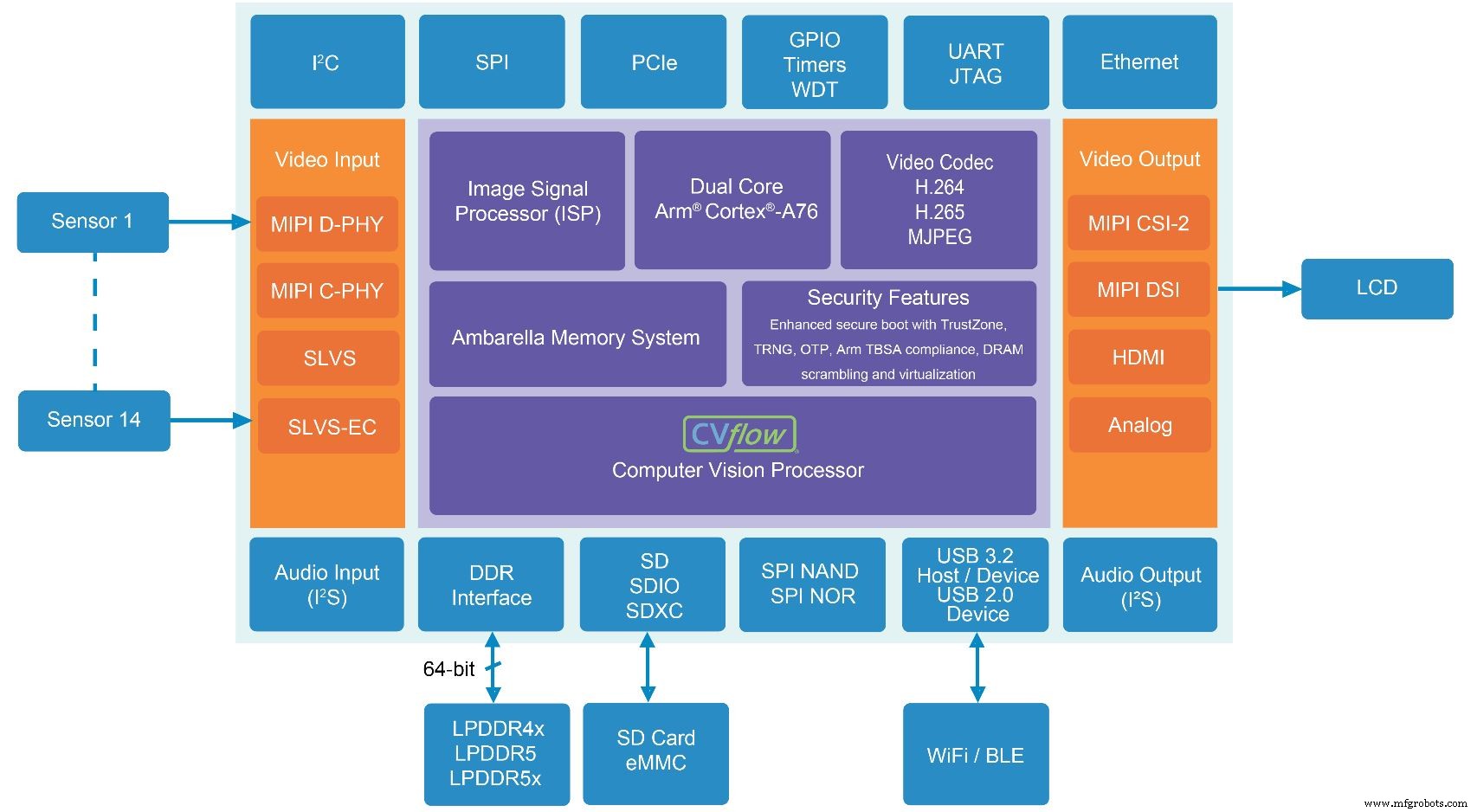
マルチセンサーカメラシステム用のCV5SSoCには、最新世代のAmbarellaのCVflow AIとコンピュータービジョンアクセラレーターが含まれています(出典:Ambarella)
最大14のビデオストリームを受け入れ、それらのストリームで同時にAIを実行する機能を使用して、顧客は複数のニューラルネットワークを同時に実行しますか?ある種の多重化スキームが必要ですか?

ジェロームギゴット(出典:アンバレラ)
はい、両方に、ギゴットは答えました。 「CVflowは非常に高速なベクトルエンジンであり、非常に高速な畳み込みエンジンです。すべてが時分割多重化されています。ハードウェアにはさまざまなパスがあるため、操作を並列化できますが、GPUでのバッチ処理とはまったく異なる特定のネットワークに結び付けることはありません。」
バッチ処理は、大規模なGPUでよく使用される手法であり、画像をグループ化して送信し、並列処理します。 GPUには、他のパラメーターがすでにロードされています。このアプローチでは、操作を切り替える必要がないため、コンピューティングコストが削減されます。
CVflowのような小さなエンジンの場合、チップのメモリはすべてのパラメータを一度に保存できないため、大きなニューラルネットワークをチャンクに分割して処理する必要があります。連続するチャンクは、同じニューラルネットワーク、別のネットワーク、または別のチャネル入力から発生する場合があります。ギゴット氏によると、CVflowでの一般的なハードウェア使用率は70〜80%であり、ネットワーク/チャネルの切り替えは効率に影響を与えないと付け加えています。
CV5SとCV52Sは、2021年10月にサンプリングを開始する予定です。
>>この記事は、もともと姉妹サイトEEで公開されました。タイムズ。
>
関連コンテンツ:
- AIビジョンプロセッサは、2W未満で30fpsの8Kビデオを可能にします
- Ambarellaは新しいカメラSoCでインテリジェントなエッジセンシングをターゲットにしています
- FPGAはスバルEyesightビジョンベースADASのASICに取って代わります
- Armは、自律性と視覚の安全性のためにCPU、GPU、ISPを追加します
- 低電力AIビジョンボードは、単一のバッテリーで「数年」持続します
Embeddedの詳細については、Embeddedの週刊メールニュースレターを購読してください。
埋め込み
- Javaは複数の例外をキャッチします
- マイクロチップ:PolarFire FPGAベースのソリューションにより、最小フォームファクタの4Kビデオとイメージングが可能になります
- Rutronik:RedpineSignalsのマルチプロトコルワイヤレスSoCおよびモジュール
- ルネサス:MIPI-CSI2入力を備えたフルHDLCDビデオコントローラー
- 複数の推論チップを使用するには、慎重な計画が必要です
- 高度なSoCは、医療用IoT設計に大きな変化をもたらします
- ビデオプロセッサにより、バッテリ駆動の設計で4Kビデオコーディングが可能になります
- Abaco Systems:頑丈なXMCグラフィックスとビデオボード
- ポートウェル:19インチシステムはビデオウォールアプリケーションを対象としています
- 小さなモジュールは複数のバイオセンサーを統合します
- Java 8-ストリーム