


ディープラーニングと機械学習
コンピューターの初期の頃、科学者は主にコンピューターを使用して単純な数学的および論理演算を実行していました。その後、コンピューターはゆっくりと進化し、複雑な計算を実行し、問題解決を精巧に行い、世界の情報バックボーンを形成しました。従来のコンピューティングの範囲を超えて移動するということは、コンピューターにインテリジェンスが必要であることを意味しました。
研究者とコンピューターエンジニアは、人間の知性を模倣するようになりました。人工知能(AI)は、人間と同じくらいインテリジェントなコンピューティングシステムを作成することに専念するコンピューターサイエンスの分野です。初期のAIモデルは、複雑な論理演算を実行するコンピューティングシステムでした。その後、より高度な技術が開発され、よりスマートな、または「インテリジェントな」タスクを実行できるようになりました。
AIで最もよく使用される用語の2つは、機械学習と深層学習です。この記事では、これら2つの手法の起源、それらの共通点、および相違点について説明します。
ディープラーニングと機械学習
機械学習と深層学習はAIのサブセットです。それらの間で、ディープラーニングは機械学習のサブセットです。つまり、すべての深層学習は機械学習ですが、すべての機械学習が深層学習であるとは限りません。それらの違いを理解するために、機械学習という用語は、この記事の残りの部分でディープラーニングを除外します。
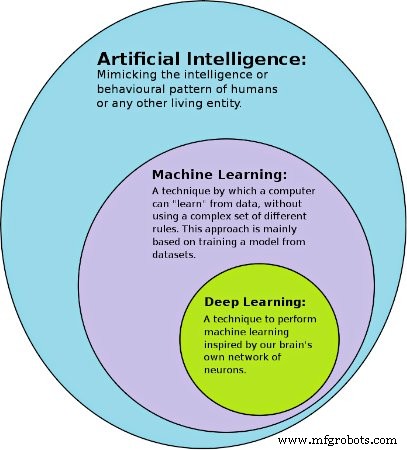
図1。 AI、機械学習、深層学習が互いにどのように関連しているかを示す図。使用した画像 Avimanyu786
機械学習
機械学習は、トレーニングデータセットの特性を理解するために、大量のデータを分析します。トレーニングデータセットから学んだことは、他のデータセットに適用されて「インテリジェントな」意思決定を行います。トレーニングデータセットで作成されたモデルは、他の同様のデータセットと連携して、目的の出力を生成できます。
機械学習モデルのトレーニングデータセットにはラベルを付ける必要があり、開発者は新しいモデルのトレーニング中に学習プロセスを監視および調整する必要があります。基本的なコンピューティングに加えて、統計モデルは機械学習モデルのトレーニングに多用されています。
猫と犬を区別することは、人工学習スペースの一般的な例です。以下は、機械学習モデルがデータを使用してトレーニングされる方法の概要です。
トレーニングモデルには、猫と犬の何千もの画像が含まれています。これらの各画像には、「猫」または「犬」のラベルが付いています。トレーニング中のモデルは、猫、犬、その他のオブジェクトを区別する画像から特性を識別します。特性は、統計的手法を使用して画像から識別されます。モデルが十分なデータでトレーニングされると、ラベルのない画像が提供されます。訓練されたモデルが猫と犬の画像を希望の精度でうまく区別できれば、それは成功した機械学習モデルです。
ディープラーニング
ディープラーニングは、従来の機械学習の進化形です。人間は何千ものラベル付きの例で学習しません。彼らは多くの外部の助けや検証なしで自動的に学びます。ディープラーニングは、機械学習をこのインテリジェントな学習モデルに一歩近づけます。
深層学習モデルも大量のデータでトレーニングする必要がありますが、モデルはラベル付きデータでトレーニングされていません。深層学習モデルに供給されるすべてのデータにはラベルが付いていません。モデルは、データからさまざまな要素を識別して、必要な出力を提供します。

図2。 農業で使用されるニューラルネットワークの視覚的表現。
深層学習モデルは、ニューラルネットワークと呼ばれる複雑な数学システムを使用してデータから学習します。重みの異なる数学関数の複数のレイヤーが含まれています。ディープラーニングという用語の「ディープ」は、これらの処理レイヤーからのものです。
ディープラーニングモデルが猫と犬の区別にどのように取り組んでいるかを概説しましょう。ニューラルネットワークには、猫と犬のラベルのない多数の画像が供給されます。ニューラルネットワークは、写真に2セットの動物がいることを把握し、2匹の動物を区別する方法を特定する必要があります。ラベル付けされたデータや開発者による監督は必要ありません。
モデルのトレーニングに成功すると、猫と犬の画像をいくつでも区別できます。
機械学習とディープラーニングの比較
次の表は、機械学習とディープラーニングの違いを簡単に比較したものです。ディープラーニングは機械学習のサブセットですが、この比較では、ディープラーニングは機械学習という用語から除外されていることに注意してください。
| 機械学習 | ディープラーニング | |
| トレーニングデータ | ラベル付きデータ | ラベルのないデータ |
| 監督 | 教師あり学習 | 教師なし学習 |
| テクニック | 主に統計的手法 | 高度な数学関数 |
| データ量 | 必要なトレーニングデータが比較的少ない | 非常に大量のデータが必要です |
| 精度 | 比較的低い精度 | 大量のデータでより高い精度 |
| トレーニング時間 | 比較的少ない | 非常に長いトレーニング時間 |
図3。 機械学習とディープラーニングを比較した表。
ディープラーニングの産業用アプリケーション
機械学習と深層学習の両方に産業用アプリケーションがあります。ディープラーニングは、機械学習で実行できるすべてのアプリケーションで使用できます。しかし、ディープラーニングには、より多くの専門知識、はるかに大量のデータ、より高い計算能力、および時間が必要です。これらの要因により、両方の手法を選択するには、多数の要因を考慮する必要があります。
より高い精度が必要な場合は、深層学習モデルが推奨されます。ただし、深層学習モデルでより高い精度を実現するには、非常に大量のデータを処理する必要があるため、トレーニング期間がはるかに長くなります。機械学習アルゴリズムは、ほとんどの場合、日常的な使用法を実現できます。
考慮すべきもう1つの一般的な特性は、問題の複雑さです。複雑さが増すにつれて、深層学習モデルは機械学習モデルよりもうまく機能します。ただし、テクニックをどこで使用するかについてのカットアンドドライルールはありません。たとえば、機械学習は、プラントのエネルギー消費を分析および予測するのに十分です。ただし、自動化された品質管理システムを構築するには不十分です。このようなシナリオでは、ディープラーニングアルゴリズムが必要です。
今日、機械学習は、業界でもディープラーニングよりもはるかにアクセスしやすくなっています。しかし、やがて、ディープラーニングモデルが改善され、実装コストが削減され、参入障壁が低下します。つまり、より多くのコンピューティング能力をより低価格で利用できるようになります。業界でのディープラーニングの採用は時間の経過とともに増加します。
モノのインターネットテクノロジー