


VHDL でリング バッファー FIFO を作成する方法
循環バッファーは、シーケンシャル プログラミング言語でキューを作成するための一般的な構造ですが、ハードウェアに実装することもできます。この記事では、ブロック RAM に FIFO を実装するために、VHDL でリング バッファーを作成します。
FIFO を実装する際には、多くの設計上の決定を行う必要があります。どのようなインターフェースが必要ですか?リソースによって制限されていますか?オーバーリードとオーバーライトに対する回復力が必要ですか?遅延は許容範囲ですか?これらは、FIFO の作成を依頼されたときに頭に浮かんだ質問の一部です。
無料の FIFO インプリメンテーションがオンラインで多数存在し、Xilinx LogiCORE のような FIFO ジェネレーターも存在します。それでも、多くのエンジニアは独自の FIFO を実装することを好みます。それらはすべて同じ基本的なキューおよびデキュー タスクを実行しますが、詳細を考慮すると大きく異なる可能性があるためです。
リング バッファの仕組み
リング バッファは、連続したメモリを使用してバッファリングされたデータを最小限のデータ シャッフルで格納する FIFO 実装です。新しい要素は、書き込み時から読み取られて FIFO から削除されるまで、同じメモリ位置に留まります。
FIFO 内の要素の位置と数を追跡するために、2 つのカウンターが使用されます。これらのカウンタは、データが格納されているメモリ空間の先頭からのオフセットを参照します。 VHDL では、これは配列セルへのインデックスになります。この記事の残りの部分では、これらのカウンターはポインターであることに言及します。 .
これらの 2 つのポインタは head です そして尻尾 ポインター。ヘッドは常に、次に書き込まれるデータを含むメモリ スロットを指し、テールは FIFO から読み取られる次の要素を指します。他にもバリエーションがありますが、これを使用します。
空の状態
![]()
先頭と末尾が同じ要素を指している場合、FIFO が空であることを意味します。上の画像は、8 つのスロットを持つ FIFO の例を示しています。ヘッド ポインターとテール ポインターの両方が要素 0 を指しており、FIFO が空であることを示しています。これがリングバッファの初期状態です。
両方のポインターが別のインデックス (たとえば 3) にある場合、FIFO はまだ空であることに注意してください。書き込みごとに、ヘッド ポインターは 1 つ前に移動します。テール ポインターは、FIFO のユーザーが要素を読み取るたびにインクリメントされます。
いずれかのポインターが最高のインデックスにある場合、次の書き込みまたは読み取りにより、ポインターは最低のインデックスに戻ります。これがリング バッファの利点です。データは移動せず、ポインタだけが移動します。
ヘッドリードテール

上の画像は、5 回の書き込み後の同じリング バッファーを示しています。テール ポインターはまだスロット番号 0 にありますが、ヘッド ポインターはスロット番号 5 に移動しています。データを含むスロットは、図では水色で示されています。テール ポインターは最も古い要素にあり、ヘッドは次の空きスロットを指します。
ヘッドがテールよりも高いインデックスを持つ場合、ヘッドからテールを引くことでリング バッファー内の要素の数を計算できます。上の画像では、5 つの要素のカウントが得られます。
テールリードヘッド

尾から頭を差し引くことは、頭が尾より進んでいる場合にのみ機能します。上の画像では、頭はインデックス 2 で、尻尾はインデックス 5 です。したがって、この単純な計算を実行すると、2 – 5 =-3 となり、意味がありません。
解決策は、FIFO のスロットの総数 (この場合は 8) でヘッドをオフセットすることです。計算は (2 + 8) – 5 =5 となり、これが正解です。
尻尾は永遠に頭を追いかけます。これがリング バッファーの仕組みです。半分の確率で、テールの方がヘッドよりもインデックスが高くなります。上の画像の水色で示されているように、データは 2 つの間に保存されます。
完全な状態

完全なリング バッファーでは、末尾が先頭の直後のインデックスを指します。この方式の結果、すべてのスロットを使用してデータを保存することはできず、少なくとも 1 つの空きスロットが必要です。上の画像は、リング バッファがいっぱいになっている状況を示しています。開いているが使用できないスロットは黄色です。
専用のエンプティ/フル信号も、リング バッファがフルであることを示すために使用できます。これにより、すべてのメモリ スロットにデータを格納できるようになりますが、レジスタとルックアップ テーブル (LUT) の形で追加のロジックが必要になります。したがって、keep one open を使用します。 これは安価なブロック RAM を浪費するだけなので、リング バッファ FIFO の実装のスキームです。
リング バッファ FIFO の実装
FIFO との間のインターフェイス信号をどのように定義するかによって、リング バッファーの可能な実装数が制限されます。この例では、従来の read/write enable および empty/full/valid インターフェイスのバリエーションを使用します。
書き込みデータがあります FIFO にプッシュされるデータを運ぶ入力側のバス。 書き込み可能もあります アサートされると、FIFO が入力データをサンプリングします。
出力側には読み取りデータがあります そして読み取り有効 FIFO によって制御される信号。 読み取り可能もあります FIFO のダウンストリーム ユーザーによって制御される信号。
空 そしていっぱい 制御信号は従来の FIFO インターフェースの一部であり、それらも使用します。それらは FIFO によって制御され、その目的は FIFO の状態をリーダーとライターに伝えることです。
背圧
アクションを実行する前に FIFO が空またはフルになるまで待機することの問題は、インターフェイス ロジックが反応する時間がないことです。シーケンシャル ロジックは、クロック サイクルごとに動作し、クロックの立ち上がりエッジがデザイン内のイベントをタイムステップに効果的に分離します。

解決策の 1 つは、
この実装では、前のシグナルは empty_next という名前になります。 と full_next 、単純に名前の接頭辞よりも後置の方が好きだからです。

実体
下の画像は、リング バッファ FIFO のエンティティを示しています。ポートの入力信号と出力信号に加えて、2 つの汎用定数があります。 RAM_WIDTH generic は、入力ワードと出力ワードのビット数、つまり各メモリ スロットに含まれるビット数を定義します。
RAM_DEPTH generic は、リング バッファー用に予約されるスロットの数を定義します。リング バッファがいっぱいであることを示すために 1 つのスロットが予約されているため、FIFO の容量は RAM_DEPTH になります。 – 1. RAM_DEPTH 定数は、ターゲット FPGA の RAM の深さと一致する必要があります。ブロック RAM プリミティブ内の未使用の RAM は無駄になり、FPGA 内の他のロジックと共有できません。
entity ring_buffer is
generic (
RAM_WIDTH : natural;
RAM_DEPTH : natural
);
port (
clk : in std_logic;
rst : in std_logic;
-- Write port
wr_en : in std_logic;
wr_data : in std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Read port
rd_en : in std_logic;
rd_valid : out std_logic;
rd_data : out std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Flags
empty : out std_logic;
empty_next : out std_logic;
full : out std_logic;
full_next : out std_logic;
-- The number of elements in the FIFO
fill_count : out integer range RAM_DEPTH - 1 downto 0
);
end ring_buffer;
クロックとリセットに加えて、ポート宣言には従来のデータ/イネーブルの読み取りおよび書き込みポートが含まれます。これらは、新しいデータを FIFO にプッシュするため、およびそこから最も古い要素をポップするために、上流および下流のモジュールによって使用されます。
rd_valid rd_data の場合、信号は FIFO によってアサートされます。 ポートには有効なデータが含まれています。このイベントは、rd_en のパルスの後に 1 クロック サイクル遅れます。 信号。なぜこのようにしなければならないのかについては、この記事の最後で詳しく説明します。
次に、FIFO によって設定されたエンプティ/フル フラグが来ます。 empty_next empty の間、1 個または 0 個の要素が残っている場合にシグナルがアサートされます。 FIFO に 0 要素がある場合にのみアクティブになります。同様に、full_next full の場合、シグナルは 1 つまたは 0 個の要素を追加できる余地があることを示します。 FIFO が別のデータ要素を収容できない場合にのみアサートします。
最後に fill_count があります 出力。これは、現在 FIFO に格納されている要素の数を反映する整数です。この出力信号を含めたのは、単にモジュール内で使用するためです。エンティティを介してそれを分割することは基本的に自由であり、ユーザーはこのモジュールをインスタンス化するときにこのシグナルを未接続のままにすることを選択できます。
宣言領域
VHDL ファイルの宣言領域で、カスタム タイプ、サブタイプ、多数のシグナル、およびリング バッファー モジュールでの内部使用のためのプロシージャを宣言します。
type ram_type is array (0 to RAM_DEPTH - 1) of
std_logic_vector(wr_data'range);
signal ram : ram_type;
subtype index_type is integer range ram_type'range;
signal head : index_type;
signal tail : index_type;
signal empty_i : std_logic;
signal full_i : std_logic;
signal fill_count_i : integer range RAM_DEPTH - 1 downto 0;
-- Increment and wrap
procedure incr(signal index : inout index_type) is
begin
if index = index_type'high then
index <= index_type'low;
else
index <= index + 1;
end if;
end procedure;
まず、RAM をモデル化する新しい型を宣言します。 ram_type type はベクトルの配列で、一般的な入力によってサイズ設定されます。 ram を宣言するために、次の行で新しい型が使用されます。 リングバッファにデータを保持する信号。
次のコード ブロックでは、index_type を宣言します。 、整数のサブタイプ。その範囲は RAM_DEPTH によって間接的に管理されます ジェネリック。サブタイプ宣言の下で、インデックス タイプを使用して、ヘッド ポインターとテール ポインターという 2 つの新しいシグナルを宣言しています。
次に、エンティティ シグナルの内部コピーであるシグナル宣言のブロックが続きます。それらはエンティティ シグナルと同じベース名を持ちますが、_i で後置されます。 内部使用であることを示します。 inout を使用するスタイルが悪いと考えられているため、このアプローチを使用しています。 エンティティ シグナルのモードですが、これは同じ効果があります。
最後に、incr という名前のプロシージャを宣言します。 index_type を取る 信号をパラメーターとして指定します。このサブプログラムは、ヘッド ポインタとテール ポインタをインクリメントするために使用され、それらが最高値にあるときに 0 に戻します。 head と tail は integer のサブタイプであり、通常はラッピング動作をサポートしていません。この問題を回避する手順を使用します。
並行ステートメント
アーキテクチャの最上部で、並行ステートメントを宣言します。これらのワンライナー シグナルの割り当ては、見過ごされやすいため、通常のプロセスの前に収集することを好みます。並行ステートメントは実際にはプロセスの形式です。並行ステートメントの詳細については、こちらをご覧ください:
VHDL で同時実行ステートメントを作成する方法
-- Copy internal signals to output empty <= empty_i; full <= full_i; fill_count <= fill_count_i; -- Set the flags empty_i <= '1' when fill_count_i = 0 else '0'; empty_next <= '1' when fill_count_i <= 1 else '0'; full_i <= '1' when fill_count_i >= RAM_DEPTH - 1 else '0'; full_next <= '1' when fill_count_i >= RAM_DEPTH - 2 else '0';
同時割り当ての最初のブロックでは、エンティティ シグナルの内部バージョンを出力にコピーしています。これらの行により、エンティティ シグナルが正確に同時に内部バージョンに従うようになりますが、シミュレーションでは 1 デルタ サイクルの遅延があります。
並行ステートメントの 2 番目と最後のブロックは、出力フラグを割り当てる場所であり、リング バッファーのフル/空の状態を通知します。 RAM_DEPTH に基づいて計算しています ジェネリックで fill_count 信号。 RAM の深さは、変化しない定数です。したがって、フラグは更新されたフィル カウントの結果としてのみ変更されます。
ヘッド ポインタの更新
ヘッド ポインタの基本的な機能は、このモジュールの外部からライト イネーブル信号がアサートされるたびにインクリメントすることです。 head を渡すことでこれを行っています 前述の incr へのシグナル
PROC_HEAD : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
head <= 0;
else
if wr_en = '1' and full_i = '0' then
incr(head);
end if;
end if;
end if;
end process;
私たちのコードには追加の and full_i = '0' が含まれています 上書きから保護するためのステートメント。 FIFO がいっぱいのときにデータ ソースが FIFO に書き込もうとしないことが確実な場合は、このロジックを省略できます。この保護がないと、上書きによってリング バッファが再び空になります。
リング バッファーがいっぱいのときにヘッド ポインターがインクリメントされると、ヘッドはテールと同じ要素を指します。したがって、モジュールは含まれているデータを「忘れ」、FIFO フィルは空に見えます。
full_i を評価することによって ヘッドポインタをインクリメントする前に信号を送信すると、上書きされた値のみが忘れられます。このソリューションの方が優れていると思います。いずれにせよ、上書きが発生した場合は、このモジュールの外部に誤動作があることを示しています。
テール ポインターの更新
テール ポインターはヘッド ポインターと同様の方法でインクリメントされますが、read_en 入力がトリガーとして使用されます。上書きと同じように、and empty_i = '0' を含めることで、過剰読み取りから保護しています。 ブール式で。
PROC_TAIL : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
tail <= 0;
rd_valid <= '0';
else
rd_valid <= '0';
if rd_en = '1' and empty_i = '0' then
incr(tail);
rd_valid <= '1';
end if;
end if;
end if;
end process;
さらに、rd_valid をパルスしています。 有効な読み取りごとに信号を送信します。読み出されたデータは、rd_en の後のクロック サイクルで常に有効です。 FIFO が空でない場合、アサートされました。この知識があれば、このシグナルは実際には必要ありませんが、便宜上含めます。 rd_valid モジュールがインスタンス化されるときに接続されていない場合、信号は合成で最適化されます。
ブロック RAM の推論
合成ツールでブロック RAM を推論させるには、リセットなしの同期プロセスで読み出しポートと書き込みポートを宣言する必要があります。クロック サイクルごとに RAM の読み取りと書き込みを行い、制御信号にこのデータの使用を処理させます。
PROC_RAM : process(clk)
begin
if rising_edge(clk) then
ram(head) <= wr_data;
rd_data <= ram(tail);
end if;
end process;
このプロセスは、次の書き込みがいつ発生するかを知りませんが、知る必要はありません。代わりに、私たちは継続的に書いているだけです。 head の場合 信号が書き込みの結果としてインクリメントされると、次のスロットへの書き込みを開始します。これにより、書き込まれた値が効果的に固定されます。
フィルカウントの更新
fill_count 信号はフル信号とエンプティ信号を生成するために使用され、これらの信号は FIFO のオーバーライトとオーバーリードを防止するために使用されます。フィル カウンターは、ヘッド ポインターとテール ポインターに敏感な組み合わせプロセスによって更新されますが、これらの信号はクロックの立ち上がりエッジでのみ更新されます。したがって、フィル カウントもクロック エッジの直後に変化します。
PROC_COUNT : process(head, tail)
begin
if head < tail then
fill_count_i <= head - tail + RAM_DEPTH;
else
fill_count_i <= head - tail;
end if;
end process;
フィルカウントは、頭から尾を引くだけで計算されます。テール インデックスがヘッドよりも大きい場合、RAM_DEPTH の値を追加する必要があります。 現在リング バッファにある要素の正しい数を取得するための定数
リング バッファ FIFO の完全な VHDL コード
library ieee;
use ieee.std_logic_1164.all;
entity ring_buffer is
generic (
RAM_WIDTH : natural;
RAM_DEPTH : natural
);
port (
clk : in std_logic;
rst : in std_logic;
-- Write port
wr_en : in std_logic;
wr_data : in std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Read port
rd_en : in std_logic;
rd_valid : out std_logic;
rd_data : out std_logic_vector(RAM_WIDTH - 1 downto 0);
-- Flags
empty : out std_logic;
empty_next : out std_logic;
full : out std_logic;
full_next : out std_logic;
-- The number of elements in the FIFO
fill_count : out integer range RAM_DEPTH - 1 downto 0
);
end ring_buffer;
architecture rtl of ring_buffer is
type ram_type is array (0 to RAM_DEPTH - 1) of
std_logic_vector(wr_data'range);
signal ram : ram_type;
subtype index_type is integer range ram_type'range;
signal head : index_type;
signal tail : index_type;
signal empty_i : std_logic;
signal full_i : std_logic;
signal fill_count_i : integer range RAM_DEPTH - 1 downto 0;
-- Increment and wrap
procedure incr(signal index : inout index_type) is
begin
if index = index_type'high then
index <= index_type'low;
else
index <= index + 1;
end if;
end procedure;
begin
-- Copy internal signals to output
empty <= empty_i;
full <= full_i;
fill_count <= fill_count_i;
-- Set the flags
empty_i <= '1' when fill_count_i = 0 else '0';
empty_next <= '1' when fill_count_i <= 1 else '0';
full_i <= '1' when fill_count_i >= RAM_DEPTH - 1 else '0';
full_next <= '1' when fill_count_i >= RAM_DEPTH - 2 else '0';
-- Update the head pointer in write
PROC_HEAD : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
head <= 0;
else
if wr_en = '1' and full_i = '0' then
incr(head);
end if;
end if;
end if;
end process;
-- Update the tail pointer on read and pulse valid
PROC_TAIL : process(clk)
begin
if rising_edge(clk) then
if rst = '1' then
tail <= 0;
rd_valid <= '0';
else
rd_valid <= '0';
if rd_en = '1' and empty_i = '0' then
incr(tail);
rd_valid <= '1';
end if;
end if;
end if;
end process;
-- Write to and read from the RAM
PROC_RAM : process(clk)
begin
if rising_edge(clk) then
ram(head) <= wr_data;
rd_data <= ram(tail);
end if;
end process;
-- Update the fill count
PROC_COUNT : process(head, tail)
begin
if head < tail then
fill_count_i <= head - tail + RAM_DEPTH;
else
fill_count_i <= head - tail;
end if;
end process;
end architecture;
上記のコードは、リング バッファー FIFO の完全なコードを示しています。以下のフォームに入力すると、ModelSim プロジェクト ファイルとテストベンチがすぐに郵送されます。
テストベンチ
FIFO は単純なテストベンチでインスタンス化され、その動作を実証します。以下のフォームを使用して、ModelSim プロジェクトとともにテストベンチのソース コードをダウンロードできます。
汎用入力は次の値に設定されています:
- RAM_WIDTH:16
- RAM_DEPTH:256
テストベンチは最初に FIFO をリセットします。リセットが解除されると、テストベンチは FIFO がいっぱいになるまで連続値 (1 ~ 255) を書き込みます。最後に、テストが完了する前に FIFO が空になります。
下の画像で、テストベンチの完全な実行の波形を確認できます。 fill_count 信号は、FIFO の充填レベルをよりよく示すために、波形のアナログ値として表示されます。
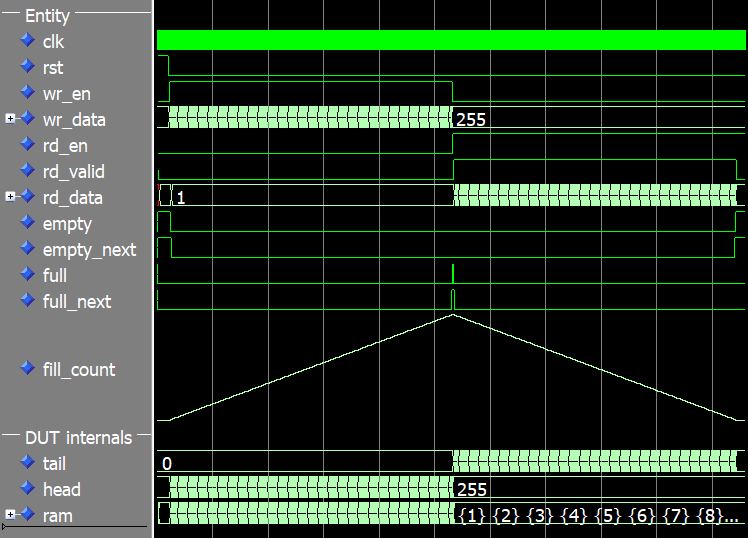
シミュレーションの開始時には、頭、尾、塗りつぶしカウントは 0 です。 full の時点で 信号がアサートされ、ヘッドの値は 255 になり、fill_count も同様です 信号。 RAM の深さが 256 であっても、フィル カウントは 255 までしか上がりません。これは、keep one open を使用しているためです。 この記事の前半で説明したように、フルとエンプティを区別するメソッドです。
FIFO への書き込みを停止し、FIFO からの読み取りを開始するターニング ポイントで、ヘッド値がフリーズし、テール カウントとフィル カウントが減少し始めます。最後に、シミュレーションの最後に FIFO が空になると、先頭と末尾の両方の値が 255 になり、フィル カウントは 0 になります。
このテストベンチは、デモンストレーション以外の用途には適していません。 FIFO からの出力が正しいことを検証するための自己チェック動作やロジックはまったくありません。
このモジュールは、来週の記事で 制約付きランダム検証 について掘り下げる際に使用します。 .これは、より一般的に使用される有向テストとは異なるテスト戦略です。つまり、テストベンチは DUT (被試験デバイス) とのランダムな相互作用を実行し、DUT の動作は別のテストベンチ プロセスで検証する必要があります。最後に、定義済みのイベントがいくつか発生すると、テストは完了です。
フォローアップのブログ投稿を読むには、ここをクリックしてください:
制約付きランダム検証
Vivado での合成
ザイリンクスの Vivado でリング バッファーを合成したのは、これが最も一般的な FPGA インプリメンテーション ツールであるためです。ただし、デュアル ポート ブロック RAM を備えたすべての FPGA アーキテクチャで動作するはずです。
リング バッファーをスタンドアロン モジュールとして実装できるようにするには、ジェネリック入力にいくつかの値を割り当てる必要があります。これは、Settings を使用して Vivado で行います。 → 一般 → ジェネリック/パラメータ 下の画像に示すように、メニュー。
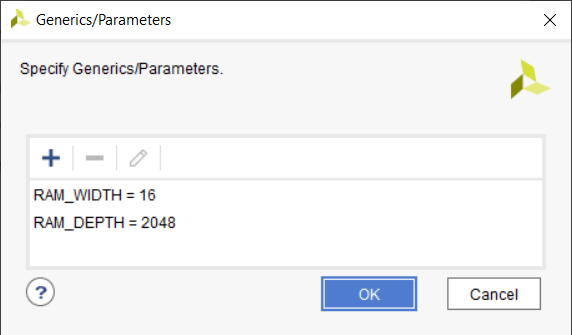
RAM_WIDTH の値 はシミュレーションと同じ 16 に設定されています。しかし、私は RAM_DEPTH を設定しました これは、私が選択したザイリンクス Zynq アーキテクチャの RAMB36E1 プリミティブの最大深度であるためです。より低い値を選択することもできますが、それでも同じ数のブロック RAM が使用されます。値を大きくすると、複数のブロック RAM が使用されることになります。
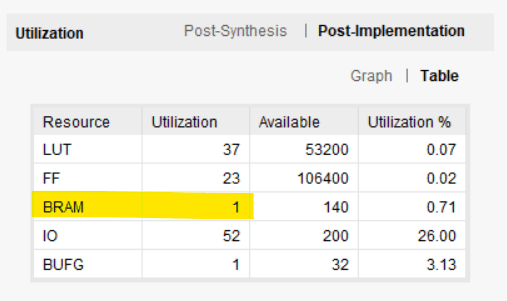
次の図は、Vivado でレポートされたインプリメンテーション後のリソース使用量を示しています。私たちのリング バッファーは、実際に 1 つのブロック RAM と、いくつかの LUT とフリップフロップを消費しています。
有効な信号を捨てる
rd_en の間の 1 クロック サイクルの遅延が、 そして rd_valid 実際には信号が必要です。結局、データはすでに rd_data に存在しています rd_en をアサートするとき 信号。この値をそのまま使用して、FIFO から読み取る次のクロック サイクルでリング バッファーを次の要素にスキップさせることはできませんか?

厳密に言えば、valid は必要ありません 信号。便宜上、この信号を含めました。重要な部分は、rd_en をアサートした後、クロック サイクルまで待たなければならないことです。 そうしないと、RAM に反応する時間がありません。
FPGA のブロック RAM は完全同期コンポーネントであり、データの読み取りと書き込みの両方にクロック エッジが必要です。読み取りクロックと書き込みクロックは同じクロック ソースから来る必要はありませんが、クロック エッジが必要です。さらに、RAM 出力と次のレジスタ (フリップフロップ) の間にロジックを配置することはできません。これは、RAM 出力のクロックに使用されるレジスタがブロック RAM プリミティブ内にあるためです。

上の画像は、値が wr_data からどのように伝播するかを示すタイミング図です。 RAMを介してリングバッファに入力し、最終的にrd_dataに表示されます 出力。各信号は立ち上がりクロック エッジでサンプリングされるため、書き込みポートの駆動を開始してから読み取りポートに現れるまでに 3 クロック サイクルかかります。そして、受信モジュールがこのデータを利用できるようになる前に、追加のクロック サイクルが経過します。
待ち時間の短縮
この問題を軽減する方法はありますが、FPGA で使用される追加のリソースが犠牲になります。リング バッファーの読み取りポートから 1 クロック サイクルの遅延を削減する実験を行ってみましょう。以下のコード スニペットでは、rd_data を変更しています。 ram に敏感な同期プロセスから組み合わせプロセスへの出力 と tail
PROC_READ : process(ram, tail)
begin
rd_data <= ram(tail);
end process;
残念ながら、このコードをブロック RAM にマップすることはできません。これは、RAM 出力と rd_data の最初のダウンストリーム レジスタの間に組み合わせロジックが存在する可能性があるためです。
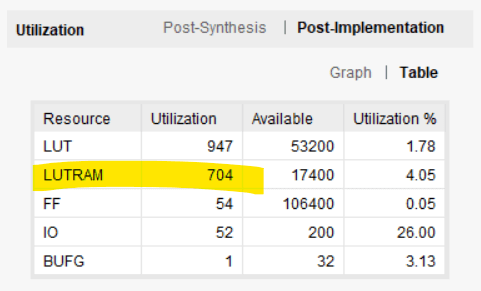
次の図は、Vivado によって報告されたリソース使用量を示しています。ブロック RAM は LUTRAM に置き換えられました。 LUT で実装される分散 RAM の形式。 LUT の使用量は 37 LUT から 947 に急増しました。ルックアップ テーブルとフリップフロップはブロック RAM よりも高価です。それがそもそもブロック RAM を使用する理由です。
ブロック RAM にリング バッファー FIFO をインプリメントするには、さまざまな方法があります。別のデザインを使用することで余分なクロック サイクルを節約できる場合がありますが、追加のサポート ロジックの形でコストがかかります。ほとんどのアプリケーションでは、この記事で紹介したリング バッファーで十分です。
更新:
AXI Ready/Valid ハンドシェイクを使用してブロック RAM にリング バッファー FIFO を作成する方法
次のブログ投稿では、制約付きランダム検証を使用して、リング バッファー モジュール用のより優れたテストベンチを作成します。 .
フォローアップのブログ投稿を読むには、ここをクリックしてください:
制約付きランダム検証
VHDL