


PyTorch と TensorFlow:詳細な比較
ディープ ラーニングの人気の高まりにより、ディープ ラーニング フレームワーク間の健全な競争が生まれました。 PyTorch と TensorFlow は、最も人気のあるディープ ラーニング フレームワークの 2 つとして際立っています。ライブラリは、主要な深層学習ツールとしてリードするために真っ向から競い合っています。
TensorFlow は古く、このため常にリードしていましたが、PyTorch は過去 6 か月で追いつきました。プロジェクトの深層学習フレームワークを選択する際、正しい選択をすることについて多くの混乱があります。
この記事では、PyTorch と TensorFlow を比較し、2 つのフレームワークの詳細な比較を提供します。
PyTorch と TensorFlow の比較:概要
PyTorch と TensorFlow はどちらも、競合他社が何をしているかを追跡します。ただし、2 つのフレームワークにはまだいくつかの違いがあります。
注: この表は水平方向にスクロール可能です。
| ライブラリ | PyTorch | TensorFlow 2.0 |
|---|---|---|
| 作成者 | FAIR Lab (Facebook AI Research Lab) | Google ブレイン チーム |
| ベース | たいまつ | テアノ |
| 生産 | 研究中心 | 業界重視 |
| 可視化 | Visdom | テンソルボード |
| 導入 | トーチサーブ (実験的) | TensorFlow サービス |
| モバイル展開 | はい (実験的) | はい |
| デバイス管理 | CUDA | 自動 |
| グラフ生成 | 動的および静的モード | 熱心で静的なモード |
| 学習曲線 | 開発者や科学者にとってより簡単 | 業界レベルのプロジェクトでより簡単 |
| U ケース | フェイスブック CheXNet テスラ 自動操縦 ユーバー パイロ | グーグル シノベーション ベンチャーズ ペイパル チャイナモバイル |
1.可視化
手作業による視覚化には時間がかかります。 PyTorch と TensorFlow の両方に、迅速な視覚分析のためのツールがあります。これにより、トレーニング プロセスの見直しが容易になります。視覚化は、結果の提示にも最適です。
TensorFlow
Tensorboard は、データの視覚化に使用されます。インターフェイスはインタラクティブで視覚的に魅力的です。 Tensorboard は、メトリクスとトレーニング データの詳細な概要を提供します。データは簡単にエクスポートでき、プレゼンテーションに最適です。プラグインは Tensorboard を PyTorch でも利用できるようにします。
ただし、Tensorboard は扱いにくく、使用が複雑です。
パイトーチ
PyTorch は視覚化に Visdom を使用します。インターフェイスは軽量で使いやすいです。 Visdom は柔軟でカスタマイズ可能です。 PyTorch tensor の直接サポートにより、簡単に使用できます。
Visdom には、対話性と、データを概観するための多くの重要な機能が欠けています。
2.グラフ生成
ニューラル ネットワーク アーキテクチャの生成には、次の 2 つのタイプがあります。
- 静的グラフ – 固定層アーキテクチャ。最初にマップが生成され、次にデータがプッシュされます。
- 動的グラフ – 動的レイヤー アーキテクチャ。マップは、データのオーバーロードを使用して暗黙的に定義されています。
TensorFlow
TensorFlow は最初から静的グラフを使用していました。静的グラフを使用すると、複数のマシンに分散できます。モデルはコードとは別にデプロイされます。静的グラフを使用することで、TensorFlow は、新しいアーキテクチャを扱う際に、より生産的で柔軟になりました。
TensorFlow は、熱心な実行と呼ばれる動的グラフを模倣する機能を追加しました。 TensorFlow 2 は、デフォルトで熱心な実行で実行されます。熱心な実行をオフにすると、静的グラフの生成が可能になります。
パイトーチ
PyTorch は最初から動的グラフを特徴としていました。この機能により、PyTorch は TensorFlow と競合しました。
外出先でグラフを変更できる機能は、プログラマーや研究者にとってより使いやすいニューラル ネットワーク生成へのアプローチであることが証明されました。構造化されたデータとデータのサイズのバリエーションは、動的グラフを使用すると扱いやすくなります。 PyTorch は静的グラフも提供します。
3.学習曲線
学習曲線は、以前の経験とディープ ラーニングを使用する最終目標によって異なります。
TensorFlow
TensorFlow は、より挑戦的なライブラリです。 Keras 関数により、TensorFlow が使いやすくなります。一般に、深層学習を始めたばかりの人にとって TensorFlow は理解しにくいものです。
この背後にある理由は、TensorFlow の多様な機能です。探索して理解するための多くの機能があります。これは初心者にとって気が散り、冗長です。
パイトーチ
PyTorch は学習しやすいライブラリです。 Python に慣れていると、コードを簡単に試すことができます。 PyTorch でニューラル ネットワークを作成するための Pythonic アプローチがあります。 PyTorch の柔軟性は、コードが実験しやすいことを意味します。
PyTorch はそれほど機能が豊富ではありませんが、基本的な機能はすべて利用できます。 PyTorch は簡単に始めて学ぶことができます。
4.導入
展開は、ソフトウェア開発チームにとって重要なソフトウェア開発ステップです。ソフトウェアの展開により、プログラムまたはアプリケーションを消費者が使用できるようになります。
TensorFlow
TensorFlow は TensorFlow Serving を使用します モデル展開用。 TensorFlow サービング 生産および産業環境を念頭に置いて設計されています。デプロイは、REST クライアント API を使用して柔軟で高性能です。 TensorFlow サービング Docker および Kubernetes とうまく統合できます。
パイトーチ
PyTorch は最近、展開の問題に取り組み始めました。 トーチサーブ PyTorch モデルをデプロイします。アプリケーション統合用の RESTful API があります。 PyTorch API は、モバイル展開用に拡張可能です。 トーチサーブ Kubernetes と統合します。
5. 並列処理と分散トレーニング
ビッグデータには、並列処理と分散トレーニングが不可欠です。一般的な指標は次のとおりです。
- スピードアップ – 並列モデルの速度 (複数の GPU) と比較した順次モデル (単一の GPU) の速度の比率。
- スループット – 単位時間あたりにモデルを通過する画像の最大数
- スケーラビリティ – システムがワークロードの増加を処理する方法
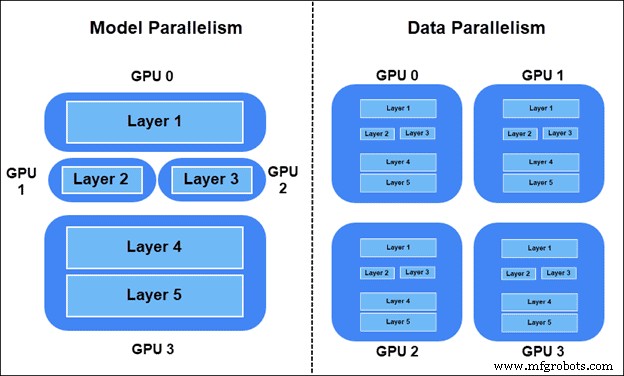
トレーニング ワークロードを分散するには、次の 2 つの方法があります。
- モデルの並列性 – モデルのレイヤーが異なるデバイスに分割されました。グラフの一部がトレーニングで同時に使用されます。
- データの並列処理 – すべてのデバイスにモデル全体のコピーがあります。各デバイスは、異なるデータ サンプルでトレーニングします。同期 SGD (確率的勾配降下法) 法が推奨されます。
TensorFlow モデルの並列処理
モデルの一部を TensorFlow の特定のデバイスに配置するには、tf.device を使用します .
たとえば、2 つの異なる GPU デバイスで 2 つの線形レイヤーを分割します。
import tensorflow as tf
from tensorflow.keras import layers
with tf.device(‘GPU:0’):
layer1 = layers.Dense(16, input_dim=8)
with tf.device(‘GPU:1’):
layer2 = layers.Dense(4, input_dim=16) PyTorch モデルの並列処理
nn.Module.to を使用して、モデルの一部を PyTorch の別のデバイスに移動します メソッド。
たとえば、2 つの線形レイヤーを 2 つの異なる GPU に移動します。
import torch.nn as nn layer1 = nn.Linear(8,16).to(‘cuda:0’) layer2 = nn.Lienar(16,4).to(‘cuda:1’)
TensorFlow データの並列処理
TensorFlow で同期 SGD を行うには、 tf.distribute.MirroredStrategy() で分散戦略を設定します モデルの初期化をラップします:
import tensorflow as tf strategy = tf.distribute.MirroredStrategy() with strategy.scope(): model = … model.compile(...)
ラッパーでモデルをコンパイルした後、通常どおりモデルをトレーニングします。
PyTorch データの並列処理
PyTorch での同期 SGD の場合、モデルを torch.nn.DistributedDataParallel でラップします モデルの初期化後、ゼロから始まるデバイス番号ランクを設定します:
from torch.nn.parallel import DistributedDataParallel. model = ... model = model.to() ddp_model = DistributedDataParallel(model, device_ids=[])
6.デバイス管理
デバイスを管理すると、パフォーマンスが大幅に変化します。 PyTorch と TensorFlow はどちらもニューラル ネットワークを適切に適用しますが、実行は異なります。
TensorFlow
GPU が使用可能な場合、TensorFlow は自動的に GPU の使用に切り替えます。 GPU とそのアクセス方法を制御できます。 GPU アクセラレーションは自動化されています。これは、メモリ使用量を制御できないことを意味します。
パイトーチ
PyTorch は CUDA を使用して、GPU または CPU の使用を指定します。モデルは、GPU と CPU を使用するための CUDA 仕様がないと実行されません。 GPU の使用は自動化されていません。つまり、リソースの使用をより適切に制御できます。 PyTorch は、GPU 制御によってトレーニング プロセスを強化します。
7.両方の深層学習プラットフォームの使用例
TensorFlow と PyTorch は、それぞれの会社で最初に使用されました。オープンソースになって以来、Google や Facebook 以外にも多くのユースケースがあります。
TensorFlow
Google Brain Team の Google 研究者は、最初に TensorFlow を Google の研究プロジェクトに使用しました。 Google は次の目的で TensorFlow を使用します:
- 検索結果とオートコンプリート
- 音声テキスト変換および音声技術
- 画像認識と分類
- 機械翻訳システム
- Gmail のスパム検出
Google 以外にも多くのユースケースがあります。例:
- シノベーション ベンチャーズ – 網膜の画像を使用した疾患の分類とセグメンテーション
- PayPal – 深い転移学習と生成モデリングによる不正検出
- チャイナ モバイル – ネットワークの問題検出、自動カットオーバー タイム ウィンドウ予測、操作ログ検証のためのディープ ラーニング システム
パイトーチ
PyTorch は、Facebook AI Researchers Lab (FAIR) によって Facebook で最初に使用されました。 Facebook は PyTorch を次の目的で使用します:
- 顔認識と物体検出
- スパム フィルタリングとフェイク ニュースの検出
- ニュースフィードの自動化と友達提案システム
- 音声認識。
- 機械翻訳システム
PyTorch はオープン ソースです。現在、次のような Facebook 以外の多くのユース ケースがあります。
- CheXNet – 畳み込みニューラル ネットワークを使用した肺炎確率スコアリングと胸部 X 線ヒートマップ。
- テスラ オートパイロット – 自動運転車向けのリアルタイム コンピュータ ビジョン マルチタスキング
- Uber AI Labs PYRO – 深い確率モデリングのための確率プログラミング言語。顧客とドライバー、最適なルート、次世代のインテリジェント車両とのマッチングの予測と最適化
PyTorch または TensorFlow を使用する必要がありますか?
PyTorch は、プログラマーや科学研究者の間で人気のオプションです。科学界は、引用数を見ると PyTorch を好みます。最近の展開機能と運用機能を備えた PyTorch は、研究から運用に移行する際の優れたオプションです。
一般に、組織やスタートアップは TensorFlow を使用します。デプロイと本番機能により、TensorFlow はエンタープライズ ユース ケースで高い評価を得ています。 Tensorboard による視覚化は、クライアントにもエレガントなプレゼンテーションを示します。
PyTorch と TensorFlow は、集中的に開発されている強力なディープ ラーニング ライブラリです。現在、この 2 つには相違点よりも類似点の方が多く、一方から他方への切り替えはシームレスなプロセスです。
クラウドコンピューティング