


広範な信号処理チェーンにより、音声アシスタントが「正しく機能」する方法
スマートスピーカーと音声制御デバイスの人気が高まっており、AmazonのAlexaやGoogleのアシスタントなどの音声アシスタントが私たちのリクエストをよりよく理解できるようになっています。
この種のインターフェースの主な魅力の1つは、「正しく機能する」ことです。学習するユーザーインターフェースがなく、ガジェットを人のように自然言語で話すことが増え、有用な応答を得ることができます。しかし、この機能を実現するために、膨大な量の高度な処理が行われています。
この記事では、音声制御ソリューションのアーキテクチャを確認し、内部で何が起こっているのか、必要なハードウェアとソフトウェアについて説明します。
信号の流れとアーキテクチャ
音声制御デバイスにはさまざまな種類がありますが、基本的な原理と信号の流れは似ています。 AmazonのEchoなどのスマートスピーカーを検討し、関連する主要な信号処理サブシステムとモジュールを見てみましょう。
図1は、スマートスピーカーのシグナルチェーン全体を示しています。
クリックすると拡大画像が表示されます
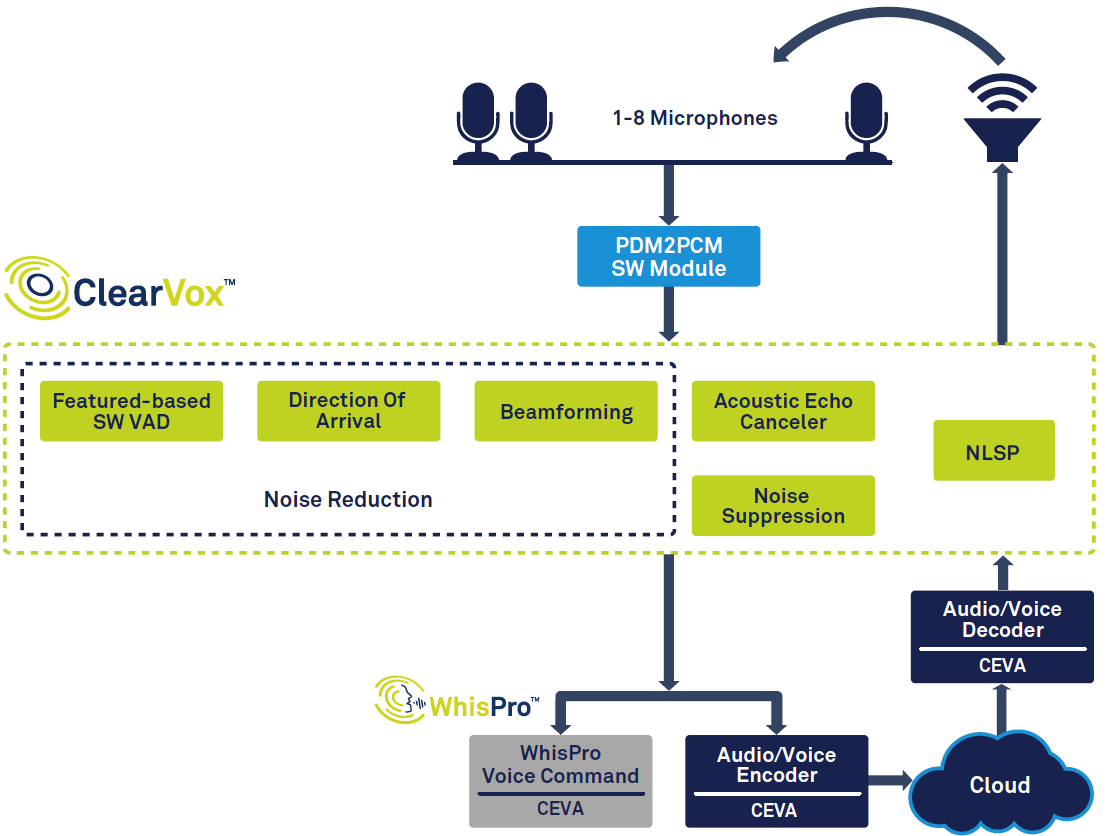
図1:CEVAのClearVoxとWhisProに基づく音声アシスタントのシグナルチェーン。 (出典:CEVA)
図の左側から、音声アクティビティ検出(VAD)を使用して音声が検出されると、音声がデジタル化され、複数の信号処理ステージを通過して、目的のメインスピーカーの音声からの音声の明瞭さが向上することがわかります。到着方向。次に、デジタル化されて処理された音声データは、バックエンドの音声処理に渡されます。これは、一部はエッジ(デバイス上)で、一部はクラウドで行われる場合があります。最後に、必要に応じて応答が作成され、スピーカーによって出力されます。これには、デコードとデジタルからアナログへの変換が必要です。
他のアプリケーションでは、いくつかの違いがあり、優先順位が異なる場合があります。たとえば、車内の音声インターフェイスは、車の一般的なバックグラウンドノイズを処理するように最適化する必要があります。また、インイヤー型の「ヒアラブル」や低コストの家電製品などの小型デバイスの需要に牽引されて、電力の削減とコストの削減に向けた全体的な傾向もあります。
フロントエンド信号処理
音声が検出されてデジタル化されると、複数の信号処理タスクが必要になります。外部ノイズだけでなく、音楽を出力するスマートスピーカーや、回線の反対側で話している人との会話など、リスニングデバイスによって生成される音も考慮する必要があります。これらの音を抑制するために、デバイスは音響エコーキャンセレーション(AEC)を使用します。これにより、ユーザーは、すでに音楽を再生しているときや話しているときでも、スマートスピーカーに割り込んで割り込むことができます。これらのエコーが除去されると、ノイズ抑制アルゴリズムを使用して外部ノイズがクリーンアップされます。
さまざまなアプリケーションがありますが、音声制御デバイスの場合は、近距離場と遠距離場の音声ピックアップの2つのグループに一般化できます。ヘッドセット、イヤフォン、ヒアラブル、ウェアラブルなどのニアフィールドデバイスは、ユーザーの口の近くに保持または装着されますが、スマートスピーカーやテレビなどのファーフィールドデバイスは、部屋の向こう側からユーザーの声を聞くように設計されています。
ニアフィールドデバイスは通常、1つまたは2つのマイクを使用しますが、ファーフィールドデバイスは3〜8のどこかを使用することがよくあります。この理由は、遠方界のデバイスが近方界よりも多くの課題に直面しているためです。ユーザーが遠くに移動すると、マイクに到達する音声は徐々に静かになり、バックグラウンドノイズは同じレベルに保たれます。同時に、デバイスは直接音声信号を壁やその他の表面での反射、つまり残響から分離する必要もあります。
これらの問題を処理するために、遠方界デバイスはビームフォーミングと呼ばれる手法を採用しています。これは複数のマイクを使用し、各マイクに到達する音声信号間の時間差に基づいて音源の方向を計算します。これにより、デバイスは反射やその他の音を無視し、ユーザーの声を聞くだけでなく、ユーザーの動きを追跡し、複数の人が話している正しい音声にズームインできます。
スマートスピーカーの場合、もう1つの重要なタスクは、「Alexa」などの「トリガー」単語を認識することです。話者は常に耳を傾けているため、このトリガー認識はプライバシーの問題を引き起こします。ユーザーの音声が常にクラウドにアップロードされている場合、トリガーワードを言わなくても、AmazonやGoogleがすべての会話を聞いても安心ですか。代わりに、トリガー認識や、スマートスピーカー自体でローカルに「音量を上げる」などの多くの一般的なコマンドを処理することが望ましい場合があります。音声は、ユーザーがより複雑なコマンドを開始した後にのみクラウドに送信されます。
最後に、クリーンな音声サンプルをエンコードしてから、最終的にクラウドバックエンドに送信してさらに処理する必要があります。
特殊なソリューション
上記の説明から、フロントエンドの音声処理で多くのタスクを処理できる必要があることは明らかです。これを迅速かつ正確に行う必要があります。また、バッテリ駆動のデバイスの場合、デバイスが常にトリガーワードをリッスンしている場合でも、消費電力を最小限に抑える必要があります。
これらの要求を満たすために、汎用デジタルシグナルプロセッサ(DSP)またはマイクロプロセッサは、コスト、処理パフォーマンス、サイズ、および消費電力の点で、その役目を果たすことはほとんどありません。代わりに、より良いソリューションは、専用のオーディオ処理機能と最適化されたソフトウェアを備えたアプリケーション固有のDSPである可能性があります。音声入力タスク用にすでに最適化されているハードウェア/ソフトウェアソリューションを選択すると、開発コストが削減され、市場投入までの時間が大幅に短縮されるだけでなく、全体的なコストも削減されます。
たとえば、CEVAのClearVoxは、音声入力処理アルゴリズムのソフトウェアスイートであり、スピーカーの音声の到着方向、マルチマイクビームフォーミング、ノイズ抑制、音響エコーキャンセレーションなど、さまざまな音響シナリオとマイク構成に対応できます。 ClearVoxは、CEVAサウンドDSPで効率的に実行するように最適化されており、費用効果の高い低電力ソリューションを提供します。
音声処理だけでなく、エッジデバイスにはトリガーワード検出を処理する機能が必要です。 CEVAのWhisProなどの特殊なソリューションは、必要な精度と低消費電力を実現するための優れた方法です(図2を参照)。 WhisProは、ニューラルネットワークベースの音声認識ソフトウェアパッケージであり、CEVAのDSP専用に利用できます。これにより、OEMは音声対応製品に音声アクティベーションを追加できます。メインプロセッサが必要になるまでスリープ状態を維持しながら、必要な常時オンのリスニングを処理できるため、システム全体の消費電力を大幅に削減できます。
クリックすると拡大画像が表示されます
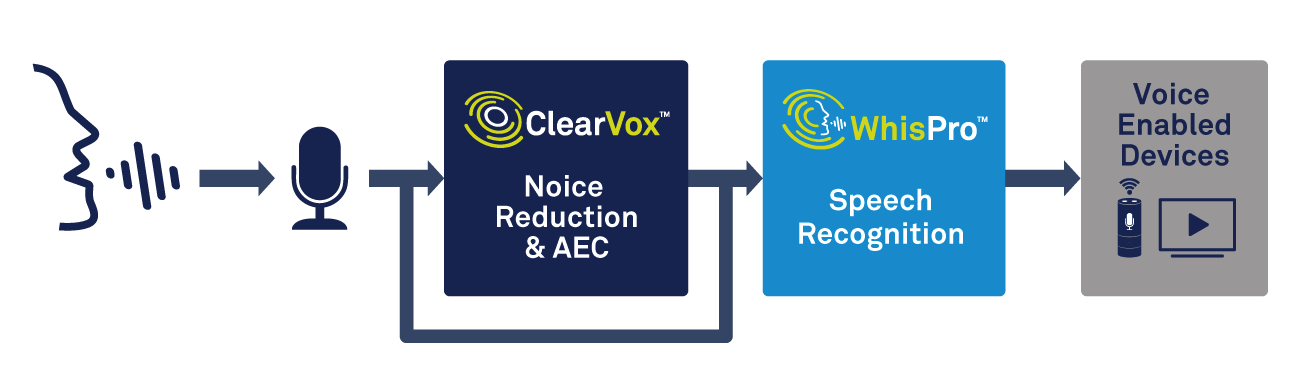
図2:音声アクティベーションに音声処理と音声認識を使用する。 (出典:CEVA)
WhisProは、95%以上の認識率を達成でき、複数のトリガーフレーズ、およびカスタマイズされたトリガーワードをサポートできます。スマートスピーカーを使用したことのある人なら誰でも証言できるように、騒がしい環境でも、ウェイクワードに確実に応答するようにすることは、苛立たしい経験になることがあります。この機能を正しく利用することで、消費者が音声制御製品の品質をどのように認識するかに大きな違いをもたらすことができます。
音声認識:ローカルまたはクラウド
音声がデジタル化されて処理されたら、ある種の自動音声認識(ASR)機能が必要になります。 ASRテクノロジーには、ユーザーが特定のキーワードを言う必要がある単純なキーワード検出から、ユーザーが他の人に話しかけるように普通に話すことができる高度な自然言語処理(NLP)まで、幅広いものがあります。
キーワード検出には、語彙が非常に限られている場合でも、多くの用途があります。たとえば、電灯のスイッチやサーモスタットなどのシンプルなスマートホームデバイスは、「オン」、「オフ」、「明るい」、「調光」などのいくつかのコマンドに応答するだけです。このレベルのASRは、インターネットに接続しなくても、エッジでローカルに簡単に処理できるため、コストを抑え、迅速な対応を保証し、セキュリティとプライバシーの懸念を回避できます。
もう1つの例は、多くのAndroidスマートフォンに「チーズ」または「笑顔」と言って写真を撮るように指示できる場合です。この場合、コマンドをクラウドに送信するのに時間がかかりすぎます。これは、インターネット接続が利用可能であることを前提としています。これは、スマートウォッチやヒアラブルなどのデバイスに常に当てはまるとは限りません。
一方、多くのアプリケーションはNLPを必要とします。 Echoスピーカーに天気について尋ねたい場合、または今夜のホテルを見つけたい場合は、さまざまな方法で質問を表現できます。デバイスは、コマンドで考えられるニュアンスや口語表現を理解し、求められていることを確実に理解できる必要があります。簡単に言えば、音声をテキストに変換するだけでなく、音声を意味に変換できる必要があります。
ホテルに関するお問い合わせを例にとると、価格、場所、レビューなど、さまざまな要因についてお尋ねいただけます。 NLPシステムは、この複雑さのすべてに加えて、質問の言い回しのさまざまな方法を解釈する必要があります。また、リクエストからの明確さの欠如-「私に良い価値を見つけてください、中央ホテル」とは、異なることを意味します人。正確な結果を得るには、デバイスが質問のコンテキストを考慮し、ユーザーが接続されたフォローアップ質問をしたり、1つのクエリ内で複数の情報を要求したりするタイミングを認識する必要もあります。
これには大量の処理が必要になる可能性があり、通常は人工知能(AI)とニューラルネットワークを使用しますが、ほとんどの場合、エッジでの処理には実用的ではありません。プロセッサが組み込まれた低コストのデバイスには、必要なタスクを処理するのに十分な電力がありません。この場合、正しいオプションは、クラウドで処理するためにデジタル化された音声を送信することです。そこで、それを解釈し、適切な応答を音声制御デバイスに送り返すことができます。
デバイスでのエッジ処理とクラウドでのリモート処理の間にはトレードオフがあることがわかります。すべてをローカルで処理する方が高速であり、インターネット接続に依存していませんが、幅広い質問や情報の取得に対処するのに苦労します。つまり、家庭用のスマートスピーカーなどの汎用デバイスの場合、少なくとも一部の処理をクラウドにプッシュする必要があります。
クラウド処理の欠点に対処するために、ローカルプロセッサの機能が開発されており、近い将来、エッジデバイスのNLPとAIが大幅に改善されることが期待できます。新しい技術により、必要なメモリの量が削減され、プロセッサは引き続き高速になり、消費電力が少なくなります。
たとえば、CEVAの低電力AIプロセッサのNeuProファミリは、エッジに高度な機能を提供します。コンピュータビジョン用のニューラルネットワークにおけるCEVAの経験に基づいて構築されたこのファミリは、デバイス上の音声処理のための柔軟でスケーラブルなソリューションを提供します。
結論
音声制御インターフェースは急速に私たちの日常生活の重要な部分になりつつあり、近い将来、ますます多くの製品に追加されるでしょう。改善は、ローカルとクラウドの両方で、より優れた信号処理と音声認識機能、およびより強力なコンピューティングリソースによって推進されています。
OEMの要件を満たすには、オーディオ処理と音声認識に使用されるコンポーネントが、パフォーマンス、コスト、および電力の点でいくつかの困難な課題に対応する必要があります。多くの設計者にとって、目前のタスクに合わせて特別に最適化されたソリューションは、エンドカスタマーの要求に応え、市場投入までの時間を短縮するという最善のアプローチを証明する可能性があります。
基盤となるテクノロジーが何であれ、音声インターフェイスはより正確になり、日常の言語で話しやすくなりますが、コストが下がると、製造業者にとってより魅力的なものになります。それらが次に何に使用されるかを確認するのは興味深い旅になるでしょう。
埋め込み