


アナログインメモリコンピューティングがエッジAI推論の電力の課題をどのように解決できるか
機械学習とディープラーニングはすでに私たちの生活に欠かせない要素です。自然言語処理(NLP)、画像分類、オブジェクト検出を介した人工知能(AI)アプリケーションは、私たちが使用する多くのデバイスに深く組み込まれています。ほとんどのAIアプリケーションは、Gmailでメールの返信を入力するときに単語の予測を取得するなど、使用目的に適したクラウドベースのエンジンを介して提供されます。
これらのAIアプリケーションのメリットを享受するだけでなく、このアプローチでは、プライバシー、消費電力、遅延、およびコストの問題が発生します。これらの課題は、データ自体の起点で部分的または完全な計算(推論)を実行できるローカル処理エンジンがあれば解決できます。これは、メモリが電力を大量に消費するボトルネックになる従来のデジタルニューラルネットワークの実装では困難でした。この問題は、マルチレベルメモリと、アナログのメモリ内計算方法を使用することで解決できます。これにより、処理エンジンは、AI推論を実行するためのはるかに低いミリワット(mW)からマイクロワット(uW)の電力要件を満たすことができます。ネットワークのエッジ。
クラウドコンピューティングの課題
AIアプリケーションがクラウドベースのエンジンを介して提供される場合、ユーザーは一部のデータをクラウドにアップロードする必要があります。クラウドでは、コンピューティングエンジンがデータを処理し、予測を提供し、予測をユーザーに送信して消費します。

図1:エッジからクラウドへのデータ転送。 (出典:Microchip Technology)
このプロセスに関連する課題の概要を以下に示します。
- プライバシーとセキュリティの懸念: 常時接続の常時接続デバイスでは、アップロード中またはデータセンターでの保管期間中に、個人データ(および/または機密情報)が悪用されることが懸念されます。
- 不必要な電力損失: すべてのデータビットがクラウドに移行する場合、ハードウェア、無線、送信から電力を消費し、クラウドでの不要な計算に使用される可能性があります。
- 小バッチ推論のレイテンシ: データがエッジで発信されている場合、クラウドベースのシステムから応答を取得するのに1秒以上かかる場合があります。人間の感覚では、100ミリ秒(ms)を超える遅延は目立ち、煩わしい場合があります。
- データ経済は理にかなっている必要があります: センサーはいたるところにあり、非常に手頃な価格です。ただし、それらは大量のデータを生成します。すべてのデータをクラウドにアップロードして処理するのは経済的ではありません。
ローカル処理エンジンを使用してこれらの課題を解決するには、推論操作を実行するニューラルネットワークモデルを最初に、目的のユースケースの特定のデータセットでトレーニングする必要があります。一般に、これには高いコンピューティング(およびメモリ)リソースと浮動小数点算術演算が必要です。その結果、機械学習ソリューションのトレーニング部分は、最適なニューラルネットワークモデルを生成するために、データセットを使用してパブリッククラウドまたはプライベートクラウド(またはローカルGPU、CPU、FPGAファーム)で実行する必要があります。ニューラルネットワークモデルの準備ができたら、ニューラルネットワークモデルは推論操作のためにバックプロパゲーションを必要としないため、モデルは小さなコンピューティングエンジンを備えたローカルハードウェア用にさらに最適化できます。推論エンジンは通常、積和(MAC)エンジンの海を必要とし、その後に、ニューラルネットワークモデルの複雑さに応じて、正規化線形ユニット(ReLU)、シグモイド、タンなどのアクティベーションレイヤーと、レイヤー間のプーリングレイヤーが続きます。
ニューラルネットワークモデルの大部分は、膨大な量のMAC操作を必要とします。たとえば、比較的小さな「1.0 MobileNet-224」モデルでさえ、420万のパラメーター(重み)があり、推論を実行するには5億6900万のMAC操作が必要です。ほとんどのモデルはMAC演算によって支配されているため、ここでは機械学習計算のこの部分に焦点を当て、より優れたソリューションを作成する機会を模索します。以下の図2に、完全に接続された単純な2層ネットワークを示します。
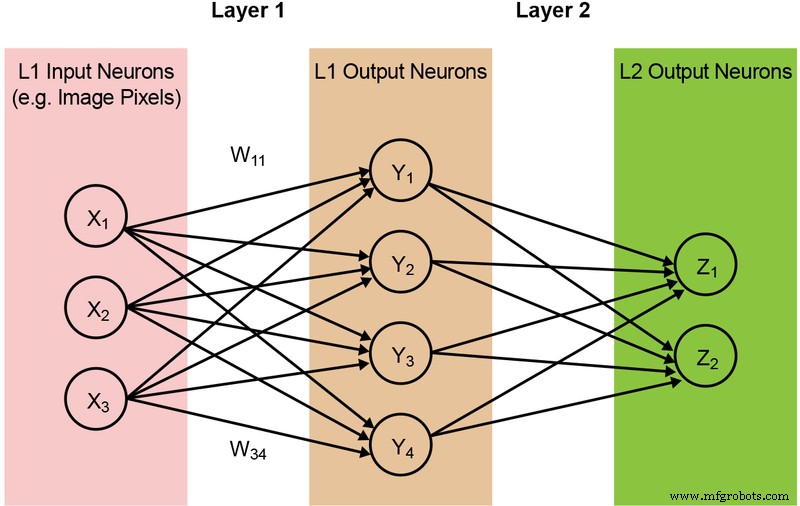
図2:2層の完全に接続されたニューラルネットワーク。 (出典:Microchip Technology)
入力ニューロン(データ)は、重みの最初の層で処理されます。次に、第1層からの出力ニューロンは、第2層の重みで処理され、予測を提供します(たとえば、モデルが特定の画像で猫の顔を見つけることができたかどうか)。これらのニューラルネットワークモデルは、すべての層のすべてのニューロンの計算に「内積」を使用します。これは、次の式で示されます(簡略化のために式の「バイアス」項を省略)。
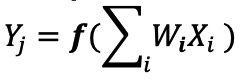
メモリ デジタルコンピューティングのボトルネック
デジタルニューラルネットワークの実装では、重みと入力データはDRAM / SRAMに保存されます。重みと入力データは、推論のためにMACエンジンに移動する必要があります。以下の図3に示すように、このアプローチでは、モデルパラメータをフェッチし、実際のMAC演算が行われるALUにデータを入力する際にほとんどの電力が消費されます。
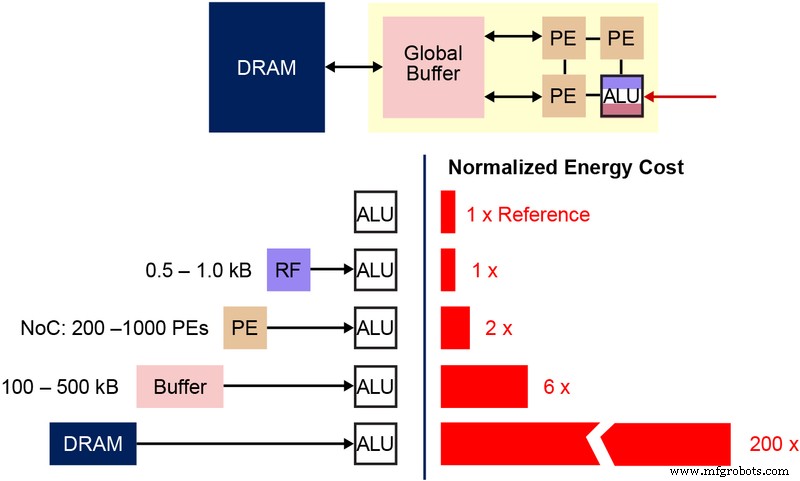
図3:機械学習計算におけるメモリのボトルネック。 (出典:Y.-H。Chen、J。Emer、V。Sze、「Eyeriss:畳み込みニューラルネットワークのエネルギー効率の高いデータフローのための空間アーキテクチャ」、ISCA、2016年)
エネルギーの観点から見ると、デジタル論理ゲートを使用する一般的なMAC演算では、約250フェムトジュール(fJ、または10 -15 )が消費されます。 ジュール)のエネルギーですが、データ転送中に消費されるエネルギーは、計算自体より2桁以上大きく、50ピコジュール(pJ、または10 -12 )の範囲になります。 ジュール)から100pJまで。公平を期すために、メモリからALUへのデータ転送を最小限に抑えるために利用できる多くの設計手法があります。ただし、デジタルスキーム全体は依然としてフォンノイマンアーキテクチャによって制限されているため、これは無駄な電力を削減する大きな機会を提供します。 MAC操作を実行するためのエネルギーを約100pJから数分の1pJに減らすことができるとしたらどうでしょうか?
アナログインメモリコンピューティングによるメモリのボトルネックの解消
メモリ自体を使用して計算に必要な電力を削減できる場合、エッジで推論操作を実行すると電力効率が向上します。インメモリ計算方式を使用すると、移動する必要のあるデータの量が最小限に抑えられます。これにより、データ転送中に無駄になるエネルギーが排除されます。超低有効電力損失で動作できるフラッシュセルを使用すると、エネルギー損失がさらに最小限に抑えられ、スタンバイモード中のエネルギー損失はほとんどありません。
このアプローチの例は、MicrochipTechnologyの会社であるSiliconStorage Technology(SST)のmemBrain™テクノロジーです。 SSTのSuperFlash ® に基づく メモリテクノロジーのソリューションには、推論モデルの重みが格納されている場所で計算を実行できるようにするインメモリコンピューティングアーキテクチャが含まれています。これにより、ウェイトのデータ移動がないため、MAC計算でのメモリのボトルネックが解消されます。入力データのみが、カメラやマイクなどの入力センサーからメモリアレイに移動する必要があります。
このメモリの概念は、2つの基本に基づいています。(a)トランジスタからのアナログ電流応答は、そのしきい値電圧(Vt)と入力データに基づいています。(b)キルヒホッフの電流法則は、ある地点で集まる指揮者のネットワークはゼロです。
このマルチレベルメモリアーキテクチャで使用される基本的な不揮発性メモリ(NVM)ビットセルを理解することも重要です。下の図(図4)は、2つのESF3(Embedded SuperFlash 3 rd )の断面図です。 生成)共有消去ゲート(EG)およびソースライン(SL)を備えたビットセル。各ビットセルには、コントロールゲート(CG)、ワークライン(WL)、イレースゲート(EG)、ソースライン(SL)、ビットライン(BL)の5つの端子があります。ビットセルの消去動作は、EGに高電圧を印加することによって行われます。プログラミング操作は、WL、CG、BL、およびSLに高/低電圧バイアス信号を適用することによって行われます。読み出し動作は、WL、CG、BL、SLに低電圧バイアス信号を印加することで行います。
図4:SuperFlashESF3セル。 (出典:Microchip Technology)
このメモリアーキテクチャを使用すると、ユーザーはきめ細かいプログラミング操作によってさまざまなVtレベルでメモリビットセルをプログラムできます。メモリテクノロジは、スマートアルゴリズムを利用して、メモリセルのフローティングゲート(FG)Vtを調整し、入力電圧から特定の電流応答を実現します。エンドアプリケーションの要件に応じて、セルは線形またはしきい値以下の動作領域でプログラムできます。
図5は、メモリセルに複数のレベルを保存および読み取る機能を示しています。 2ビット整数値をメモリセルに格納しようとしているとしましょう。このシナリオでは、2ビット整数値(00、01、10、11)の4つの可能な値のいずれかを使用して、メモリ配列内の各セルをプログラムする必要があります。以下の4つの曲線は、4つの可能な状態のそれぞれのIV曲線であり、セルからの電流応答は、CGに印加される電圧に依存します。
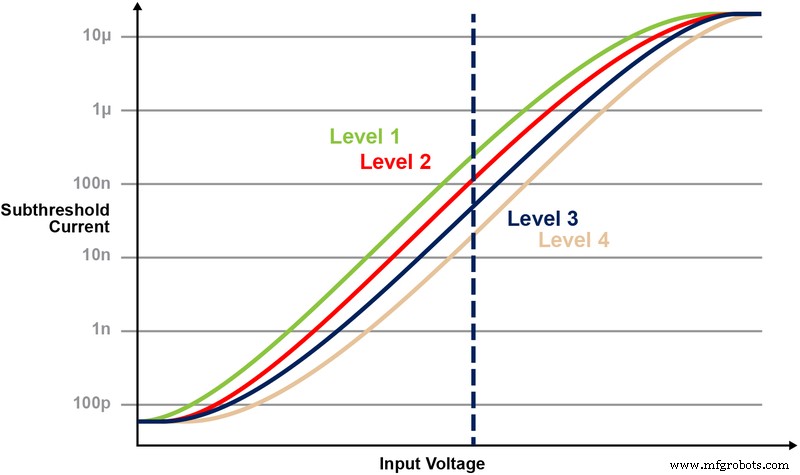
図5:ESF3セルでのVtレベルのプログラミング。 (出典:Microchip Technology)
インメモリコンピューティングによる積和演算
各ESF3セルは、可変コンダクタンス(g m )としてモデル化できます。 )。 ESF3セルのコンダクタンスは、プログラムされたセルのフローティングゲートVtに依存します。トレーニングされたモデルからの重みは、メモリセルのフローティングゲートVtとしてプログラムされているため、g m セルのは、トレーニングされたモデルの重みを表します。 ESF3セルに入力電圧(Vin)が印加されると、出力電流(Iout)は次の式で与えられます。Iout=g m * Vinは、入力電圧とESF3セルに保存されている重量の間の乗算演算です。
下の図6は、同じ列に接続された(セルからの(乗算演算からの)出力電流を加算することによって累積演算が実行される、小さなアレイ構成(2×2アレイ)での積和演算の概念を示しています(たとえば、I1 =I11 + I21)。アプリケーションに応じて、アクティベーション機能はADCブロック内で実行することも、メモリブロック外のデジタル実装で実行することもできます。
クリックすると拡大画像が表示されます
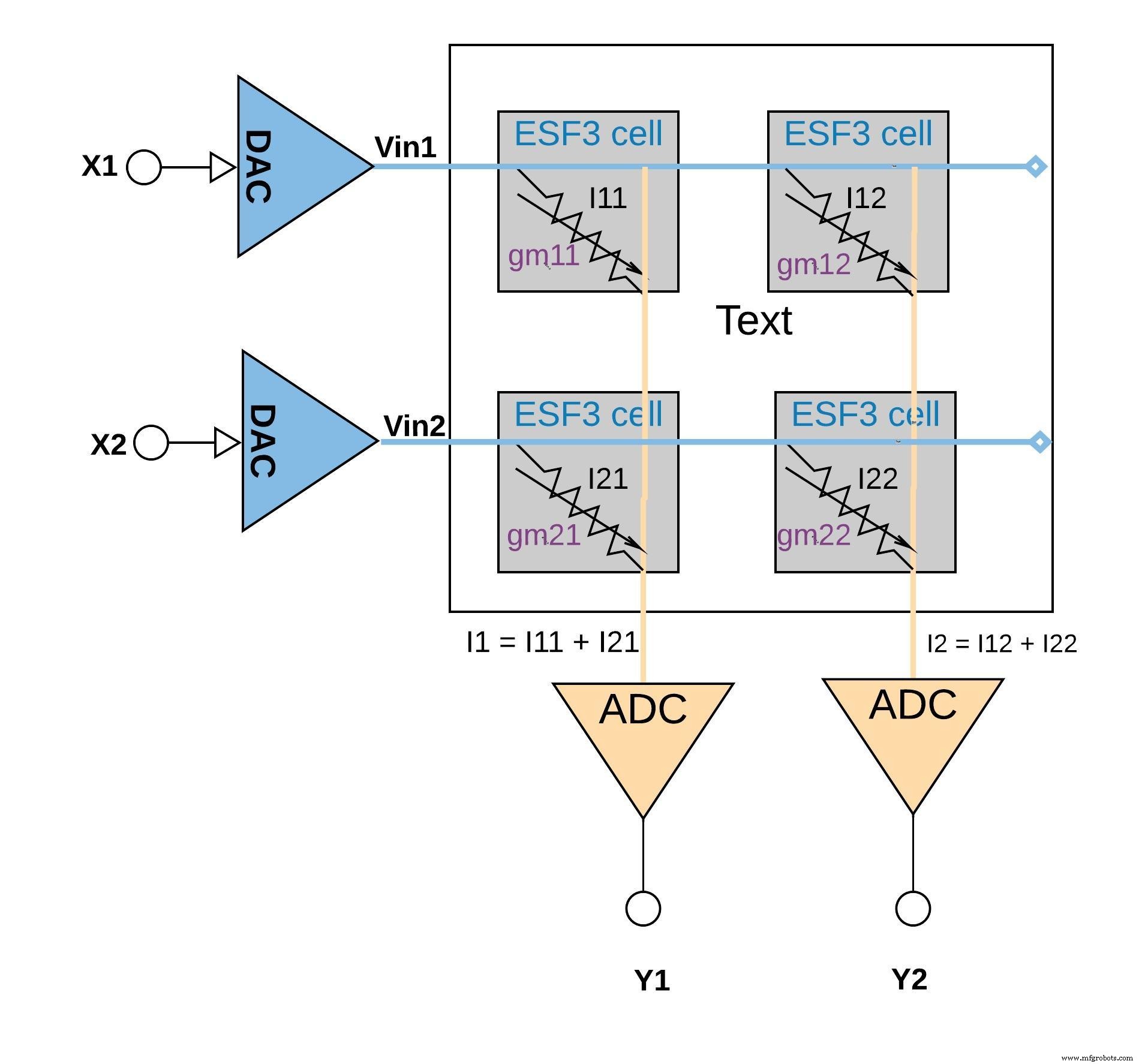
図6:ESF3アレイ(2×2)を使用した積和演算。 (出典:Microchip Technology)
より高いレベルで概念をさらに説明するため。トレーニングされたモデルからの個々の重みは、メモリセルのフローティングゲートVtとしてプログラムされるため、トレーニングされたモデルの各層(たとえば、完全に接続された層)からのすべての重みは、物理的に重み行列のように見えるメモリ配列にプログラムできます。 、図7に示すように。
クリックすると拡大画像が表示されます
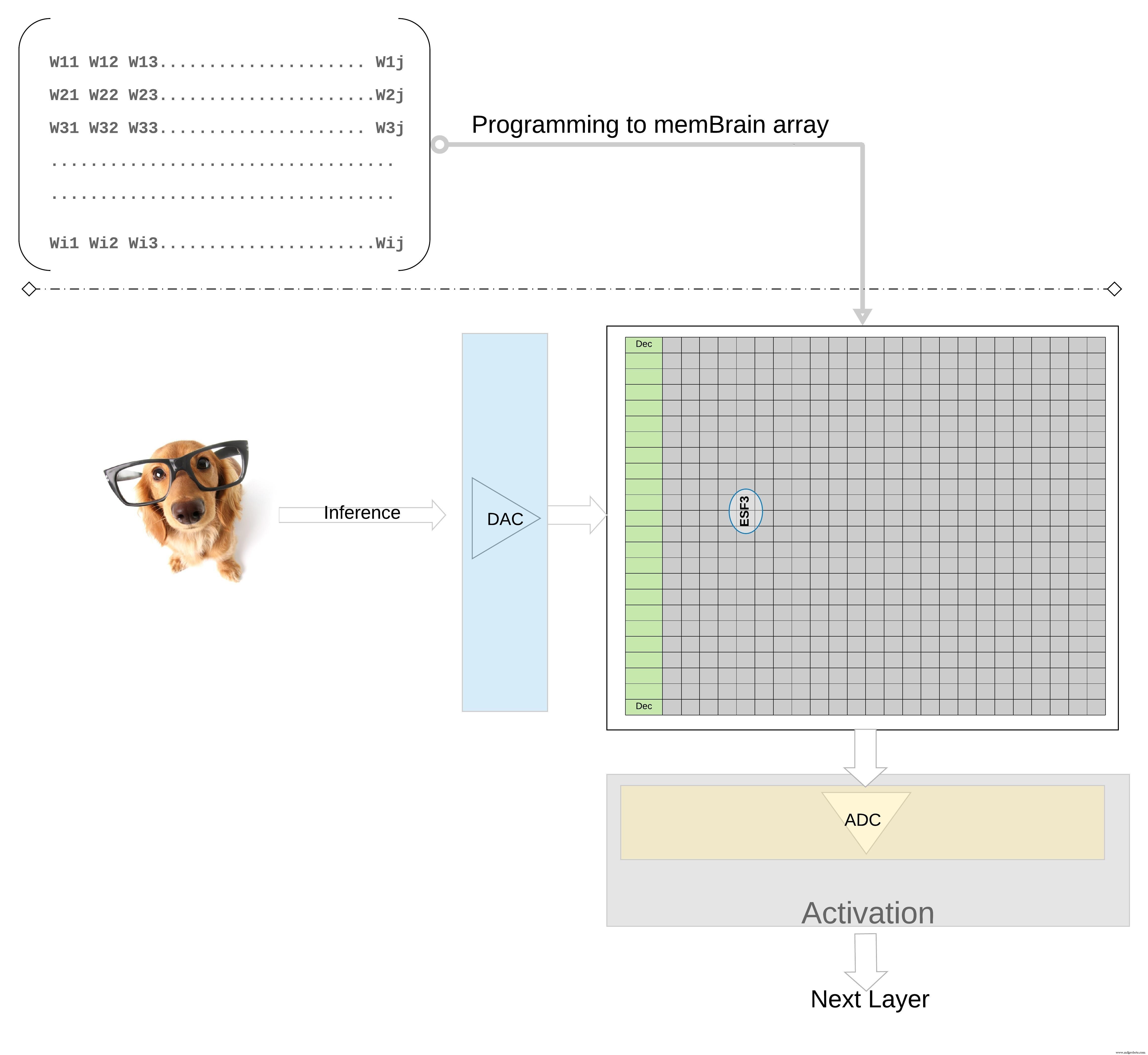
図7:推論用の重み行列メモリ配列。 (出典:Microchip Technology)
推論操作の場合、デジタル入力、たとえば画像ピクセルは、最初にデジタル-アナログコンバーター(DAC)を使用してアナログ信号に変換され、メモリアレイに適用されます。次に、アレイは、指定された入力ベクトルに対して何千ものMAC操作を並行して実行し、それぞれのニューロンの活性化段階に進むことができる出力を生成します。出力は、アナログ-デジタルコンバーター(ADC)を使用してデジタル信号に変換し直すことができます。次に、デジタル信号は次のレイヤーに進む前にプール用に処理されます。
このタイプのメモリアーキテクチャは、非常にモジュール化されており、柔軟性があります。図8に示すように、多くのmemBrainタイルをつなぎ合わせて、重み行列とニューロンを組み合わせたさまざまな大きなモデルを構築できます。この例では、3×4タイル構成を、アナログとデジタルのファブリックでつなぎ合わせています。タイル、およびデータは共有バスを介して1つのタイルから別のタイルに移動できます。
クリックすると拡大画像が表示されます
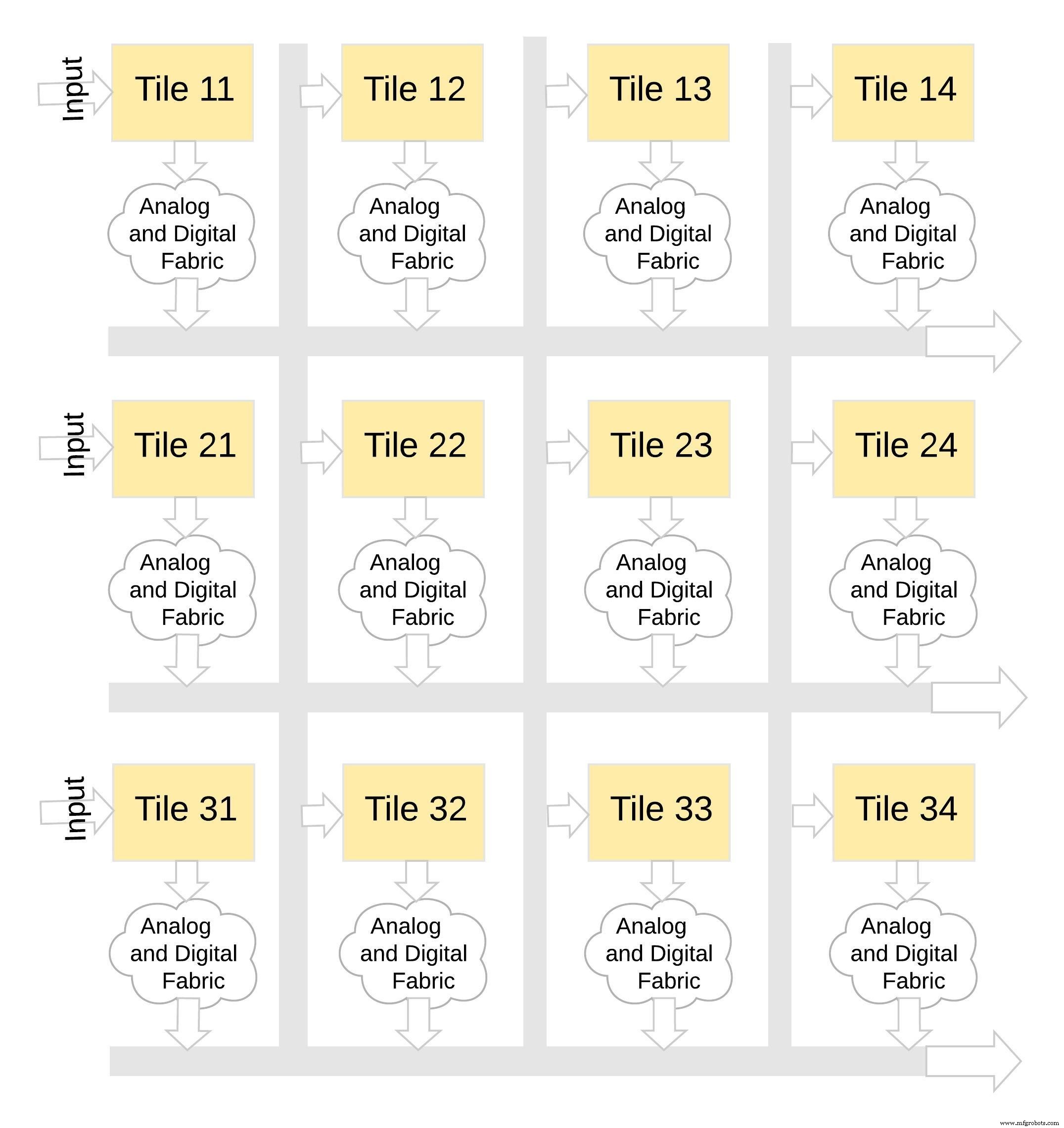
図8:memBrain™はモジュラーです。 (出典:Microchip Technology)
これまで、主にこのアーキテクチャのシリコン実装について説明してきました。ソフトウェア開発キット(SDK)の可用性(図9)は、ソリューションの展開に役立ちます。シリコンに加えて、SDKは推論エンジンの展開を容易にします。
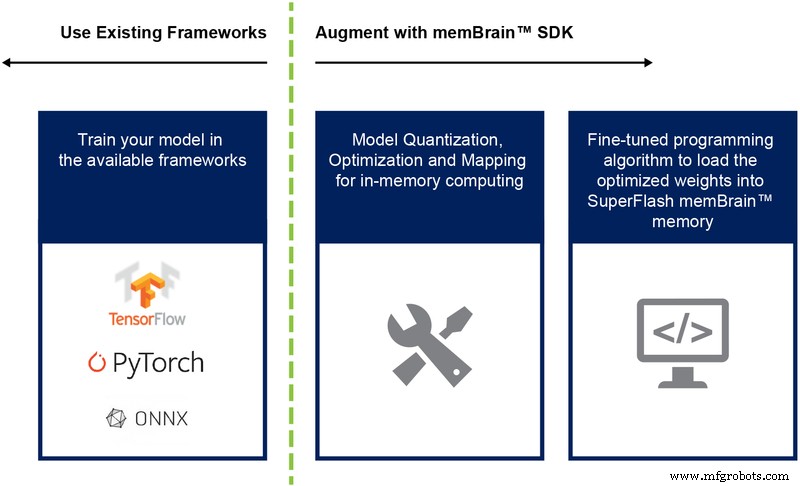
図9:memBrain™SDKフロー。 (出典:Microchip Technology)
SDKフローは、トレーニングフレームワークに依存しません。ユーザーは、必要に応じて浮動小数点計算を使用して、TensorFlow、PyTorchなどの利用可能なフレームワークのいずれかでニューラルネットワークモデルを作成できます。モデルが作成されると、SDKは、トレーニングされたニューラルネットワークモデルを量子化し、センサーまたはコンピューターからの入力ベクトルを使用してベクトル行列の乗算を実行できるメモリ配列にマッピングするのに役立ちます。
結論
インメモリコンピューティング機能を備えたこのマルチレベルメモリアプローチの利点は次のとおりです。
- 極端な低電力: このテクノロジーは、低電力アプリケーション向けに設計されています。第1レベルの電力の利点は、ソリューションがインメモリコンピューティングであるという事実に由来するため、計算中にSRAM / DRAMからのデータと重みの転送にエネルギーが浪費されることはありません。 2番目のエネルギーの利点は、フラッシュセルが非常に低い電流値でサブスレッショルドモードで動作しているため、有効電力損失が非常に低いという事実に起因します。 3番目の利点は、不揮発性メモリセルが常時接続デバイスのデータを保持するために電力を必要としないため、スタンバイモード中のエネルギー消費がほとんどないことです。このアプローチは、重みと入力データのスパース性を利用するのにも適しています。入力データまたは重みがゼロの場合、メモリビットセルはアクティブ化されません。
- パッケージのフットプリントを小さくする: このテクノロジはスプリットゲート(1.5T)セルアーキテクチャを使用しますが、デジタル実装のSRAMセルは6Tアーキテクチャに基づいています。さらに、セルは6TSRAMセルと比較してはるかに小さいビットセルです。さらに、4 * 6 =24個のトランジスタを必要とするSRAMセルとは異なり、1つのセルセルで4ビット整数値全体を格納できます。これにより、オンチップのフットプリントが大幅に小さくなります。
- 開発コストの削減: メモリパフォーマンスのボトルネックとフォンノイマンアーキテクチャの制限により、多くの専用デバイス(NvidiaのJetsenやGoogleのTPUなど)は、ワットあたりのパフォーマンスを向上させるために小さなジオメトリを使用する傾向があります。これは、エッジAIコンピューティングの課題を解決するための費用のかかる方法です。アナログオンメモリ計算方法を使用したマルチレベルメモリアプローチでは、計算はフラッシュセルでオンチップで実行されるため、より大きなジオメトリを使用して、マスクコストとリードタイムを削減できます。
エッジコンピューティングアプリケーションは大きな期待を示しています。それでも、エッジコンピューティングが軌道に乗る前に、解決すべき電力とコストの課題があります。フラッシュセルでオンチップで計算を実行するメモリアプローチを使用することで、主要なハードルを取り除くことができます。このアプローチは、機械学習アプリケーション向けに最適化された、生産実績のあるデファクトスタンダードタイプのマルチレベルメモリテクノロジーソリューションを利用しています。
埋め込み
- エッジコンピューティングがエンタープライズITにどのように役立つか
- クラウドコンピューティングはITスタッフにどのようなメリットをもたらしますか?
- エッジコンピューティングの概要とユースケースの例
- エッジコンピューティング:5つの潜在的な落とし穴
- IIoTデータがリーン生産方式の収益性をどのように高めることができるか
- エッジに近い:エッジコンピューティングがインダストリー4.0をどのように推進するか
- 停電が電源装置にどのように損傷を与える可能性があるか
- エッジコンピューティングを採用する6つの理由
- エッジコンピューティングと5Gは企業を拡大します
- コネクテッドテクノロジーがサプライチェーンの課題の解決にどのように役立つか
- 小規模ショップがデジタル化する方法 — 経済的に!