


ハイブリッドアーキテクチャはAI、ビジョンワークロードを高速化
新しいハイブリッドデータフローとフォンノイマンアーキテクチャは、以下を含むワークロードを加速できますニューラルネットワーク、機械学習、コンピュータービジョン、DSP、基本的な線形代数サブプログラム。
シリコンバレーの新興企業であるQuadricは、ロボット、ファクトリーオートメーション、医療画像などのエッジデバイス向けにAIと標準のコンピュータービジョンアルゴリズムの両方のワークロードを高速化するように設計されたアクセラレータを構築しました。同社のハードウェアアーキテクチャは、ニューラルネットワーク、機械学習、コンピュータビジョン、DSP、基本的な線形代数サブプログラムなどのワークロードを処理できる、新しいハイブリッドデータフローとフォンノイマンの設計です。
「最初から、エッジデバイスでのオンデバイスコンピューティングに必要なアプリケーションはAIだけではないことを非常に認識していました」と、QuadricのCEOであるVeerbhanKheterpalは EE Times に語りました。 。 「これらの製品の開発者は、システム全体がAIとともに従来の高性能コンピューティングアルゴリズムを実行できるようにする必要があります。これが完全なシステム要件です。」
Kheterpalは、アーキテクチャは個々のワークロード用のアクセラレータのコレクションではないことを強調しました。むしろ、AI推論など、さまざまなワークロードを高速化するように設計されたデータ並列命令セットを備えた統合アーキテクチャです。
「AIが最近動いているところでは、レイヤー全体を高速フーリエ変換(FFT)に置き換えることに関して、いくつかの興味深い傾向があります」と、Quadricの最高製品責任者であるDanielFiru氏は述べています。 Quadricは、研究者がいくつかの層をFFTに置き換えることによって変圧器ネットワークを加速した、Googleの最近の論文を引用して、これらのタイプのワークロードを加速するために自らを位置付けています。 Googleは、トランスフォーマーエンコーダーの自己注意サブレイヤーをFFTに置き換えて、BERTベンチマークで92%の精度を達成したネットワークを生成しました。トレーニングは、GPUでは最大7倍、GoogleTPUでは2倍高速でした。

Quadricの開発者キット、Q16プロセッサと4 GBの外部メモリを搭載したM.2カード(出典:Quadric)
ブドウ園のロボット
Quadricの3人の共同創設者であるVeerbhanKheterpal、Daniel Firu、Nigel Dregoは、以前に21を設立し、Coinbaseに売却されたビットコインマイニング会社です。カリフォルニア州バーリンゲームのQuadricは、チップの設計を始めていませんでした。代わりに、元々はナパバレーのブドウ園を上下に歩いてブドウの木を見て、灌漑の漏れや害虫を見つけたときにアラートを送信できる農業用ロボットを構築しました。

Veerbhan Kheterpal(出典:Quadric)
「私たちがそれを構築していたとき、それが5ドルから10,000ドルのドローンサプライチェーンから構築された実行可能な製品ではないことに気づきました」とKheterpalは言いました。 「50,000ドルのトラクターサプライチェーンから構築し、GPUを搭載した大型PCと大量のカメラを搭載する必要があります。そのとき、私たちはすべてのロボット工学ソフトウェアの内部を調べ、このエネルギーを根本的に引き起こしているものがNvidiaやIntelなどのプラットフォームで上昇する必要があることを発見しました。」
Firu氏によると、同社は「私たちが望んでいたチップ」であるアクセラレータチップの構築に軸足を移しました。
2017年にシード資金調達ラウンドが開始され、続いてシリーズAラウンドが開始され、Quadricの主要投資家である日本の自動車Tier-Oneデンソーを含む潜在的な顧客から1,300万ドルが生み出されました。 Quadricの総資金は1800万ドルです。
チューリング完全
Quadric’sは、データフローアーキテクチャから要素を取得し、それらをフォンノイマンマシンの要素と組み合わせる命令駆動型アーキテクチャを採用しています。目的は、エッジデバイスの異種システムをより複雑でないものに置き換えることです。チューリング完全なマシンとして、Quadric Vortexコアは、加速と柔軟性の組み合わせを提供すると同社は主張しています。このアーキテクチャは、コアのアレイに関してスケーラブルであり、高度な(7nmまたは5nm)プロセスノードまで移植可能です。これは、約数百ミリワットから20Wの電力バジェットを持つエッジデバイスアプリケーションに適しています。
同社の最初のチップであるQ16は、16 x16のVortexコアのアレイです。各コアには、行列の乗算とAI計算を実行する機能がありますが、AND、OR、リダクション、シフトなどの操作のための多機能ALUもあります。ソフトウェアを使用すると、開発者はLSTMアクティベーション関数などを含むさまざまなアルゴリズムタイプを表現できます。 If-Then-Elseステートメントはアレイ全体で使用できるため、開発者はきめ細かいスパース性を利用できます。
アレイ内の各コアには、隣接するコアへのシングルサイクルアクセスに加えて、4Kbのコア内メモリへのシングルサイクルアクセスがあります。オンチップメモリもアレイと一緒に含まれているため、コアに低遅延で決定論的なアクセスを提供します。
コアは、Quadricが「単一命令、複数デコード」方式と呼ぶ方法で並列に動作します。各コアは、すべてのサイクルで同じ命令を取得します。ただし、実行時の動的データに基づいて、各コアはその命令を異なる方法で解釈できます。これにより、コアまたはコアのグループがわずかに異なる機能を実行できるようになります。
また、アレイへの帯域幅を最適化し、ニューラルネットワークの重みなどの定数をすべてのコアに一度にブロードキャストするために使用できる専用のブロードキャストバスも含まれています(Firuによると、多くのコンピュータービジョンアルゴリズムにはループ不変情報も含まれています。バスにマッピングされています。
動的な情報は、決定論的なカーネルランタイムを可能にする静的なソフトウェア制御のロードストアユニットを介してアレイに入ります。このデバイスでは、デバイスの任意の2つのエッジからの同時ロードと保存に加えて、ニューラルネットワークの重みを送信するために使用できる1つのエッジからの特別なプロパティが可能です。2つのエッジからのロードと3番目のエッジからの保存を同時に行うことで、コンピューティング実行の実行時間を短縮できます。

Daniel Firu(出典:Quadric)
「片側にロードしてから、垂直側から保管することができます」とFiru氏は述べています。 「これにより、ソフトウェアレベルで非常に興味深いことが起こるようになります。このパラダイムを使用して、データの再マッピングや画像の回転などを開始することもできます。」
一方、オンチップのソフトウェア制御の静的メモリ(キャッシュではない)は、大規模なデータ構造のためのスペースを提供します。 QuadricはこれらへのAPIアクセスを許可するため、開発者は内部で任意のデータ構造を定義できます。 Q16チップでは、メモリは8 GBであり、「そこにあるHDの2つまたは3つのフレームバッファ、またはウェイトのニューラルネットワーク全体」に収まるのに十分です。
ソフトウェアスタック
Quadricは、シリコンの前にソフトウェアスタックを構築しました。 Kheterpal氏によると、顧客は同社のアーキテクチャシミュレーターまたはFPGAで1年間使用しています。 Quadricのスタックは、C ++ APIを搭載した、LLVMベースのコンパイラを介してアーキテクチャと命令セットを抽象化します。
ソースモードは、プロセッサのアーキテクチャ機能のソースレベルのC ++制御により、さまざまなデータ並列アルゴリズムをサポートします。ニューラルネットワークがより複雑になるにつれて、ソースモードでは開発者がカスタム操作を表現することもできます。
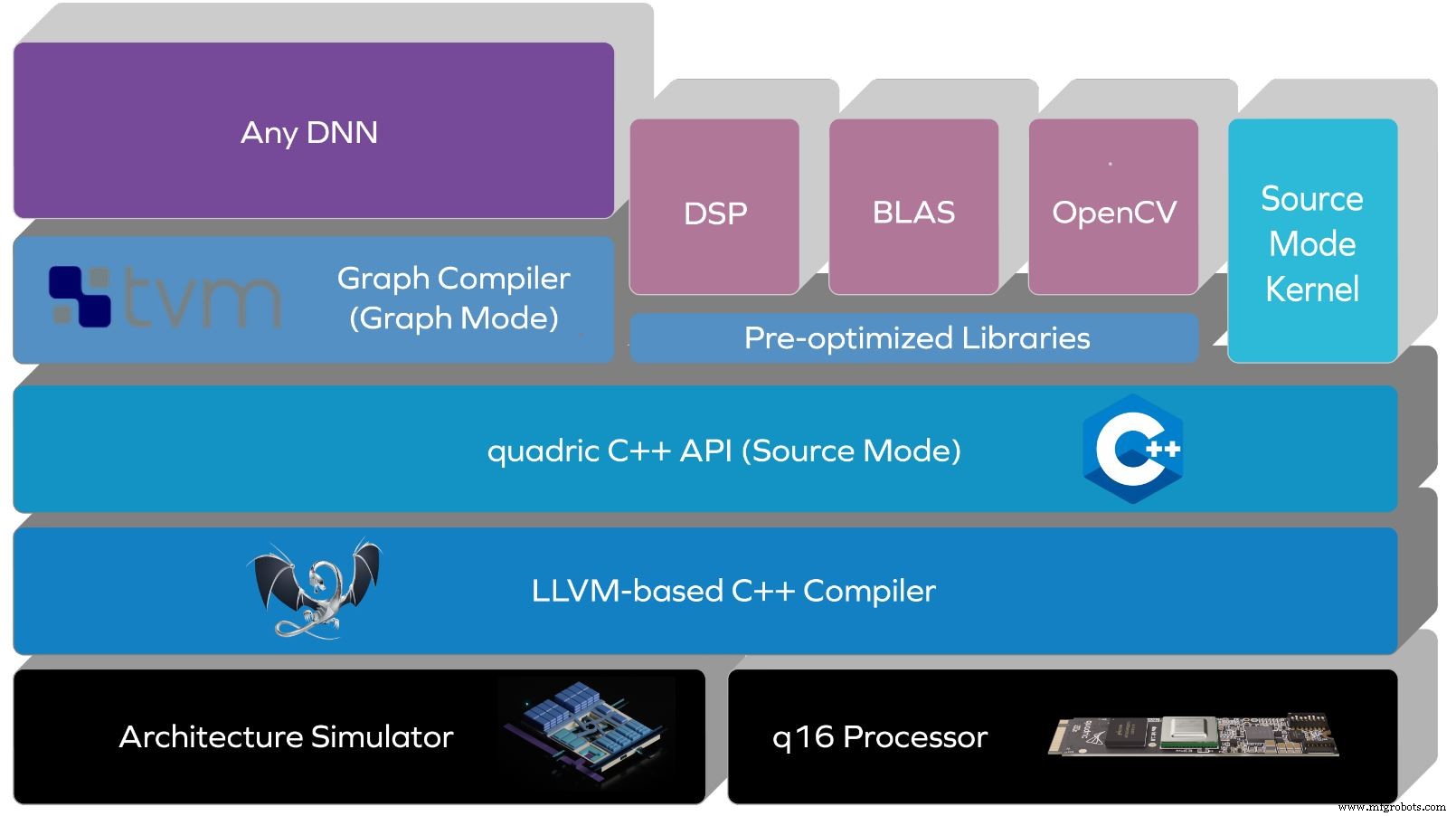
Quadricのソフトウェアスタック(出典:Quadric)
スタックの将来のアップデートでは、コードなしのグラフモードが提供され、ニューラルネットワークのTensorFlowまたはONNXバージョンがサポートされます。これには、コードを自動的に生成するTVMベースのディープニューラルネットワーク(DNN)コンパイラが含まれます。
「私たちはノーコードの力と独自のカスタムコードを持つ柔軟性を組み合わせており、それらを興味深い方法で組み合わせてアプリケーションを実現しています」とKheterpal氏は述べています。 「ほとんどのプラットフォームは、ある種のDNNコンパイラを備えたAI固有のアーキテクチャしか提供しませんが、カスタマイズについてはどうでしょうか。サポートされていないDNNはどうですか?サポートされていない演算子はどうですか?これはチューリング完全コアであるため、これらの制限はありません。コアは任意の操作を実行できます。コードの柔軟性により、開発者は必要なアルゴリズムを記述できます。」
チップロードマップ
QuadricのQ16チップは、16nmシリコンの16x 16アレイに256個のVortexコアを搭載し、4つのINT8 DNNTOPを提供します。 ResNet-50を毎秒200回の推論で実行でき(224 x 224の画像サイズのINT8パラメータの場合)、平均2Wを消費します。
Quadricのロードマップには、第2世代のアーキテクチャに加えて、「おそらく7 nmの」Q32チップ(1,000コアのアレイ)のテープアウトが含まれています。 Q16は厳密にはアクセラレータですが(システムホストプロセッサと並んで配置されます)、開発中のQ32には、ホストとして機能するArmコアまたはRISC-Vコアも含まれる場合があります。
Q16プロセッサとQ16のユニバーサルメモリスペースに直接マッピングされた4GBの外部メモリを備えたM.2形式の開発者キットが利用可能になりました。
>>この記事は、もともと姉妹サイトEEで公開されました。タイムズ。
>
関連コンテンツ:
- ハードウェアアクセラレータはAIアプリケーションに対応します
- DSPがハードウェアアクセラレータに勝ったとき
- 適切なRISC-Vカスタム命令を使用してアプリケーションを高速化するためのガイド
- 推論チップのパフォーマンスは、最適化されたメモリサブシステム設計に基づいています
- 新しいAIアクセラレータモジュールがエッジパフォーマンスを強化します
- エッジAIはメモリテクノロジーに挑戦します
Embeddedの詳細については、Embeddedの週刊メールニュースレターを購読してください。
埋め込み
- ハイブリッドクラウド環境:最適なアプリケーション、ワークロード、戦略のガイド
- AIチップアーキテクチャはグラフ処理を対象としています
- ワイヤレスMCUはデュアルコアアーキテクチャを備えています
- 専用プロセッサがエンドポイントAIワークロードを加速します
- リファレンスデザインは、メモリを大量に消費するAIワークロードをサポートします
- スマートセンサーボードがエッジAI開発をスピードアップ
- スマートカメラはターンキーエッジマシンビジョンエッジAIを提供します
- IBMがモノのインターネット向けのハイブリッドブロックチェーンアーキテクチャを発表
- OmronsTMコボットは統合とプログラミングを高速化します
- ハイパースペクトルビジョン。それは何ですか?
- アーキテクチャ設計とは?