


データバスとデータベース:すべてのIIoT開発者が尋ねる必要のある6つの質問

産業用モノのインターネット(IIoT)には、紛らわしい用語がたくさんあります。それは避けられません。コンピューティングとシステムでおなじみの概念を再利用しているにもかかわらず、IIoTは物事の仕組みにおける根本的な変化です。基本的な変更には、基本的に新しい概念が必要です。最も重要なものの1つは、「データバス」の概念です。
間もなくリリースされるIICリファレンスアーキテクチャバージョン2には、「レイヤードデータバス」パターンと呼ばれる新しいパターンが含まれています。 IICのリリースについてはこれ以上言うことはできませんが、文書化のプロセスを経ることは、明確な定義を推進するのに最適です。
データバスの定義は次のとおりです。
データバスは、仮想のグローバルデータスペースを実装するデータ中心の情報共有テクノロジーです。ソフトウェアアプリケーションは、グローバルデータスペースのエントリを読み取って更新します。更新は、パブリッシュ/サブスクライブ通信メカニズムを介してアプリケーション間で共有されます。
データバスの主な特徴は次のとおりです。
- 参加者/アプリケーションはデータと直接やり取りします
- インフラストラクチャはデータを理解しているため、データを選択的にフィルタリングできます。
- インフラストラクチャは、データフローのレート、信頼性、セキュリティなどのサービス品質(QoS)パラメータのルールと保証を課します。
もちろん、新しい概念は質問を生み出します。最高の質問のいくつかは、大規模なデータベース会社のアーキテクトから寄せられました。私たちは通常、ネットワーキングまたはソフトウェアアーキテクトの観点からデータバスの概念を説明しようとします。しかし、データサイエンスはおそらくより良いアプローチです。データベースとデータバスはどちらも、結局のところ、データサイエンスの概念です。
最も一般的な6つの質問を見てみましょう。
質問1:データバスは(あらゆる種類の)データベースとどのように異なりますか?
簡単な答え:データベース データ中心のストレージを実装します。 古いを保存します 後で検索できる情報 保存されたデータのプロパティを関連付けることによって。 データバス データ中心の相互作用を実装します。 将来を管理します フィルタリングできるようにすることで情報を提供します 受信データのプロパティによって。
長い答え:データ中心性は次のプロパティで定義できます:
- インターフェースはデータです。メッセージ、オブジェクト、ファイル、アクセスパターンなど、そのインターフェイスへの人工的なラッパーやブロッカーはありません。
- インフラストラクチャはそのデータを理解します。これにより、フィルタリング/検索、ツール、および選択性が可能になります。アプリケーションをデータから切り離し、それによってアプリケーションの複雑さの多くを取り除きます。
- システムはデータを管理し、アプリケーションがデータを交換する方法にルールを課します。これは「真実」の概念を提供します。これにより、データの有効期間、データモデルのマッチング、CRUDインターフェイスなどが可能になります。
リレーショナルデータベースは、データ中心のストレージテクノロジーです。データベース以前は、ストレージシステムはアプリケーション定義の(アドホック)構造のファイルでした。データベースもファイルですが、非常に特殊なファイルです。データベースは、データを解釈する方法を知っており、アクセス制御を実施します。したがって、データベースはシステムの「真実」を定義します。データベース内のデータが破損したり失われたりすることはありません。
データベースは、データモデルを制御する単純なルールを適用することにより、一貫性を確保します。データベースは、すべてのユーザーによる検索と取得にデータを公開することにより、システム統合を大幅に容易にします。データベースは、データとスキーマの検出を可能にすることで、情報の監視、測定、およびマイニングのための汎用ツールも可能にします。
データベースのように、データ中心のミドルウェア(データバス)は送信されたデータの内容を理解します。データバスもメッセージを送信しますが、非常に特別なメッセージを送信します。状態を維持するために特に必要なメッセージのみを送信します。明確なルールは、データへのアクセス、システム内のデータの変更方法、および参加者が更新を取得するタイミングを管理します。重要なのは、インフラストラクチャのみがメッセージを送信することです。アプリケーションにとって、システムは制御されたグローバルデータスペースのように見えます。アプリケーションは、データおよびデータの「サービス品質」(QoS)プロパティ(経過時間やレートなど)と直接対話します。 「メッセージ」のアプリケーションレベルの認識や概念はありません。データバスを使用するプログラムはデータの読み取りと書き込みを行い、メッセージを送受信しません。
<図>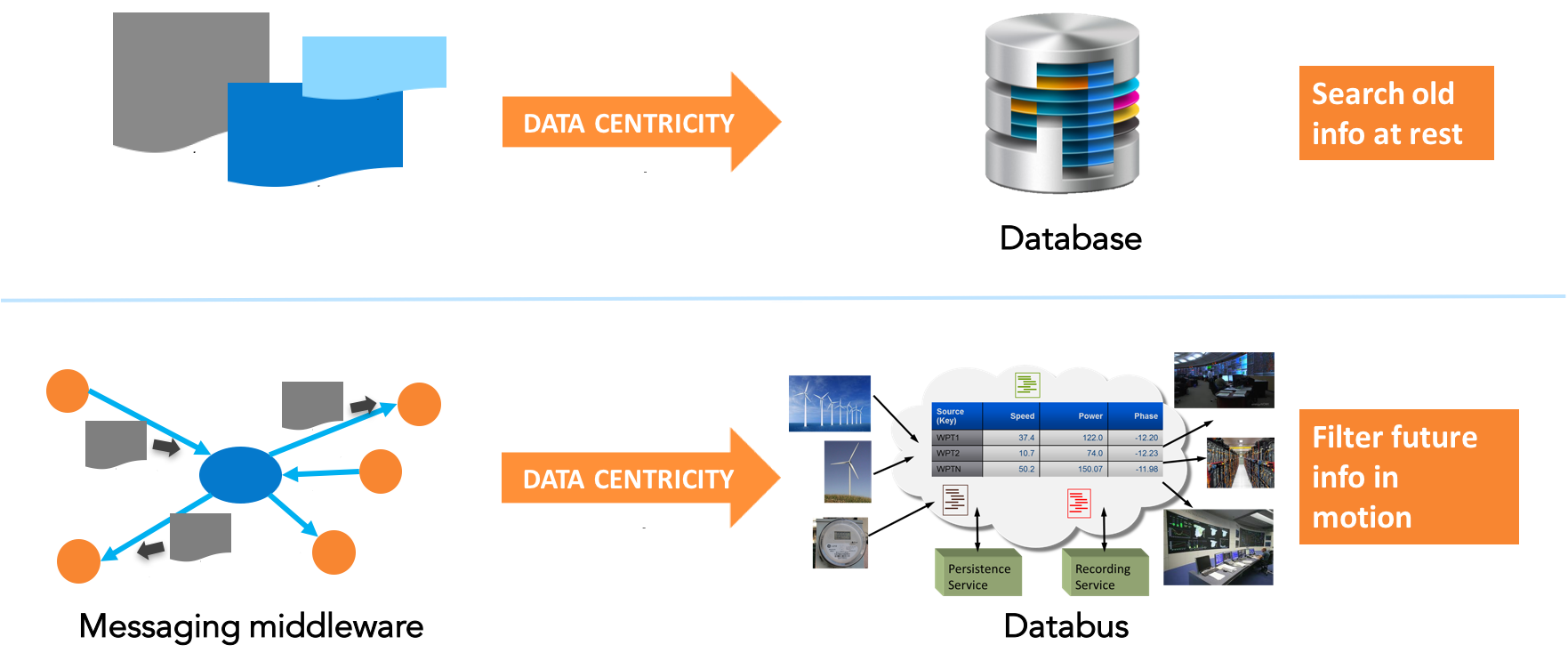
データの構造と要求に関する知識があれば、データバスインフラストラクチャは、情報のフィルタリング、更新のタイミングまたは更新の選択などを行うことができます。インフラストラクチャ自体は、更新レート、信頼性、ピアの活性の保証された通知などのQoSを制御できます。インフラストラクチャはデータフローを検出し、それらをアプリケーションと汎用ツールに同様に提供できます。分散システムにおけるデータステータスのこの知識は、「真実」の明確な定義です。データベースと同様に、インフラストラクチャは構造とコンテンツの両方のデータを他のアプリケーションに公開します。このアクセス可能な正しい情報源により、システム統合が大幅に容易になります。また、情報の流れを監視および表示し、メッセージをルーティングし、キャッシュを管理する汎用ツールとサービスを有効にします。
質問2:「ソフトウェアアプリケーションは、グローバルデータスペースのエントリを読み取って更新します。更新は、パブリッシュ/サブスクライブ通信メカニズムを介してアプリケーション間で共有されます。」これは、pub-subインターフェースを介して対話するデータベースであることを意味しますか?
簡単な答え:いいえ、データベースはありません。データベースはストレージを意味します。データは物理的にどこかに存在します。データバスは、「グローバルデータスペース」と呼ばれる純粋な仮想概念を実装しています。
長い答え:データバスデータスペースは、将来の情報と対話する方法を定義します。たとえば、「あなた」が交差点の管制官である場合、あなたはあなたの位置から200m以内の車両の更新を購読することができます。これらの更新は、車両が接近した場合に配信されます。配信はさまざまな方法で保証されます(.01秒以内に開始、100x /秒で更新、信頼性など)。データがまったく保存されない場合があることに注意してください。 (信頼性などの一部のQoS設定では、ローカルストレージが必要になる場合があります。)データスペースは、指定したとおりの方法で情報が入力される、特別に制御されたデータオブジェクトのセットと考えることができます。ただし、その情報は(一般)データバスによって保存されます...配信されたばかりです。
質問3:「参加者/アプリケーションはデータと直接やり取りします。」それが何を意味するのか詳しく教えていただけますか?
「メッセージ中心の」ミドルウェアを使用して、メッセージにラップされたデータを別のアプリケーションに送信するアプリケーションを作成します。たとえば、クライアントにサーバーにデータを送信させることでこれを行うことができます。両端は、通常はスキーマなどを含む、もう一方の端について何かを知る必要がありますが、「0.01秒未満」、「100x /秒になる」などのデータのプロパティを想定している可能性もあります。生きている別の終わりがあること、例えばサーバーが実行されています。これらの想定されるプロパティはすべてアプリケーションコードに完全に隠されているため、再利用、システム統合、相互運用性は非常に困難です。
データバスを使用すると、ソースアプリケーションについて何も知る必要がありません。データのニーズを明確にすると、データバスがそれを配信します。したがって、データバスでは、各アプリケーションはデータスペースとのみ対話します。アプリケーションとして、CRUDインターフェイスを使用してデータスペースに書き込むか、データスペースから読み取るだけです。もちろん、そのデータスペースからのQoSが必要になる場合があります。データを毎秒100倍更新する必要があります。データスペース自体(データバス)は、そのデータを取得する(またはエラーにフラグを立てる)ことを保証します。そのデータの冗長ソースが1つまたは27しかないのか、ネットワークまたは共有メモリ経由であるのか、LinuxのCプログラムなのかWindowsのC#プログラムなのかを知る必要はありません。すべての相互作用は、データスペースの独自のビューで行われます。たとえば、受信者のいないスペースにデータを書き込むことも理にかなっています。この場合、QoS設定に応じて、データバスはまったく何もしないか、後で配信するために情報をキャッシュする可能性があります。
データベースとデータバスの両方のテクノロジーが、アプリケーションとアプリケーションの相互作用をアプリケーションとデータとアプリケーションの相互作用に置き換えていることに注意してください。この抽象化は絶対に重要です。アプリケーションを切り離し、スケーリング、相互運用性、およびシステム統合を大幅に容易にします。違いは、実際には(集中化されている可能性が高い)データベースに保存されている古いデータと、分散データスペースからアプリケーションに直接送信される将来のデータの1つです。
質問4:「インフラストラクチャはデータを理解しているため、データを選択的にフィルタリングできます。」興味のある「イベント」に登録できるすべてのpub-subに当てはまりませんか?
ほとんどのpub-subは非常に原始的です。アプリケーションは「関心を登録」し、すべてがそのアプリケーションに送信されるだけです。したがって、たとえば、交差点衝突検出アルゴリズムは「車両位置」をサブスクライブできます。次に、インフラストラクチャは、メッセージ内のデータを知らなくても、位置を生成できるセンサーからメッセージを送信します。 「コンテンツフィルタリング」のpub-subでさえ、非常に単純な仕様しか提供しておらず、システムがすべてにとって重要なものを事前に選択する必要があります。流れを実際に制御することはできません。
データバスははるかに表現力豊かです。その交差点は、「200m以内の車両位置にのみ関心があり、10m / sで自分に向かって移動します。車両が私の仕様に該当する場合は、1秒間に200回更新する必要があります。あなた(データバス)は私を保証する必要があります。このアルゴリズムを供給するすべてのセンサーは、データを高速で配信することを約束します...低速または高速ではありません。センサーが1秒間に1000回更新される場合は、5回ごとの更新のみを送信してください。 -可能なすべての道路アプローチで常にライブセンサー(過去0.01秒で生成すると定義)。すべてのセンサーは600個の古いサンプル(3秒相当)を保存でき、必要に応じてその古いデータで更新できる必要があります。それ。" (これらは、DDS標準の20以上のQoS設定の一部です。)
プリミティブpub-subの場合のサブスクライブアプリケーションは、そのプロデューサーの実際のプロパティに大きく依存することに注意してください。どういうわけか、彼らが生きていること(!)、必要な情報を保存するのに十分なバッファがあること、情報が殺到したり、提供が遅すぎたりしないことを信頼する必要があります。 1000x /秒で検出されている車が10,000台あるが、200m以内に3台しかない場合、注意が必要な3 * 200 =600を見つけるために、毎秒10,000 * 1000 =10mのサンプルを受信する必要があります。センサーがアクティブであることを確認するために、すべてのセンサーに100x /秒でpingを実行する必要があります。異なるパスに冗長センサーがある場合は、それらすべてに個別にpingを実行し、何らかの方法ですべてのパスがカバーされていることを確認する必要があります。多くのアプリケーションがある場合、それらはすべて、すべてのセンサーに個別にpingを実行する必要があります。また、プロデューサーのスキーマなども知っている必要があります。
対照的に、2番目のケースのアプリケーションは、関心のある600個のサンプルを正確に受信し、各パスに少なくとも1つのセンサーがアクティブであるという知識に満足しています。流量が保証されています。十分な信頼性が保証されます。合計データフローは99.994%削減されます(600 / 10mのサンプルのみが必要であり、スマートミドルウェアはソースでフィルタリングを行います)。完全を期すために、衝突アルゴリズムはセンサー自体から完全に独立していることに注意してください。他の交差点で再利用でき、パスごとに1つのセンサーまたは17で動作します。実行時にネットワークの負荷が高くなりすぎてデータ仕様を満たせなくなった場合(または何かが失敗した場合)、アプリケーションにすぐに通知されます。
質問5:データバスはCEPエンジンとどのように異なりますか?
簡単な答え:データバスは基本的に分散された概念であり、単純な仕様に一致するローカルプロデューサーからのデータを選択して配信します。 CEPエンジンは、はるかに複雑な仕様に対応できる一元化された実行可能サービスですが、すべてのデータストリームを1か所に送信する必要があります。
長い答え:複合イベント処理(CEP)エンジンは、データの着信ストリームを調べて、特定するようにプログラムしたパターンを探します。それらのパターンの1つが見つかったら、アクションを実行するようにプログラムできます。パターンは、過去のデータと今後のデータの複雑な組み合わせにすることができます。ただし、これは単一のサービスであり、どこかの単一のCPUで実行されます。情報を送信しません。
データバスは、データのパターンも検索します。ただし、仕様はより単純です。生成される各データ項目について決定を下します。アクションも簡単です。実行できる唯一のアクションは、そのデータをリクエスターに送信することです。データバスの力は、基本的に分散されていることです。探しているのは、潜在的に数百、数千、さらには数百万のノードでローカルに発生します。したがって、データバスは、適切なソースから適切なデータを選択し、それらを適切な場所に送信するための非常に強力な方法です。データバスは、CEPエンジンの分散セットのようなものであり、可能な情報ソースごとに1つであり、その情報のユーザーによって自動的にプログラムされます。もちろん、データバスには、スキーマメディエーション、冗長性管理、トランスポートサポート、相互運用可能なプロトコルなど、パターンマッチング以外の多くのプロパティがあります。
質問6:どのアプリケーションがDDS標準とデータバスを駆動しましたか?
初期のアプリケーションは、インテリジェントロボット、「情報の優位性」、および海軍の戦闘管理などの大規模な協調システムでした。これらのシステムには、コンポーネントに障害が発生した場合でも信頼性が必要であり、物理プロセスを制御するのに十分な速度のデータが必要であり、拡張のための選択的な検出と配信が必要でした。データ中心性により、アプリケーションコードと制御されたインターフェイスが大幅に簡素化され、プログラマーのチームが時間の経過とともに大規模なソフトウェアシステムで作業できるようになりました。 DDS標準は、元々ベンダーと顧客の両方によって推進された、活発で成長している標準のファミリーです。医療、運輸、スマートシティ、エネルギーなど、多くの分野で大きな用途があります。
インテリジェントなソフトウェアがIIoTをどのように一掃しているかについて知りたい場合は、自動車業界の将来に関するホワイトペーパー「自動運転車の秘密のソース」をダウンロードしてください。

モノのインターネットテクノロジー