


tinyMLと自動機械学習を使用した効果的なIoTアプリケーションの構築
IoTにより、小さなセンサーを使用して環境とマシンを継続的に監視できます。センサー技術、マイクロコントローラー、通信プロトコルの進歩により、多くの接続オプションを備えたIoTプラットフォームの大量生産が、手頃な価格で可能になりました。 IoTハードウェアのコストが低いため、センサーは公共の場所、住宅、および機械に大規模に展開されています。
これらのセンサーは、展開環境に関連する物理的特性を24時間年中無休で監視し、大量のデータを生成します。たとえば、回転機械に配置された加速度計とジャイロスコープは、シャフトに取り付けられたローターの振動パターンと角速度を常に記録しています。空気品質センサーは、屋内または屋外の空気中のガス状汚染物質を継続的に監視します。ベビーモニターのマイクは常に聞いています。スマートウォッチ内のセンサーは、重要な健康パラメーターを常に測定します。同様に、磁力計、圧力、温度、湿度、周囲光などの他のさまざまなセンサーは、配置されている場所に関係なく、物理的状態を測定します。
機械学習(ML)アルゴリズムにより、このデータ内の興味深いパターンを発見できます。これは、手動による分析や検査の理解を超えています。 IoTデバイスとMLアルゴリズムの統合により、さまざまなスマートアプリケーションと強化されたユーザーエクスペリエンスが可能になります。これは、低電力、低レイテンシ、軽量の機械学習推論、つまりtinyMLによって可能になります。ウェアラブルテクノロジー、スマートホーム、スマートファクトリー(インダストリー4.0)、自動車、マシンビジョン、その他のスマート家電製品など、多くの業界がこの収束によって革命を起こしつつあります。
自動機械学習を使用したtinyML
IoTデバイスの小さなマイクロコントローラー(MCU)にデプロイされたMLアルゴリズムは、複数の利点があるため、特に興味深いものです。
- データのプライバシーとセキュリティ:ML推論は、処理のためにデータストリームをクラウドに送信する代わりに、ローカルの組み込みマイクロコントローラーで行われます。データはデバイス上とオンプレミスに残り、プライベートで安全です。
- 省電力:tinyMLアルゴリズムは、データの送信がまったくないかほとんどないため、消費電力がはるかに少なくなります。
- 低遅延と高可用性:推論はローカルで実行されるため、遅延はミリ秒のオーダーであり、ネットワークの遅延と可用性の影響を受けません。
クリックしてフルサイズの画像を表示

図1:tinyMLが従来のIoTデバイスに高度な機能を追加(出典:Qeexo)
センサーデータを使用した自動機械学習には、図2に示す手順が含まれます。これらの手順の前に、センサーの構成とターゲットMLアプリケーションの品質データの収集が完了します。 Qeexo AutoMLなどの自動機械学習プラットフォームは、ArmCortex-M0からM4クラスのMCUやその他の制約のある環境向けの軽量で高性能な機械学習モデルを構築するためのワークフロー全体を管理します。
クリックしてフルサイズの画像を表示
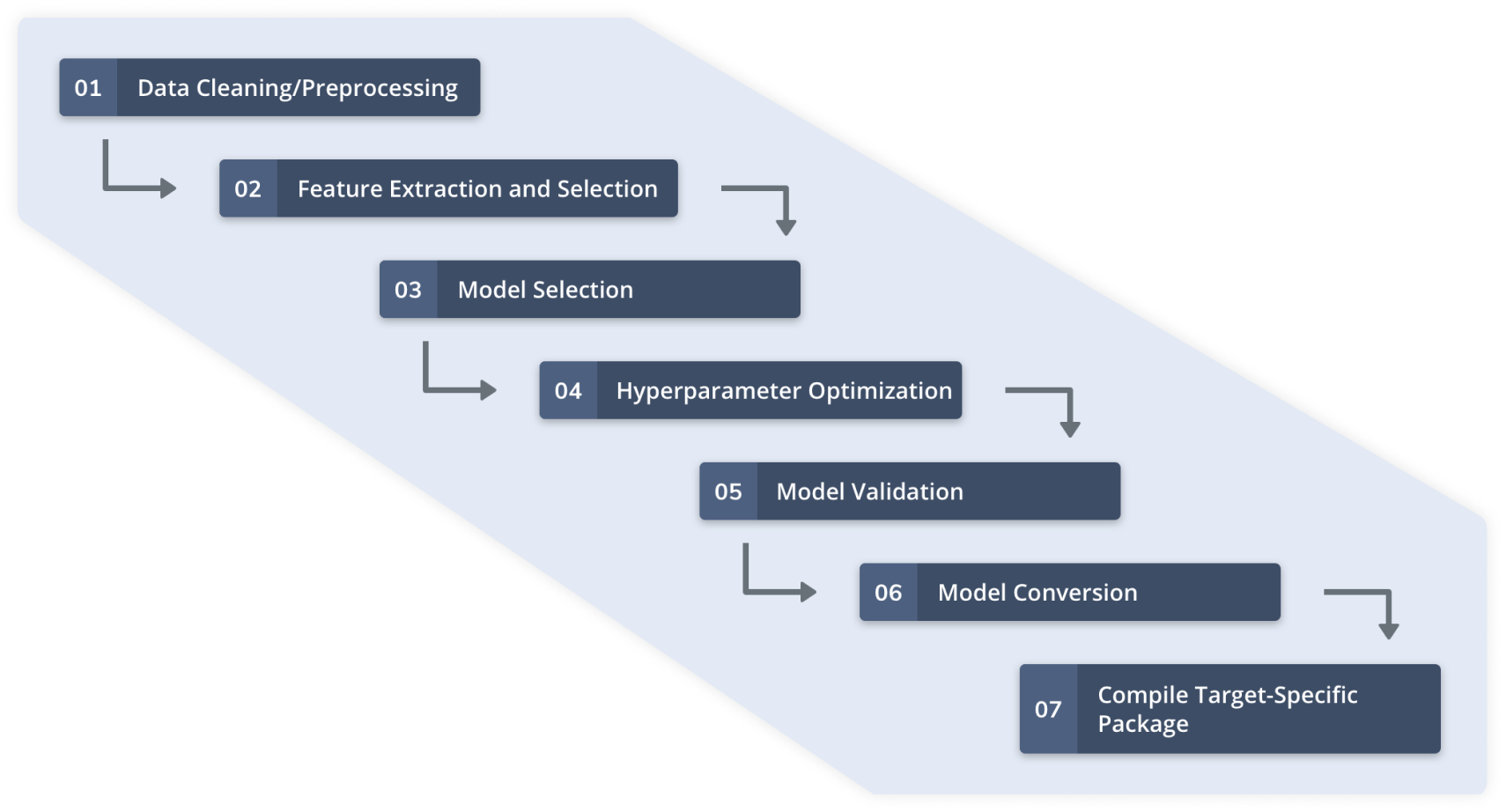
図2:Qeexo AutoMLワークフロー(出典:Qeexo)
ARM®Cortex™M0 +アーキテクチャを備えたtinyML
IoTテクノロジーの急増とセンサーの大規模な展開要件により、マイクロコントローラーアーキテクチャと機械学習コンピューティングの限界がさらに押し広げられています。たとえば、48MHzで動作するArmCortex M0 + MCUは、消費電力プロファイルが低いため、IoTアプリケーション用に設計されたセンサーボードで広く使用されています。 64MHzで動作して15mAを消費するCortexM4バージョンと比較して、I / Oピンあたりわずか7mAを消費します。
Cortex-M0 + MCU定格の低消費電力は、メモリとコンピューティングプロファイルの削減を犠牲にしてもたらされます。 M0 + MCUは、32ビットの固定小数点数学演算のみを実行でき、飽和演算をサポートしておらず、DSP機能を備えていません。このMCUに基づいて、人気のあるIoTプラットフォームの1つであるArduino Nano 33 IoTには、256KBのフラッシュと32KBのSRAMしか付属していません。対照的に、CortexM4アーキテクチャを備えた人気のセンサーモジュールであるArduinoNano 33 BLE Senseは、32ビット浮動小数点演算を実行でき、DSPと飽和演算をサポートし、フラッシュの4倍とSRAMの8倍をサポートします。
>M0 +での機械学習アルゴリズムの導入は、次の3つの主な課題があるため、M4での導入に比べて桁違いに困難です。
- 固定小数点計算: センサーデータを使用した一般的な機械学習には、デジタル信号処理、特徴抽出、推論の実行が含まれます。センサー信号から統計的および周波数ベース(FFT分析など)の特徴を抽出することは、高性能の機械学習モデルの開発に不可欠です。実世界の物理現象を表すセンサーデータストリームは、本質的に非定常です。一般的に、非定常センサー信号から抽出される情報が優れているほど、高性能のMLモデルを開発する機会が増えます。商用グレードの精度とパフォーマンスを維持しながら、固定小数点表現で数学演算を実行することは困難です。完全に固定された機械学習パイプラインは、センサーデータの表現から始まり、分類/回帰出力を生成するためのモデル推論まで続きます。
- メモリ容量が少ない: 256KBのフラッシュと32KBのSRAMは、これらのモデルが実行中に利用できる機械学習モデルとランタイムメモリのサイズに厳しい制限を課しました。実際の機械学習の問題には、多くの場合、多数のパラメーターを持つ機械学習モデルによって表される複雑な意思決定/分類の境界があります。ツリーベースのアンサンブルモデルの場合、このような複雑な問題を解決すると、深いツリーと多数のブースターが発生し、モデルサイズと実行時メモリの両方に影響を与える可能性があります。モデルサイズの縮小は、多くの場合、モデルのパフォーマンスを犠牲にするという犠牲を伴います。一般的に、トレードオフの最も望ましい基準ではありません。
- CPU速度が遅い: 商用展開用のモデルを選択する場合、低遅延は常に重要な指標でした。 64 MHzM4アーキテクチャと比較して48MHz M0 +アーキテクチャで犠牲にしている16MHzクロック速度は、ミリ秒レベルの遅延測定に関して大きな違いをもたらします。
AutoML M0 +フレームワーク
これらの課題に対処するために開発されたQeexoAutoMLは、Arm Cortex M0 +アーキテクチャ用に高度に最適化された固定小数点の機械学習パイプラインを提供します。このパイプラインには、勾配ブースティングマシン(GBM)、ランダムフォレスト(RF)、eXtreme勾配ブースティング( XGBoost)アルゴリズム。 Qeexo AutoMLは、アンサンブルモデルパラメーターを非常に効率的なデータ構造でエンコードし、それらを解釈ロジックと組み合わせて、M0 +ターゲットで非常に高速な推論を実現します。図3は、QeexoがArm Cortex M0 +組み込みターゲット用に開発した固定小数点機械学習パイプラインを明確に示しています。
クリックしてフルサイズの画像を表示
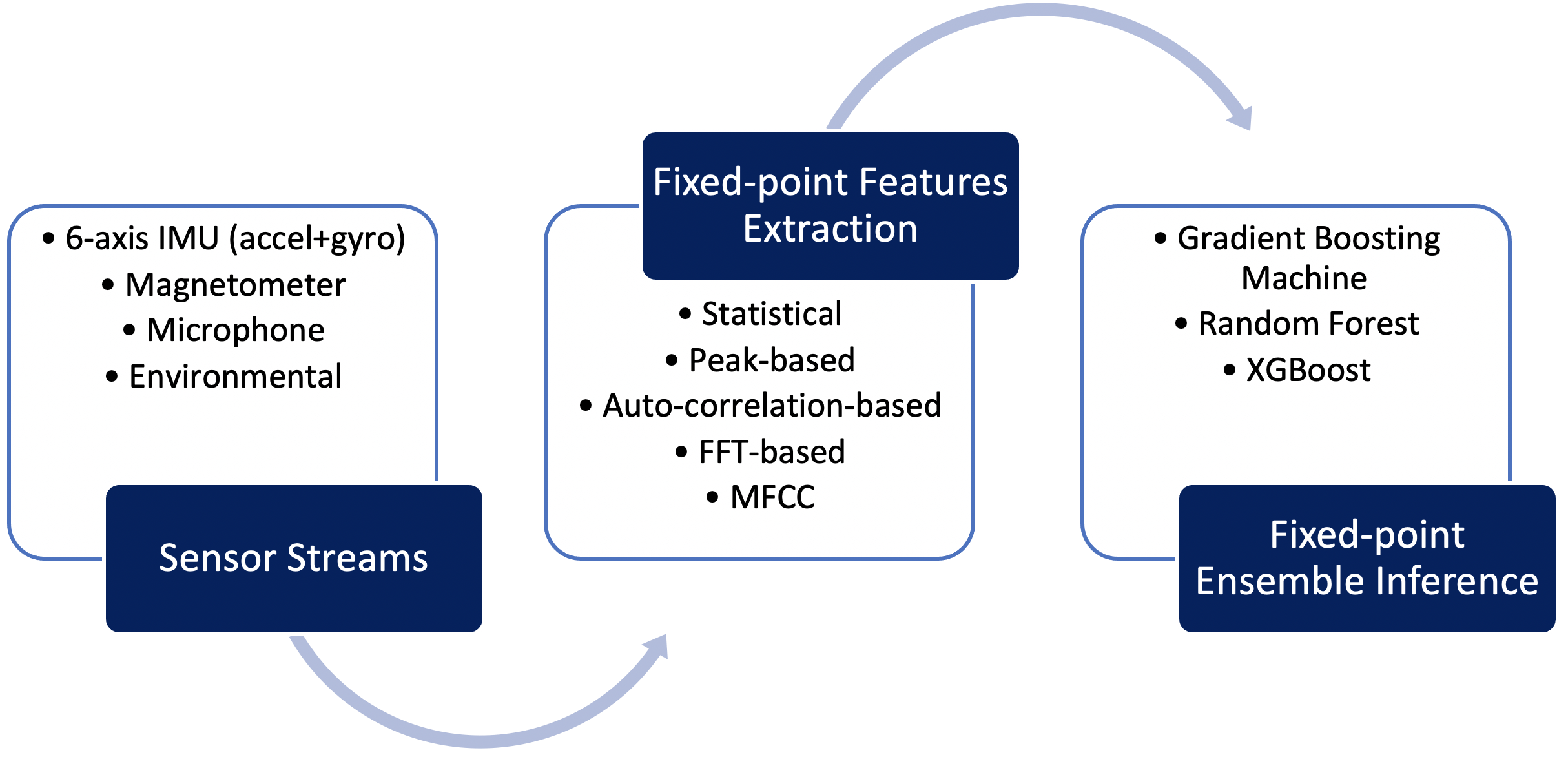
図3:Qeexo AutoML M0 +推論パイプライン(出典:Qeexo)
Qeexo AutoMLは、特許出願中のモデルの圧縮と量子化を実行して、分類のパフォーマンスを損なうことなく、開発されたアンサンブルモデルのメモリフットプリントをさらに削減します。図4は、Cortex M0 +組み込みターゲットのQeexoAutoMLトレーニングプロセスを示しています。
クリックしてフルサイズの画像を表示
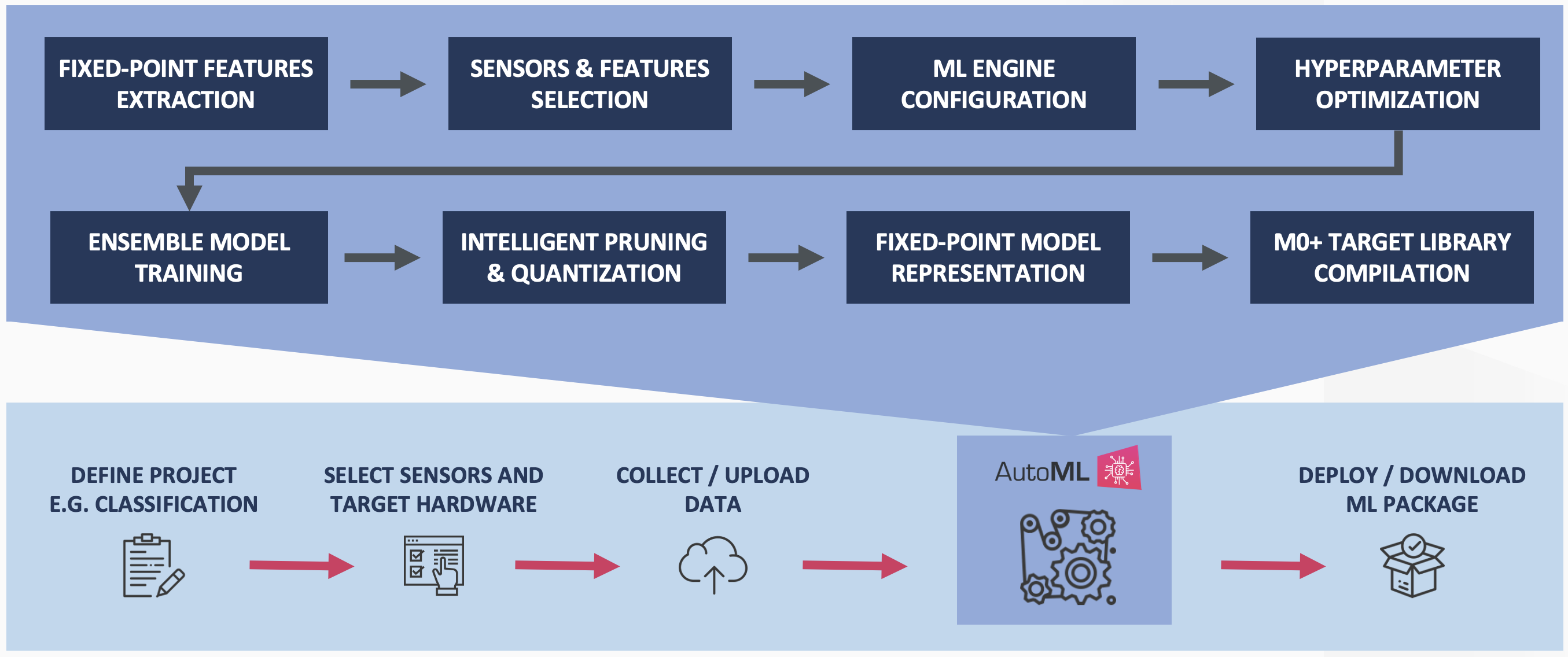
図4:Qeexo AutoML M0 +トレーニングパイプライン(出典:Qeexo)
インテリジェントな剪定
インテリジェントなプルーニングにより、パフォーマンスを低下させることなくモデルを圧縮できます。簡単に言えば、Qeexo AutoMLは、最初にハイパーパラメーターオプティマイザーが推奨するフルサイズのアンサンブルモデルを構築し、次に最も強力なブースターのみをインテリジェントに選択します。
より大きなモデルを成長させ、それをターゲット展開のためにインテリジェントにプルーニングするこのアプローチは、最初に小さなモデルを構築するよりもはるかに効果的です。最初のより大きなモデルは、最終的にモデルのパフォーマンスを向上させる高性能ブースター(またはツリー)を選択する機会を提供します。
図5に示すように、圧縮されたアンサンブルモデルは約1/10 th です。 より高い相互検証性能を持ちながら、完全なモデルのサイズ。 (X軸はアンサンブルモデルのツリー(またはブースター)の数を表し、y軸は交差検定のパフォーマンスを表します。)Qeexo AutoMLインテリジェントプルーニング方法では、最も強力な20個のブースターのみが選択され、90%の圧縮が得られることに注意してください。モデルサイズで。
クリックしてフルサイズの画像を表示
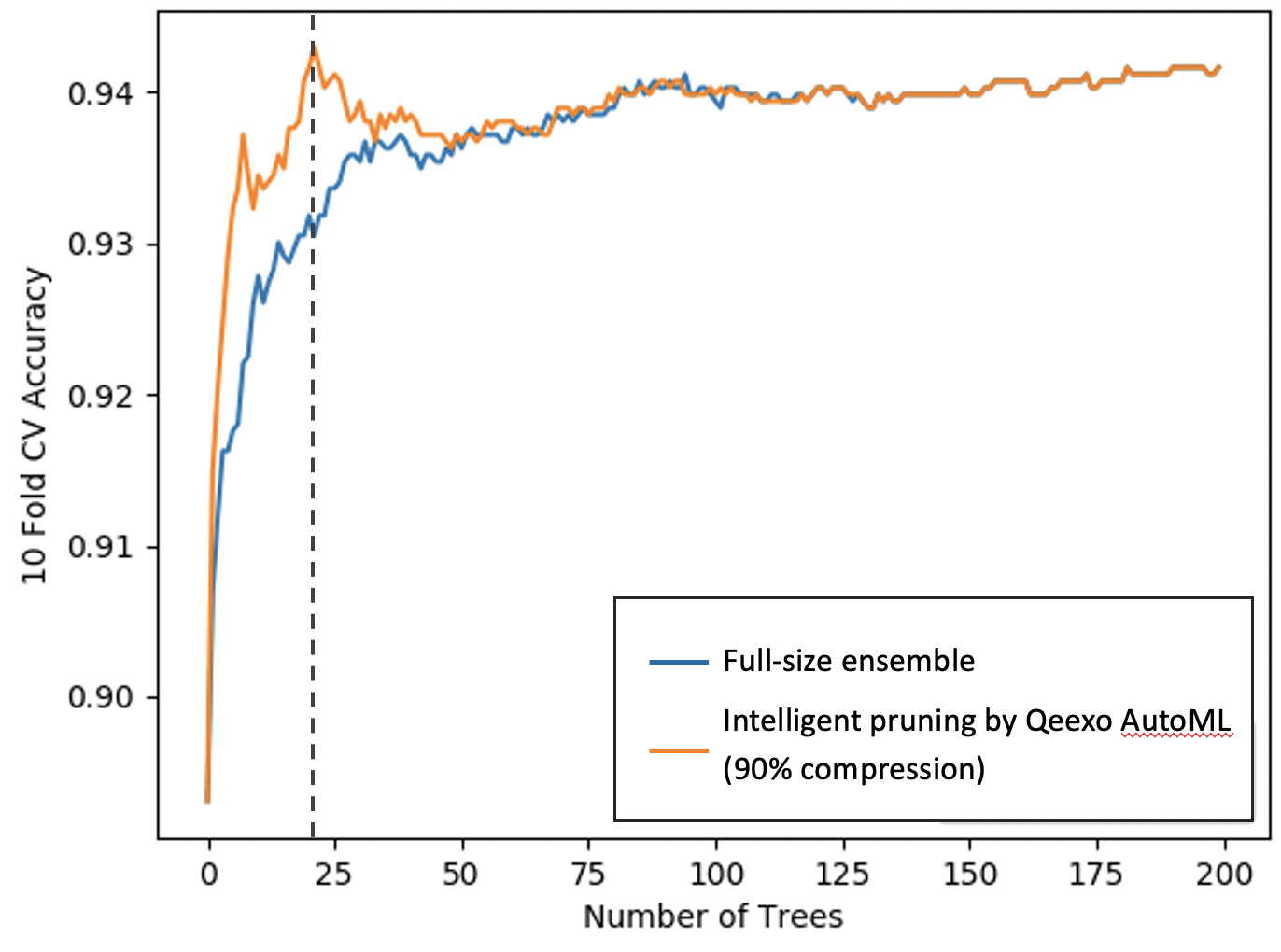
図5:Qeexo AutoMLインテリジェントモデルプルーニング(出典:Qeexo)
アンサンブルモデルの量子化
Qeexo AutoMLは、アンサンブルアルゴリズムのトレーニング後の量子化を実行します。トレーニング後の量子化は、ニューラルネットワークベースのモデルのコモディティ化された機能であり、TensorFlowLiteなどのフレームワークですぐにサポートされます。ただし、アンサンブルモデルの量子化は、Qeexoの特許出願中の手法であり、モデルのパフォーマンスをほとんどまたはまったく低下させることなく、MCUレベルのレイテンシを改善しながら、モデルのサイズをさらに縮小できます。 Qeexo AutoML M0 +パイプラインは、32ビット精度で表される固定小数点アンサンブルモデルを生成します。 16ビットおよび8ビットの量子化の追加オプションにより、モデルをそれぞれ1/2および1/4削減し、2倍から3倍の速度向上を実現できます。
使用例-tinyMLの事例
tinyMLアプリケーションまたはユースケースにはどのようなものがありますか?無限の可能性があり、ここではいくつかを強調します:
- ユーザーがタップして照明を制御できる(オン/オフを切り替えたり、光の強さを変更したりできる)スマートなAI対応の壁を作りたいと考えています。オン/オフと強度制御に関連する手のジェスチャーを定義し、壁の背面に取り付けられた加速度計とジャイロスコープモジュールを使用してジェスチャーデータを収集してラベルを付けることができます。このラベル付けされたデータを使用して、Qeexo AutoMLはAIアルゴリズムを使用してモデルを構築し、壁の「ノック」および「ワイプ」ジェスチャを検出して照明を制御できます。下のビデオでは、QeexoAutoMLによって開発されたプロトタイプのスマートウォールを数分で見ることができます。
- 機械学習とIoTを使用して、出荷ガイドラインに従って出荷が細心の注意を払って処理されるようにします。下の動画では、AI対応の配送ボックスが、配送元から配送先までの配送の処理方法をどのように検出できるかを確認できます。
- AIとIoTの融合により、スマートキッチンのカウンタートップも作成できます。以下のビデオは、さまざまなキッチン家電を検出するためにQeexoAutoMLで構築されたモデルを示しています。
- マシンの監視は、tinyMLの最も有望なユースケースの1つです。以下のビデオでは、複数のマシン障害パターンが検出されています。
- 異常検出は、機械学習から大きなメリットを得るもう1つのシナリオです。多くの場合、産業環境ではさまざまな障害のデータを収集することは困難ですが、マシンの正常な動作状態を監視することは比較的簡単です。 Qeexo AutoMLアルゴリズムは、正常な動作状態を観察するだけで、パート1(下記)、パート2、パート3、パート4に示すような異常検出用のAIシステムを開発できます。
- ウェアラブルに埋め込まれたセンサーを使用したアクティビティ認識は、私たちの日常生活に役立つもう1つのユースケースです。以下のビデオは、QeexoAutoMLを使用して数分以内にアクティビティ認識ソリューションを構築する方法を示しています。
モノのインターネットテクノロジー
- イーサリアムとグーグルでハイブリッドブロックチェーン/クラウドアプリケーションを構築する
- サプライチェーンと機械学習
- サービスプロバイダーおよびIoTアプリケーション向けの1G双方向トランシーバー
- センサーとプロセッサーは、産業用アプリケーション向けに統合されています
- RaspberryPiとPythonを使用したロボットの構築
- 機械学習で信頼性を高め、メンテナンスの成果を向上させる
- IoTと教育:デジタルデバイドの橋渡し
- IoTセンサーによる大気汚染モニタリングの改善
- インダストリーIoTとインダストリー4.0のビルディングブロック
- ERPおよびMESシステムはIIoTに追いつくことができますか?
- マシンビジョンはインダストリー4.0とIoTの鍵です