


パイソン文字列
Python 文字列
このチュートリアルでは、Python で文字列を作成、フォーマット、変更、および削除する方法を学習します。また、さまざまな文字列操作と機能についても紹介します。
ビデオ:Python 文字列
Python の文字列とは?
文字列は一連の文字です。
文字は単なる記号です。たとえば、英語には 26 文字あります。
コンピュータは文字を扱うのではなく、数字 (バイナリ) を扱います。画面に文字が表示されていても、内部的には 0 と 1 の組み合わせとして保存および操作されます。
この文字から数値への変換をエンコードと呼び、逆のプロセスをデコードと呼びます。 ASCII と Unicode は、使用される一般的なエンコーディングの一部です。
Python では、文字列は Unicode 文字のシーケンスです。 Unicode は、すべての言語のすべての文字を含め、エンコードに統一性をもたらすために導入されました。 Python Unicode から Unicode について学ぶことができます。
Python で文字列を作成する方法
一重引用符または二重引用符で文字を囲むことにより、文字列を作成できます。三重引用符も Python で使用できますが、通常は複数行の文字列とドキュメント文字列を表すために使用されます。
# defining strings in Python
# all of the following are equivalent
my_string = 'Hello'
print(my_string)
my_string = "Hello"
print(my_string)
my_string = '''Hello'''
print(my_string)
# triple quotes string can extend multiple lines
my_string = """Hello, welcome to
the world of Python"""
print(my_string) プログラムを実行すると、出力は次のようになります:
Hello
Hello
Hello
Hello, welcome to
the world of Python 文字列内の文字にアクセスするには?
インデックスを使用して個々の文字にアクセスし、スライスを使用して文字の範囲にアクセスできます。インデックスは 0 から始まります。インデックス範囲外の文字にアクセスしようとすると、IndexError が発生します。 .インデックスは整数でなければなりません。 float やその他の型は使用できません。これは TypeError になります。 .
Python では、そのシーケンスに負のインデックスを付けることができます。
-1 のインデックス 最後の項目 -2 を参照 最後から 2 番目の項目まで、というように続きます。スライス演算子 : を使用して、文字列内のさまざまな項目にアクセスできます。 (コロン).
#Accessing string characters in Python
str = 'programiz'
print('str = ', str)
#first character
print('str[0] = ', str[0])
#last character
print('str[-1] = ', str[-1])
#slicing 2nd to 5th character
print('str[1:5] = ', str[1:5])
#slicing 6th to 2nd last character
print('str[5:-2] = ', str[5:-2]) 上記のプログラムを実行すると、次の出力が得られます:
str = programiz str[0] = p str[-1] = z str[1:5] = rogr str[5:-2] = am
範囲外のインデックスにアクセスしようとしたり、整数以外の数値を使用しようとすると、エラーが発生します。
# index must be in range
>>> my_string[15]
...
IndexError: string index out of range
# index must be an integer
>>> my_string[1.5]
...
TypeError: string indices must be integers 以下に示すように、インデックスが要素間にあると考えると、スライスを最もよく視覚化できます。
範囲にアクセスする場合は、文字列からその部分をスライスするインデックスが必要です。
<図>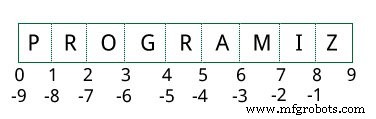
文字列を変更または削除する方法
文字列は不変です。つまり、一度割り当てられた文字列の要素は変更できません。異なる文字列を同じ名前に再割り当てするだけです。
>>> my_string = 'programiz'
>>> my_string[5] = 'a'
...
TypeError: 'str' object does not support item assignment
>>> my_string = 'Python'
>>> my_string
'Python'
文字列から文字を削除または削除することはできません。ただし、del を使用して文字列を完全に削除することは可能です。 キーワード。
>>> del my_string[1]
...
TypeError: 'str' object doesn't support item deletion
>>> del my_string
>>> my_string
...
NameError: name 'my_string' is not defined Python 文字列操作
文字列で実行できる操作は多数あり、Python で最もよく使用されるデータ型の 1 つです。
Python で使用できるデータ型の詳細については、Python データ型
をご覧ください。2 つ以上の文字列の連結
2 つ以上の文字列を 1 つの文字列に結合することを連結と呼びます。
+ operator はこれを Python で行います。 2 つの文字列リテラルを一緒に記述するだけでも、それらが連結されます。
* 演算子を使用して、指定した回数だけ文字列を繰り返すことができます。
# Python String Operations
str1 = 'Hello'
str2 ='World!'
# using +
print('str1 + str2 = ', str1 + str2)
# using *
print('str1 * 3 =', str1 * 3) 上記のプログラムを実行すると、次の出力が得られます:
str1 + str2 = HelloWorld! str1 * 3 = HelloHelloHello
2 つの文字列リテラルを一緒に記述すると、+ のように連結されます
異なる行の文字列を連結したい場合は、括弧を使用できます。
>>> # two string literals together
>>> 'Hello ''World!'
'Hello World!'
>>> # using parentheses
>>> s = ('Hello '
... 'World')
>>> s
'Hello World' 文字列の繰り返し
for ループを使用して文字列を反復処理できます。以下は、文字列内の 'l' の数をカウントする例です。
# Iterating through a string
count = 0
for letter in 'Hello World':
if(letter == 'l'):
count += 1
print(count,'letters found') 上記のプログラムを実行すると、次の出力が得られます:
3 letters found
文字列メンバーシップ テスト
キーワード in を使用して、部分文字列が文字列内に存在するかどうかをテストできます .
>>> 'a' in 'program'
True
>>> 'at' not in 'battle'
False Python で動作する組み込み関数
シーケンスで機能するさまざまな組み込み関数は、文字列でも機能します。
一般的に使用されるもののいくつかは enumerate() です と len() . enumerate() 関数は列挙オブジェクトを返します。文字列内のすべての項目のインデックスと値がペアとして含まれています。これは反復に役立ちます。
同様に、len() 文字列の長さ (文字数) を返します。
str = 'cold'
# enumerate()
list_enumerate = list(enumerate(str))
print('list(enumerate(str) = ', list_enumerate)
#character count
print('len(str) = ', len(str)) 上記のプログラムを実行すると、次の出力が得られます:
list(enumerate(str) = [(0, 'c'), (1, 'o'), (2, 'l'), (3, 'd')] len(str) = 4
Python 文字列の書式設定
エスケープ シーケンス
He said, "What's there?"
のようなテキストを出力したい場合 、一重引用符も二重引用符も使用できません。これは SyntaxError になります テキスト自体に一重引用符と二重引用符の両方が含まれているためです。
>>> print("He said, "What's there?"")
...
SyntaxError: invalid syntax
>>> print('He said, "What's there?"')
...
SyntaxError: invalid syntax この問題を回避する 1 つの方法は、三重引用符を使用することです。または、エスケープ シーケンスを使用することもできます。
エスケープ シーケンスはバックスラッシュで始まり、別の方法で解釈されます。一重引用符を使用して文字列を表す場合、文字列内のすべての一重引用符をエスケープする必要があります。二重引用符の場合も同様です。上記のテキストを表現する方法は次のとおりです。
# using triple quotes
print('''He said, "What's there?"''')
# escaping single quotes
print('He said, "What\'s there?"')
# escaping double quotes
print("He said, \"What's there?\"") 上記のプログラムを実行すると、次の出力が得られます:
He said, "What's there?" He said, "What's there?" He said, "What's there?"
Python でサポートされているすべてのエスケープ シーケンスのリストは次のとおりです。
| エスケープ シーケンス | 説明 |
|---|---|
| \改行 | バックスラッシュと改行は無視 |
| \\ | バックスラッシュ |
| \' | 一重引用符 |
| \" | 二重引用符 |
| \a | ASCII ベル |
| \b | ASCII バックスペース |
| \f | ASCII フォームフィード |
| \n | ASCII 改行 |
| \r | ASCII キャリッジ リターン |
| \t | ASCII 水平タブ |
| \v | ASCII 垂直タブ |
| \ooo | 8 進値 ooo を持つ文字 |
| \xHH | 16 進値 HH の文字 |
ここにいくつかの例があります
>>> print("C:\\Python32\\Lib")
C:\Python32\Lib
>>> print("This is printed\nin two lines")
This is printed
in two lines
>>> print("This is \x48\x45\x58 representation")
This is HEX representation エスケープ シーケンスを無視する生の文字列
文字列内のエスケープシーケンスを無視したい場合があります。これを行うには、r を配置します。 または R 弦の前。これは、それが生の文字列であり、その中のエスケープ シーケンスが無視されることを意味します。
>>> print("This is \x61 \ngood example")
This is a
good example
>>> print(r"This is \x61 \ngood example")
This is \x61 \ngood example 文字列をフォーマットする format() メソッド
format() string オブジェクトで使用できるメソッドは、文字列の書式設定において非常に用途が広く強力です。フォーマット文字列に中かっこ {} が含まれています 置き換えられるプレースホルダーまたは置換フィールドとして。
位置引数またはキーワード引数を使用して順序を指定できます。
# Python string format() method
# default(implicit) order
default_order = "{}, {} and {}".format('John','Bill','Sean')
print('\n--- Default Order ---')
print(default_order)
# order using positional argument
positional_order = "{1}, {0} and {2}".format('John','Bill','Sean')
print('\n--- Positional Order ---')
print(positional_order)
# order using keyword argument
keyword_order = "{s}, {b} and {j}".format(j='John',b='Bill',s='Sean')
print('\n--- Keyword Order ---')
print(keyword_order) 上記のプログラムを実行すると、次の出力が得られます:
--- Default Order --- John, Bill and Sean --- Positional Order --- Bill, John and Sean --- Keyword Order --- Sean, Bill and John
format() メソッドには、オプションのフォーマット仕様を指定できます。これらは、コロンを使用してフィールド名から区切られます。たとえば、< を左揃えにすることができます 、右寄せ > またはセンター ^ 指定されたスペースの文字列。
整数を 2 進数、16 進数などにフォーマットすることもできます。浮動小数点数は丸めたり、指数形式で表示したりできます。使用できるフォーマットはたくさんあります。 format() で利用可能なすべての文字列フォーマットについては、こちらをご覧ください メソッド。
>>> # formatting integers
>>> "Binary representation of {0} is {0:b}".format(12)
'Binary representation of 12 is 1100'
>>> # formatting floats
>>> "Exponent representation: {0:e}".format(1566.345)
'Exponent representation: 1.566345e+03'
>>> # round off
>>> "One third is: {0:.3f}".format(1/3)
'One third is: 0.333'
>>> # string alignment
>>> "|{:<10}|{:^10}|{:>10}|".format('butter','bread','ham')
'|butter | bread | ham|' 古いスタイルのフォーマット
古い sprintf() のように文字列をフォーマットすることもできます C プログラミング言語で使用されるスタイル。 % を使用します
>>> x = 12.3456789
>>> print('The value of x is %3.2f' %x)
The value of x is 12.35
>>> print('The value of x is %3.4f' %x)
The value of x is 12.3457 一般的な Python 文字列メソッド
文字列オブジェクトで使用できるメソッドは多数あります。 format() 上記の方法はその1つです。一般的に使用されるメソッドのいくつかは lower() です 、 upper() 、 join() 、 split() 、 find() 、 replace() など。Python で文字列を操作するためのすべての組み込みメソッドの完全なリストを次に示します。
>>> "PrOgRaMiZ".lower()
'programiz'
>>> "PrOgRaMiZ".upper()
'PROGRAMIZ'
>>> "This will split all words into a list".split()
['This', 'will', 'split', 'all', 'words', 'into', 'a', 'list']
>>> ' '.join(['This', 'will', 'join', 'all', 'words', 'into', 'a', 'string'])
'This will join all words into a string'
>>> 'Happy New Year'.find('ew')
7
>>> 'Happy New Year'.replace('Happy','Brilliant')
'Brilliant New Year' Python