


多層パーセプトロンニューラルネットワークをトレーニングする方法
非表示ノードのレイヤーを追加することで、パーセプトロンのパフォーマンスを大幅に向上させることができますが、これらの非表示ノードはトレーニングを少し複雑にします。
これまでのニューラルネットワークに関するAACシリーズでは、ニューラルネットワークを使用したデータ分類、特にパーセプトロンの種類について学習しました。
以下のシリーズに追いつくか、多層パーセプトロン(MLP)ニューラルネットワークの基本を説明するこの新しいエントリに飛び込んでください。
- ニューラルネットワークを使用して分類を実行する方法:パーセプトロンとは何ですか?
- 単純なパーセプトロンニューラルネットワークの例を使用してデータを分類する方法
- 基本的なパーセプトロンニューラルネットワークをトレーニングする方法
- 単純なニューラルネットワークトレーニングを理解する
- ニューラルネットワークのトレーニング理論の概要
- ニューラルネットワークの学習率を理解する
- 多層パーセプトロンを使用した高度な機械学習
- シグモイド活性化関数:多層パーセプトロンニューラルネットワークでの活性化
- 多層パーセプトロンニューラルネットワークをトレーニングする方法
- 多層パーセプトロンのトレーニング式とバックプロパゲーションを理解する
- Python実装のためのニューラルネットワークアーキテクチャ
- Pythonで多層パーセプトロンニューラルネットワークを作成する方法
- ニューラルネットワークを使用した信号処理:ニューラルネットワーク設計での検証
- ニューラルネットワークのデータセットのトレーニング:Pythonニューラルネットワークをトレーニングおよび検証する方法
多層パーセプトロンニューラルネットワークとは何ですか?
前回の記事では、単層パーセプトロンでは、最新のニューラルネットワークアーキテクチャに期待されるようなパフォーマンスを実現できないことを示しました。線形分離可能関数に限定されたシステムでは、実際の信号処理シナリオで発生する複雑な入出力関係を概算することはできません。解決策は、次のような多層パーセプトロン(MLP)です。
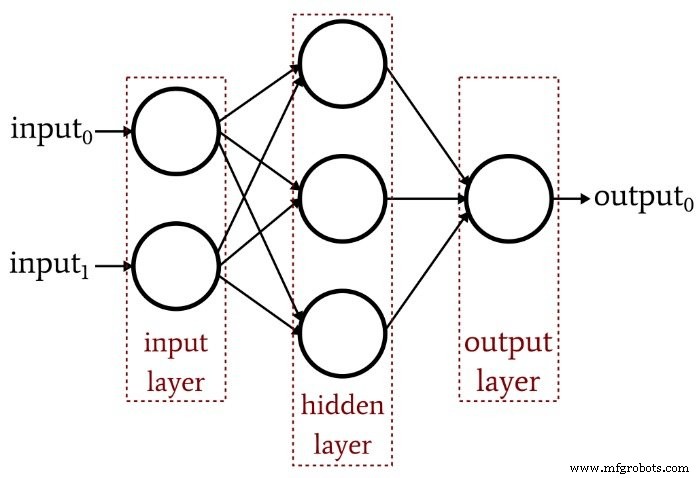
その隠れ層を追加することで、ネットワークを「普遍近似定理」に変え、非常に高度な分類を実現できます。しかし、ニューラルネットワークの価値はそのトレーニングの質に完全に依存していることを常に覚えておく必要があります。豊富で多様なトレーニングデータと効果的なトレーニング手順がなければ、ネットワークは入力サンプルの分類方法を「学習」することはありません。
隠しレイヤーがトレーニングを複雑にするのはなぜですか?
以前の記事で単層パーセプトロンをトレーニングするために使用した学習ルールを見てみましょう:
\ [w_ {new} =w +(\ alpha \ times(output_ {expected} -output_ {calculated})\ times input)\]
この方程式の暗黙の仮定に注意してください。観測された出力に基づいて重みを更新するため、これが機能するには、単層パーセプトロンの重みが出力値に直接影響する必要があります。これは、ホットとコールドの2つのノブを回して、水道水の温度を選択するようなものです。全体的な温度とノブの動作の関係はかなり単純で、数学が苦手な人でも、ノブを少しいじることで目的の水温を見つけることができます。
しかし、ここで、高温パイプと低温パイプを通る水の流れが、複雑で非線形性の高い方法でノブの位置に関連していると想像してください。お湯のつまみをゆっくりゆっくりと回しますが、結果として生じる流量は不規則に変化します。冷水用のノブを試してみても、同じことができます。これらの条件下で理想的な水温を決定することは、特に「出力」が2つの紛らわしい制御関係の組み合わせによって達成されなければならないため、はるかに困難になります。
これが私が隠された層のジレンマを理解する方法です。入力ノードを非表示ノードに接続する重みは、概念的には機械的に不安定なノブに類似しています。入力から非表示への重みには出力レイヤーへの直接パスがないため、これらの重みとネットワークの出力の関係はそうです。上記の単純な学習ルールは効果的ではないという複雑さ。
新しいトレーニングパラダイム
元のパーセプトロン学習ルールは多層ネットワークには適用できないため、トレーニング戦略を再考する必要があります。これから行うことは、最急降下法と誤差関数の最小化を組み込むことです。
覚えておくべきことの1つは、このトレーニング手順は多層ニューラルネットワークに固有のものではないということです。最急降下法は一般的な最適化理論に基づいており、MLPに採用しているトレーニング手順は単層ネットワークにも適用できます。ただし、私が理解しているように、MLPスタイルの最急降下法は(少なくとも理論的には)単層パーセプトロンには不要です。上記のより単純なルールで最終的には仕事が完了するからです。
MLPの実際の体重更新方程式を導き出すには、この時点でインテリジェントに説明しようとはしない、恐ろしい数学が含まれます。この記事の残りの部分での私の目的は、最急降下法と誤差関数というMLPトレーニングの2つの重要な側面の概念を紹介することです。その後、新しい活性化関数を組み込んで、この議論を次の記事で続けます。
最急降下法
名前が示すように、最急降下法は、勾配に基づいて誤差関数の最小値に向かって下降する手段です。次の図は、勾配が重みを変更する方法に関する情報を提供する方法を示しています。誤差関数上の点の傾きは、進む必要のある方向と最小値からの距離を示しています。
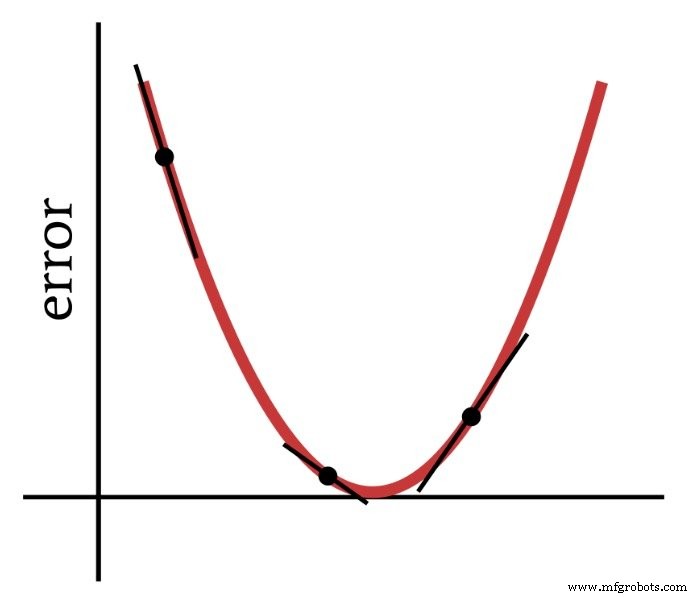
したがって、誤差関数の導関数は、多層パーセプトロンをトレーニングするために使用する計算の重要な要素です。実際には、部分的が必要です ここで派生物。最急降下法を実装する場合、各重みの変更を、変更される重みに対する誤差関数の傾きに比例させます。
エラー関数(別名損失関数)
ニューラルネットワークのエラーを定量化する一般的な方法は、各出力ノードの期待値(または「ターゲット」)値と計算値の差を2乗し、これらの2乗された差をすべて合計することです。これを「差の二乗和」または「二乗和誤差」などと呼ぶことができます。また、トレーニングの目的は平均を最小化することであるため、最小平均二乗を表す略語LMSも表示されます。二乗誤差。この誤差関数(Eで示される)は、数学的に次のように表すことができます。
\ [E =\ frac {1} {2} \ sum_k(t_k-o_k)^ 2 \]
ここで、kは出力ノードの範囲を示し、tはターゲット出力値、oは計算された出力値です。
結論
多層パーセプトロンのトレーニングを成功させるための基礎を築きました。次の記事では、この興味深いトピックを引き続き調査します。
産業用ロボット
- ネットワークトポロジー
- 自動車電気技師になるためのトレーニング方法
- サイバー攻撃を防ぐためにデバイスを強化する方法
- CEVA:ディープニューラルネットワークワークロード用の第2世代AIプロセッサ
- ニューラルネットワークトレーニングにおける極小値の理解
- ネットワークエコシステムがファームの未来をどのように変えているか
- インテリジェントネットワークとは何ですか?それはあなたのビジネスにどのように役立ちますか?
- ネットワークセキュリティキーとは何ですか?それを見つける方法は?
- 人工ニューラルネットワークは無線通信を強化することができます
- 製造現場のネットワークはどの程度安全ですか?
- インダストリー4.0はどのように明日の労働力を訓練しますか?