


データレイクと産業用アプリケーションのビッグデータ
データレイクとビッグデータは、しばしば誤解され、誤って使用される2つの現代的な用語です。暗黙の大量のデータのため、これらの用語は同じ意味で使用されることがあります。ただし、現在の定義がまだ完全に確立されていない場合でも、データレイクとビッグデータは異なります。

図1。 最新のデータは多くのソースから取得でき、さまざまなタイプのものがあります。 AnalyticsVidhyaの好意により使用された画像
まず、簡単な歴史的背景を見てみましょう。 2000年代後半、FacebookやTwitterなどのソーシャルメディアプラットフォームの爆発的な成長に伴い、多くのデータサイエンティストは、大量の貴重な個人データを生成するためのそのようなプラットフォームの可能性に気づき始めました。その結果、データ処理と分析を容易にするために新しいソフトウェアアプリケーションが開発されました。顕著な例の1つは、Apache Hadoopです。これは、本質的に、ビッグデータレベルの情報を処理できるオープンソースアプリケーションのツールキットです。
次の10年で、モノのインターネット(IoT)が登場しました。これにより、製品自体に関する情報を送信しながら、個人の好みやパターンに関する洞察を提供できる、さらに多くのデータソースへの扉が開かれました。
同時に、機械学習は重要な進歩を遂げ、産業環境でより実用的なアプリケーションを見つけていました。その結果、業界、特に自動化されたプロセスで大量のデータを処理する必要性が高まりました。
すべての予測は、世界で利用可能なデータの総量が今後数年間で加速的に拡大し続けることを示しています。参考までに、2016年に、世界は1ゼタバイトの年間インターネットトラフィックのマイルストーンを通過しました。 1ゼタバイトは1兆ギガバイトに相当します。
年間インターネットトラフィックは2021年に3ゼタバイトを超えると予想されます。これらの予測は、クラウドコンピューティングの拡張機能とともに、ビッグデータ(およびデータレイク)の価値と使用がおそらく始まったばかりであることを示しています。
ビッグデータとは何ですか?
ボリュームの観点から単純に見ると、ビッグデータの定義は動く目標です。利用可能なデータとストレージスペースの量が増え続けるにつれて、大量の情報と見なされるもののベンチマークも増えます。
今日、サイズが100テラバイト以上のデータリポジトリは、一般的にビッグデータの範囲内にあると見なされています。ソーシャルメディアプラットフォームのような大規模なデータリポジトリは、数ペタバイトの範囲にある可能性があります。
ビッグデータを定義するために使用されるもう1つの参照は、SQLなどの従来のコンピューターツールでは大量の情報を処理できない場合です。たとえば、今日、データベースのサイズが年間1テラバイトに達することは珍しくありません。しかし、SQLアプリケーションがより強力になっても、この規模のデータベースは引き続き管理できます。したがって、通常、ビッグデータとは見なされません。
ビッグデータの4Vモデル
これまで、ボリュームの観点からビッグデータの定義を見てきました。考慮すべき他の3つの重要な要素があります:速度、多様性、および信憑性。これらは、ボリュームとともに、4Vモデルを形成します。
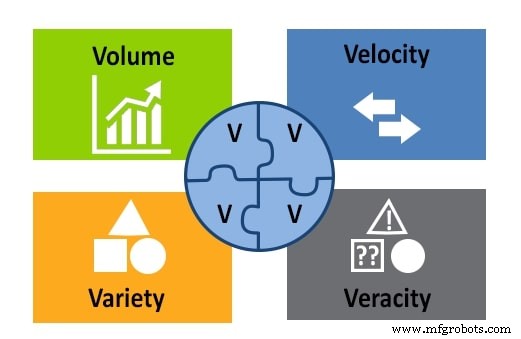
図2。 ビッグデータの4Vモデル:ボリューム、速度、多様性、および正確性。 APSenseの厚意により使用された画像
バラエティとは、ビッグデータリポジトリに保存されているさまざまな種類のデータ(テキスト、画像、音声、動画など)を指します。また、データが複数のソースから取得される可能性があることも指します。
情報は絶えずストリーミングされるため、速度はビッグデータの重要な考慮事項です。速度は、データの収集、生成、および配布の速度に関係します。
Veracityは、データの正確性と品質を測定して、データサイエンティストがデータを分析し、そこから結論を出すために使用できるかどうかを評価します。
ビッグデータを理解したので、制御システムでこれらを使用する方法に飛び込む前に、データレイクを確認しましょう。
データレイクとは何ですか?
データレイクは、大量の生データの集中リポジトリです。これは、将来価値がある場合とない場合があり、その目的がまだ100%わかっていない情報です。データレイクは、他の種類のファイルやエンティティとともに、リレーショナルデータベースと非リレーショナルデータベースを格納する場合があります。
データレイク内の情報は処理または整理されていませんが、すべての入力と出力が優れたアーキテクチャを作成すると見なされるように構成されています。
データレイクとビッグデータ
データレイクは、ビッグデータアプリケーションのインスタンスです。これらは、4Vモデルで説明されている基準に従いますが、いくつかの特殊性が追加されています。ボリュームの観点から、データレイクは平均してビッグデータと見なされるものの下限に近いです。
データレイク内の情報にはさまざまなものがありますが、条件は未処理の生データのみであるということです。入力速度と出力速度は、最新のシステムと同様に関連性があり、データ品質の評価は、適切に設計されたデータレイクで実行されます。
データの産業用アプリケーション
高度な自動化により、工場で処理される情報量が急速に増加しています。このおかげで、製造業やその他の産業プロセスがビッグデータの領域に入り、いくつかのビジネス活動でデータレイクなどのツールが使用されるようになりました。
1つの顕著な例は、予知保全です。機械的または電気的な障害を予測する機能は非常に価値があり、修理コストを大幅に節約できます。データレイクは、ログファイル、複数のセンサー、入力デバイスからの情報を収集できる便利なツールであり、傾向を理解して問題を予測するために使用できます。
機械学習は、ロボットが変化する外部条件に適応するのに役立つ情報をロボットに提供するという概念です。情報の取得は予知保全に似ていますが、プロセスの評価と変更がシステムコントローラに自動的に送られるという追加の手順があります。機械学習データは、構造化されたデータレイクに保存できます。
図3。 機械学習にはいくつかの戦略があり、それぞれが大量のデータを必要とします。 WordStreamの好意で使用された画像
結論として、データレイクはビッグデータアプリケーションのインスタンスです。データを表示するこれらの2つの方法は連携して機能します。ビッグデータとデータレイクの両方を利用することで、制御エンジニアは障害の予測、メンテナンスルーチンの作成、施設のデジタルトランスフォーメーションの拡大などを行うことができます。
仕事でビッグデータとデータレイクを何に使用しますか?
モノのインターネットテクノロジー
- センサーとプロセッサーは、産業用アプリケーション向けに統合されています
- Cervoz:産業用アプリケーションに適したフラッシュストレージの選択
- GEは産業データ、分析のためのクラウドサービスを導入します
- 産業用IoTの開発の見通し
- 産業用モノのインターネットの4つの大きな課題
- センサー情報に基づくアプリケーションを成功させるための6つの重要事項
- ビッグデータを理解する方法:RTUとプロセス制御アプリケーション
- 産業データサイエンスの成功のための準備
- 実際の産業用インターネットインサイト:データをキャプチャするだけでなく、それを使用する
- ビッグデータは、健康予算を悪化させるためのすべての治療法を提供しますか?
- 7産業用IoTアプリケーション