


2つの深層学習モデルの組み合わせ
ディープラーニングは、産業用アプリケーションを含むさまざまな分野の新しいアプリケーションを使用するデータアナリストにとって非常に貴重なツールです。ディープラーニングの基本的な動作原理は、大量のデータを使用して、正確な予測を行うことができるモデルを構築することです。
産業用自動化エンジニアが2つの深層学習モデルを組み合わせる必要性に遭遇する可能性がある小さな例を考えてみましょう。スマートフォン会社は、複数のモデルのスマートフォンを製造する生産ラインを採用しています。深層学習アルゴリズムを採用したコンピューター化されたビジョンは、生産ラインの品質管理を実行します。
現在、生産ラインは電話Aと電話Bの2つのスマートフォンを製造しています。モデルAとBは、それぞれ電話AとBの品質管理を実行します。同社は新しいスマートフォン、Phone Cを発表しました。生産施設では、モデルCと呼ばれる3番目の電話の品質管理を実行するために新しいモデルが必要になる場合があります。新しいモデルの構築には膨大な量のデータと時間が必要です。
図1。 の好意で使用されたビデオ マットチャン
もう1つの方法は、モデルAとモデルBからの学習を組み合わせて、モデルCを構築することです。組み合わせたモデルは、重みをわずかに調整するだけで品質管理を実行できます。
モデルを組み合わせる必要があるもう1つのシナリオは、新しいモデルが2つのタスクを同時に実行する必要がある場合です。 2つの深層学習モデルがこれらのタスクを実行できます。データセットを分類し、各カテゴリで予測を行う必要があるモデルは、2つのモデルを組み合わせることで作成できます。1つは大規模なデータセットを分類でき、もう1つは予測を行うことができます。
アンサンブル学習
複数の深層学習モデルを組み合わせることは、アンサンブル学習です。これは、深層学習モデルのより良い予測、分類、またはその他の機能を作成するために行われます。アンサンブル学習では、さまざまな深層学習モデルの機能を組み合わせた新しいモデルを作成することもできます。
新しいモデルを作成することは、新しいモデルを完全にゼロからトレーニングすることに比べて多くの利点があります。
- ほとんどの学習は結合されたモデルから派生しているため、結合されたモデルをトレーニングするために必要なデータはごくわずかです。
- 新しいモデルを作成する場合に比べて、結合されたモデルを作成する方が時間がかかりません。
- 新しい組み合わせモデルは、新しいモデルを取得するために組み合わせたモデルよりも高い精度と機能を備えています。
アンサンブル学習にはさまざまな利点があるため、新しいモデルを作成するために実行されることがよくあります。それぞれの深層学習アルゴリズム、パッケージ、およびトレーニング済みモデルは、異なるモデルを組み合わせる必要があり、最も高度な深層学習アルゴリズムはPythonで記述されています。
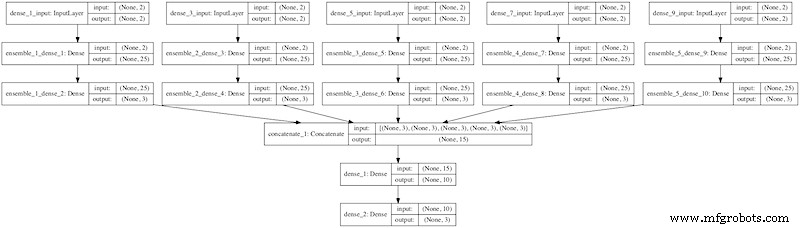
図2。 Pythonでニューラルネットワークを深層学習するためのスタッキングアンサンブル。使用した画像 機械学習の習得
Pythonと使用されるそれぞれの深層学習ツールを知ることは、さまざまなモデルを組み合わせるための前提条件です。これらがすべて整ったら、さまざまな手法を実装して、さまざまな深層学習アルゴリズムを組み合わせます。次のセクションで説明します。
(加重)平均法
この方法では、2つのモデルの平均が新しいモデルとして使用されます。これは、2つの深層学習モデルを組み合わせる最も簡単な方法です。 2つのモデルの単純平均をとって作成されたモデルは、2つのモデルを組み合わせたものよりも精度が高くなります。
結合されたモデルの精度と結果をさらに改善するには、加重平均が実行可能なオプションです。さまざまなモデルに与えられる重みは、モデルのパフォーマンスまたは各モデルが受けたトレーニングの量に基づく可能性があります。この方法では、2つの異なるモデルを組み合わせて新しいモデルを形成します。
バギング方法
同じ深層学習モデルは、複数の反復を持つことができます。さまざまな反復は、さまざまなデータセットでトレーニングされ、さまざまなレベルの改善があります。同じ深層学習モデルの異なるバージョンを組み合わせることは、バギング方法です。
方法論は、平均化方法と同じです。同じ深層学習モデルの異なるバージョンは、単純平均または加重平均の方法で組み合わされます。この方法は、単一のモデルで確証バイアスが構築されていない新しいモデルを作成するのに役立ち、モデルをより正確で高性能にします。
ブースティング方法
ブースティングの方法は、モデルにフィードバックループを使用するのと似ています。モデルのパフォーマンスは、後続のモデルを調整するために使用されます。これにより、モデルの成功に寄与するすべての要因を蓄積する正のフィードバックループが作成されます。
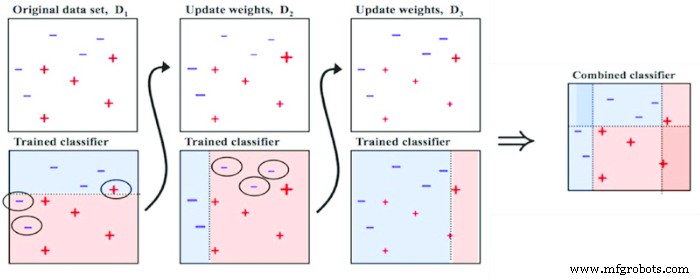
図3。 アンサンブル学習のためのブースティング方法。使用した画像 Ashish Patel
ブースティング方法は、モデルが経験するバイアスと分散を減らします。これは、そのような負の側面が後続の反復で除外されるために可能です。ブースティングは、重量ベースのブースティングと残差ベースのブースティングの2つの異なる方法で実行できます。
連結方法
この方法は、異なるデータソースを同じモデルにマージする場合に使用されます。この組み合わせ手法は、さまざまな入力を受け取り、それらを同じモデルに連結します。結果のデータセットは、元のデータセットよりも多くのディメンションを持ちます。
連続して複数回実行すると、データのディメンションが非常に大きくなり、重要な情報が過剰適合して失われる可能性があり、結合されたモデルのパフォーマンスが低下する可能性があります。
スタッキング方法
アンサンブル深層学習モデルのスタッキング方法は、さまざまな方法を統合して、前の反復のパフォーマンスを使用して前のモデルを後押しする深層学習モデルを開発します。この積み重ねられたモデルに加重平均を取る要素を追加すると、サブモデルのプラスの貢献度が向上します。
同様に、バギング手法と連結手法をモデルに追加できます。さまざまな手法を組み合わせてモデルを組み合わせる方法により、組み合わせたモデルのパフォーマンスを向上させることができます。
深層学習モデルを組み合わせるために使用できる方法論、手法、およびアルゴリズムは無数にあり、常に進化しています。より良い結果を提供する同じタスクを達成するための新しい技術があります。モデルの組み合わせについて知っておくべき重要なアイデアを以下に示します。
- ディープラーニングモデルの組み合わせは、アンサンブル学習とも呼ばれます。
- さまざまなモデルを組み合わせて、深層学習モデルのパフォーマンスを向上させます。
- 組み合わせて新しいモデルを構築するために必要な時間、データ、計算リソースは少なくて済みます。
- モデルを組み合わせる最も一般的な方法は、複数のモデルを平均化することです。加重平均をとると、精度が向上します。
- バギング、ブースティング、連結は、深層学習モデルを組み合わせるために使用される他の方法です。
- スタック型アンサンブル学習では、さまざまな組み合わせ手法を使用してモデルを構築します。
モノのインターネットテクノロジー