


データ サイエンスの概要 |主要コンポーネント |種類と機会
データ サイエンスとは
データ サイエンスは、科学的な方法、プロセス、システムを使用して、構造化および非構造化形式のデータを収集、準備、分析する学際的な分野です。データサイエンスは、数学、統計学、データベース、情報科学、コンピューターサイエンスなど、さまざまな分野を利用しています。データは、多くの種類とさまざまなサイズにすることができます。
別の分野としてのデータ サイエンスの必要性:
データ サイエンスを別の分野のレベルにアップグレードする主な理由は、私たちの周りのデータが指数関数的に増加していることです。推定では、2020 年までに毎秒約 1.7 メガバイトのデータが生成されることが示されています。デジタル データの蓄積は 44 兆ギガバイトに達するでしょう。このように大量のデータがあると、データの意味を理解して保存することがますます難しくなります。その結果、このデータを研究して理解する方法が必要になります。したがって、データサイエンスは別の分野として認識されました。 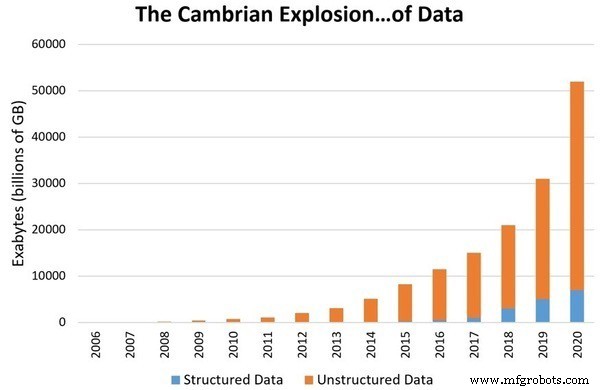
身の回りのデータ サイエンス:
企業はデータ サイエンスを使用して、社内のデータ プロセスを理解し、簡単に分類しています。たとえば、Google はデータ サイエンスを使用して、ユーザーが使用する Web サイトでユーザーに表示される広告をパーソナライズします。これは、サイト運営者がターゲット ユーザーにコンテンツを提供できるようにするプログラム AdSense を通じて行われます。
同様に、Uber は顧客に請求する金額、いつ、誰に割引を提供するかを計算します。 Airbnb は、データ サイエンスを使用して家を借りる必要がある価格を見積もることで、人々を支援します。簡単に言えば、これは顧客とユーザーを生データと考えることで理解でき、データ サイエンスはそのデータの解釈に役立ちます。 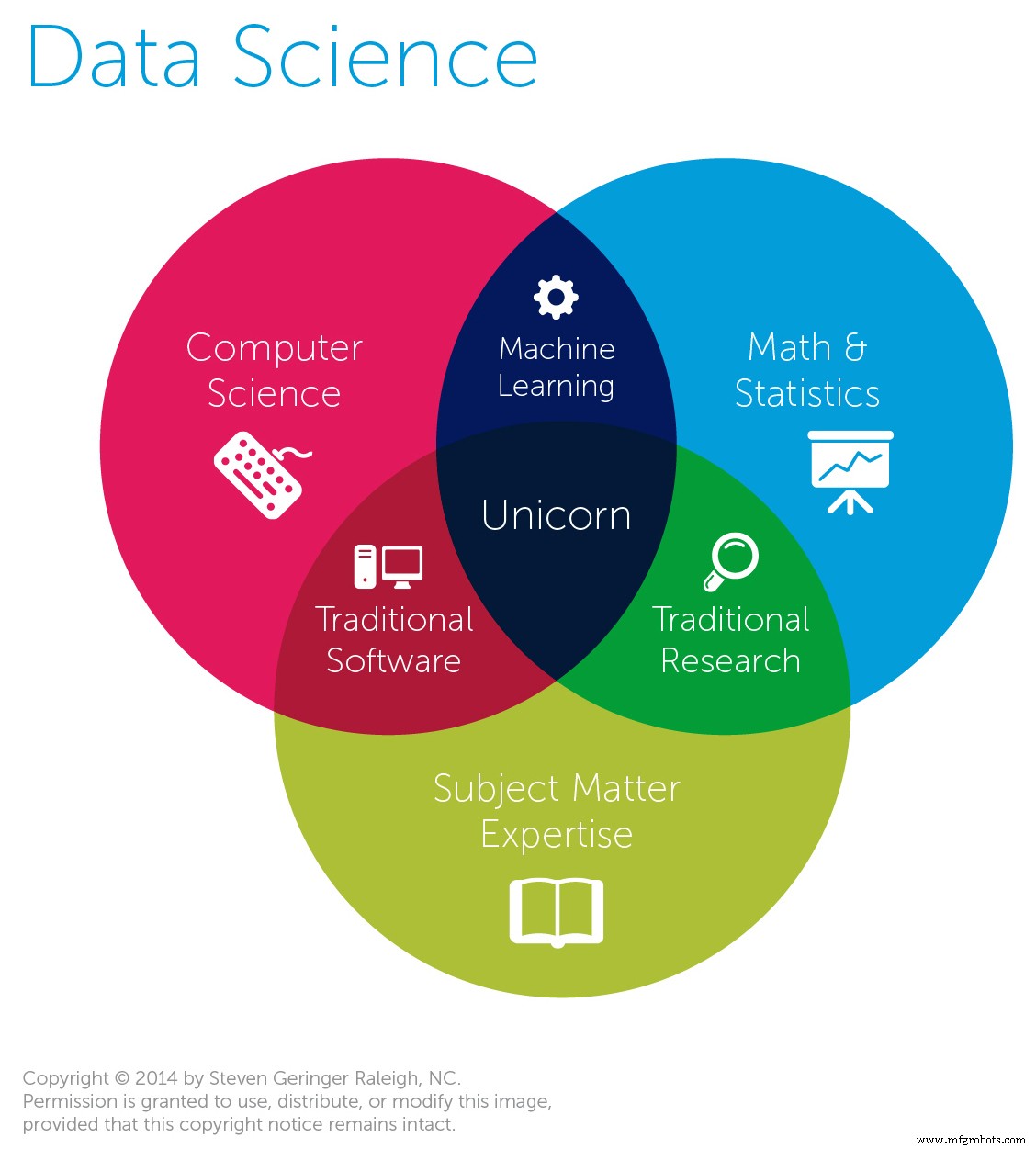
政府および非政府組織におけるデータ サイエンス:
政府機関にとってデータは重要な資産です。収集されるデータの量は毎日増加しています。したがって、データサイエンスを通じて実行できる、このすべてのデータを並べ替えて保存する方法が必要です。同様に、非政府組織もデータ サイエンスを使用しています。 WWF は、データ サイエンスを使用して、野生生物の問題に関する統計事項に情報を表示し、その原因を効果的にします。
データ サイエンスの機会:
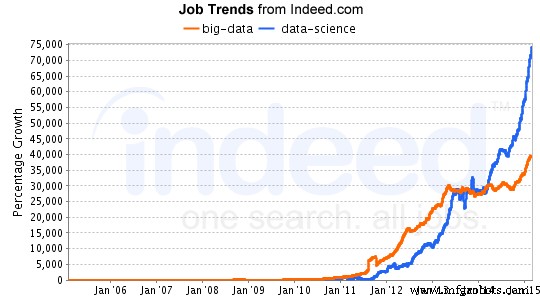
データ サイエンスの分野が成長し続けるにつれて、この分野での雇用機会も指数関数的に増加しています。データ サイエンスの仕事の成長について LinkedIn が行った分析では、特に過去 30 年間で、データ サイエンスの分野で大幅な増加が見られました。データ サイエンスに興味がある場合は、オンラインで無料のコースを受講できます。コモン ラウンジでこのチュートリアルをご覧ください。
主なコンポーネント:
ここでは、データ サイエンスとそのさまざまな要素について説明します。
1:プログラミング:
データ サイエンスはデータがすべてです。このデータを整理して分析するために、プログラミングを使用します。プログラミング言語にはさまざまな種類があります。最も普及しているのは、Python と R の 2 つです。
パイソン: Python は最も読みやすく柔軟なプログラミング言語であるため、広く使用されています。 NumPy と pandas、Matplotlib、Tensorflow、iPython などを含む多くの強力な統計および数値パッケージがあります。Python ははるかに高速で習得が容易です。
R: R は別のプログラミング言語ですが、そのほとんどは統計的およびグラフィカルな手法に焦点を当てています。 R は、統計ソフトウェアやデータ分析を開発するために、統計学者やデータ マイナーの間で広く使用されています。オープンソース言語です。
2:データとそのタイプ:
次の重要な要素はデータそのものです。データを理解するには、まずその型を理解する必要があります。
構造化データ: 構造化データとは、高度に組織化された情報を指します。表形式で簡単に表すことができ、データベースに保存して処理することができます。
非構造化データ: 非構造化データとは、データ モデルを持たない、または整理されていない情報です。日付、数字、電子メール、PDF ファイル、画像、動画などのテキストまたはデータで構成されている場合があります。
自然言語: 英語、スペイン語、ウルドゥー語などの通信に使用される書き言葉の形式のデータ。非構造化データのサブタイプと見なすことができます。
画像、動画、音声: 画像、ビデオ、およびオーディオも形式が構造化されていません。それらは、カメラとマイクを使用して生成されます。画像や動画が毎日保存され、処理されるスマートフォンでの使用の増加が見られます。
グラフベースのデータ: グラフは頂点と辺の集合です。これは、2 つのエンティティ間の関係を示すために使用される数学的構造です。
機械生成: 機械生成データは、人間の関与なしにコンピューター システム、アプリケーション、または機械によって作成されます。
3:統計、確率、およびデータ サイエンスとの関係:
統計: 統計学は、データの収集、解釈、分析、提示、および編成を扱う数学の一分野です。 pro0gamming ti を使用してデータを分析します。
確率: 確率は、イベントが発生する可能性の尺度です。これは 0 から 1 までの数値として定量化され、0 は不可能を示し、1 は確実であることを示します。
データ サイエンスとの関係: 統計と確率はどちらもデータ サイエンスに関連しています。これらは、データの処理と分析の基盤です。データを正しく解釈するために、データ サイエンスに関連してこれらの両方の科学を使用します。
4:機械学習:
機械学習は、AI に端を発するコンピューター サイエンスの分野です。統計的手法を使用して、コンピューターにプログラミングなしで学習する能力を与えます。機械は、構造またはプログラムを変更することによって、特定のタスクのパフォーマンスを徐々に向上させます。機械学習の主な目的は 3 つあります。 1つは、変化とその変化の表現を学ぶことです。第二に、パフォーマンスを一般化して、単一のタスクだけでなく、同様のタスクでも同様に効果的であること。三番。マシンのパフォーマンスを向上させ、パフォーマンスの低下を防ぐ方法を見つける。データサイエンスでは、機械学習はアルゴリズム、回帰、および分類方法で使用されます。さまざまな方法で処理されるデータからの結果を予測するために使用されます。
5:ビッグデータ:
ビッグ データはデータに付けられた名前で、このデータを格納または処理するには大量のコンピュータが必要になるほど大量です。 3 つの V が特徴です:
ボリューム: テラバイトからゼタバイトに及ぶ大量のデータ。
バラエティ: データは、多くの多様性と多様性を示すことができます。たとえば、構造化データと非構造化データの両方など、2 種類以上のデータが混在している可能性があります。
速度: データは常に増加する速度で生成されています。本質的にそれはデータの速度です。 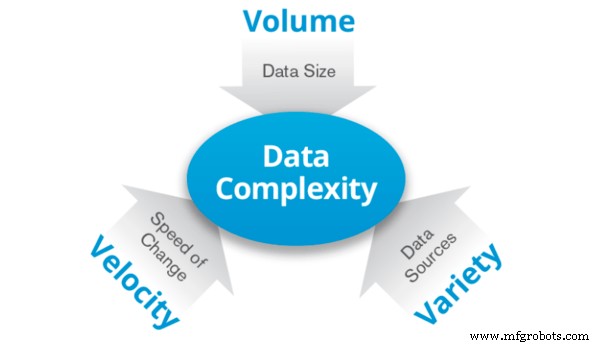
データ サイエンスでは、データは多くの形式と種類にグループ化されます。ビッグデータは、従来のアプリケーションでは処理できない膨大な量のデータを参照できます。データ サイエンティストは、Hadoop、Spark、R、Java など、さまざまなツールを使用してビッグ データを研究および処理します。
産業技術