


ニューラルネットワークのトレーニングデータセット:Pythonニューラルネットワークをトレーニングおよび検証する方法
この記事では、Excelで生成されたサンプルを使用して多層パーセプトロンをトレーニングし、検証サンプルを使用してネットワークがどのように機能するかを確認します。 。
Pythonニューラルネットワークの開発を検討している場合は、適切な場所にいます。 Excelを使用してネットワークのトレーニングデータを開発する方法に関するこの記事の説明を詳しく説明する前に、以下のシリーズの残りの部分で背景情報を確認することを検討してください。
- ニューラルネットワークを使用して分類を実行する方法:パーセプトロンとは何ですか?
- 単純なパーセプトロンニューラルネットワークの例を使用してデータを分類する方法
- 基本的なパーセプトロンニューラルネットワークをトレーニングする方法
- 単純なニューラルネットワークトレーニングを理解する
- ニューラルネットワークのトレーニング理論の概要
- ニューラルネットワークの学習率を理解する
- 多層パーセプトロンを使用した高度な機械学習
- シグモイド活性化関数:多層パーセプトロンニューラルネットワークでの活性化
- 多層パーセプトロンニューラルネットワークをトレーニングする方法
- 多層パーセプトロンのトレーニング式とバックプロパゲーションを理解する
- Python実装のためのニューラルネットワークアーキテクチャ
- Pythonで多層パーセプトロンニューラルネットワークを作成する方法
- ニューラルネットワークを使用した信号処理:ニューラルネットワーク設計での検証
- ニューラルネットワークのデータセットのトレーニング:Pythonニューラルネットワークをトレーニングおよび検証する方法
トレーニングデータとは何ですか?
実際のシナリオでは、トレーニングサンプルは、ニューラルネットワークがこのすべての情報を一貫した入出力関係に一般化するのに役立つ「ソリューション」と組み合わされたある種の測定データで構成されます。
たとえば、ニューラルネットワークで、色、形、密度に基づいてトマトの食味を予測したいとします。色、形、密度が全体的な美味しさとどのように正確に相関しているかはわかりませんが、 色、形、密度を測定すれば、 味蕾があります。したがって、あなたがする必要があるのは、何千ものトマトを集め、それらの関連する物理的特性を記録し、それぞれを味わい(最良の部分)、そしてこのすべての情報をテーブルに入れることです。
各行は私が1つのトレーニングサンプルと呼んでいるもので、4つの列があります。これらの3つ(色、形状、密度)は入力列で、4つ目はターゲット出力です。
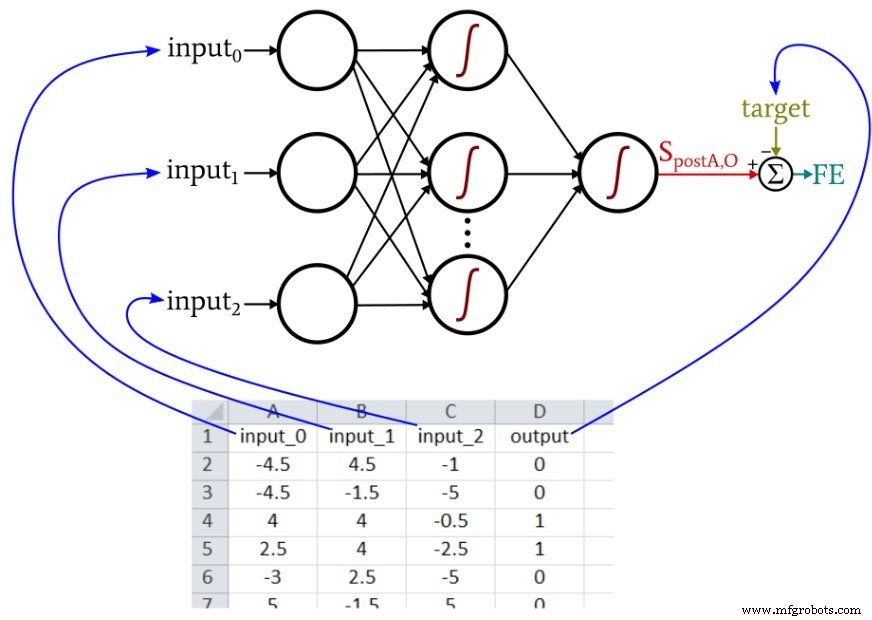
トレーニング中に、ニューラルネットワークは3つの入力値と出力値の間の関係(コヒーレントな関係が存在する場合)を見つけます。
トレーニングデータの定量化
すべてが数値形式で処理される必要があることに注意してください。文字列「プラム型」をニューラルネットワークへの入力として使用することはできません。また、「食欲をそそる」は出力値として機能しません。測定値と分類を定量化する必要があります。
形状については、各トマトに–1から+1までの値を割り当てることができます。ここで、–1は完全な球形を表し、+ 1は非常に細長いことを表します。食事の質については、各トマトを「食べられない」から「おいしい」までの5段階で評価し、ワンホットエンコーディングを使用して評価を5要素の出力ベクトルにマッピングできます。
次の図は、このタイプのエンコーディングがニューラルネットワークの出力分類にどのように使用されるかを示しています。
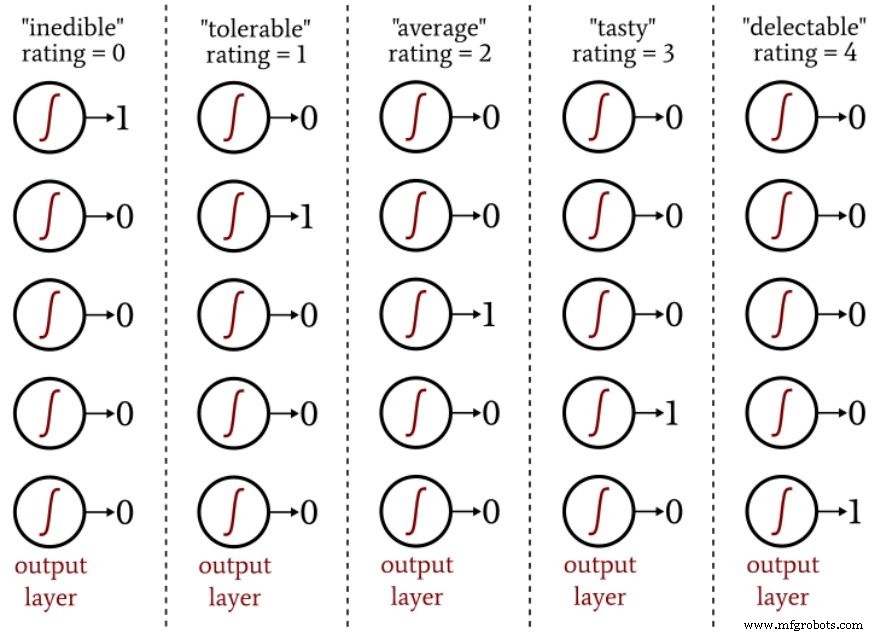
ワンホット出力スキームにより、ロジスティックシグモイドアクティベーションと互換性のある方法で非バイナリ分類を定量化できます。ロジスティック関数の出力は、出力値が最小値または最大値に非常に近い入力値の無限の範囲と比較して曲線の遷移領域が狭いため、基本的にバイナリです。
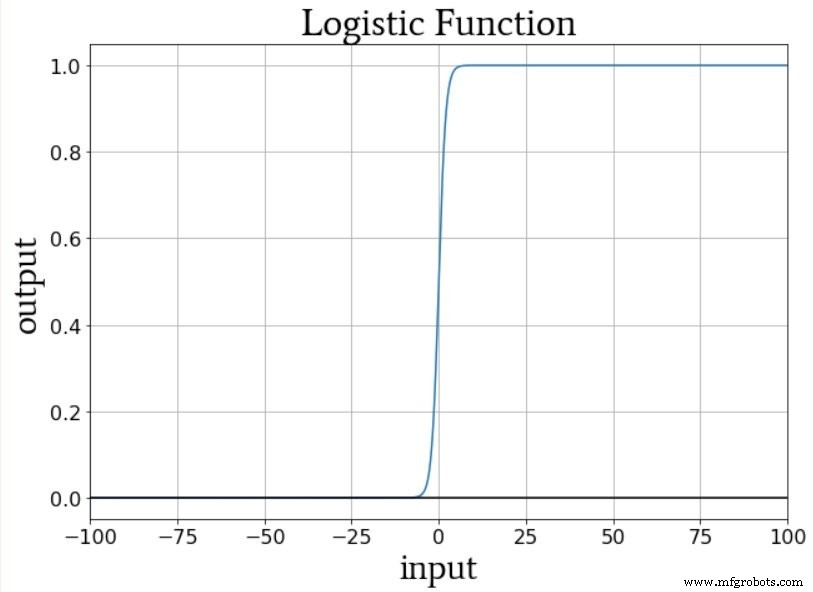
したがって、このネットワークを単一の出力ノードで構成してから、出力値が0、1、2、3、または4(0、0.2、0.4、0.6、または0.8)のトレーニングサンプルを提供することは望ましくありません。 0から1の範囲にとどまりたい場合);出力ノードのロジスティック活性化関数は、最小および最大の評価を強く支持します。
ニューラルネットワークは、すべてのトマトが食べられないか、おいしいと結論付けることがどれほど馬鹿げているかを理解していません。
トレーニングデータセットの作成
パート12で説明したPythonニューラルネットワークは、Excelファイルからトレーニングサンプルをインポートします。この例で使用するトレーニングデータは、次のように構成されています。
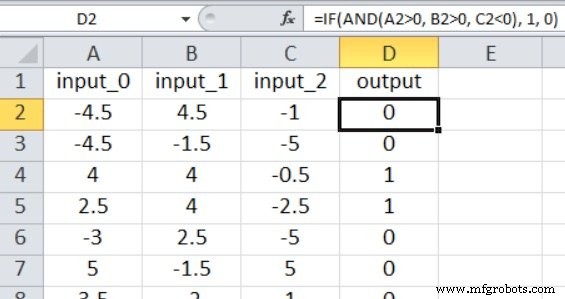
現在のパーセプトロンコードは1つの出力ノードに制限されているため、真/偽のタイプの分類を実行するだけです。入力値は、次のExcel式を使用して生成された–5〜 +5の乱数です。
=RANDBETWEEN(-10、10)/ 2
スクリーンショットに示されているように、出力は次のように計算されます。
=IF(AND(A2> 0、B2> 0、C2 <0)、1、0)
したがって、input_0がゼロより大きく、input_1がゼロより大きく、input_2がゼロより小さい場合にのみ、出力はtrueになります。そうでなければ、それは誤りです。
これは、パーセプトロンがトレーニングデータから抽出する必要のある数学的な入出力関係です。必要な数のサンプルを生成できます。このような単純な問題の場合、5000サンプルと1エポックで非常に高い分類精度を達成できます。
ネットワークのトレーニング
入力の次元を3に設定する必要があります( I_dim =3、私の変数名を使用している場合)。 4つの非表示ノード( H_dim )を持つようにネットワークを構成しました =4)、そして私は0.1( LR =0.1)。
training_data =pandas.read_excel(...)を見つけます ステートメントを作成し、スプレッドシートの名前を挿入します。 (Excelにアクセスできない場合は、PandasライブラリでODSファイルを読み取ることもできます。)次に、[実行]ボタンをクリックするだけです。私の2.5GHzWindowsラップトップでは5000サンプルのトレーニングに数秒しかかかりません。
パート12に含めた完全な「MLP_v1.py」プログラムを使用している場合、検証(次のセクションを参照)はトレーニングが完了した直後に開始されるため、ネットワークをトレーニングする前に検証データを準備する必要があります。
ネットワークの検証
ネットワークのパフォーマンスを検証するために、2つ目のスプレッドシートを作成し、まったく同じ式を使用して入力値と出力値を生成します。次に、トレーニングデータをインポートするのと同じ方法で、この検証データをインポートします。
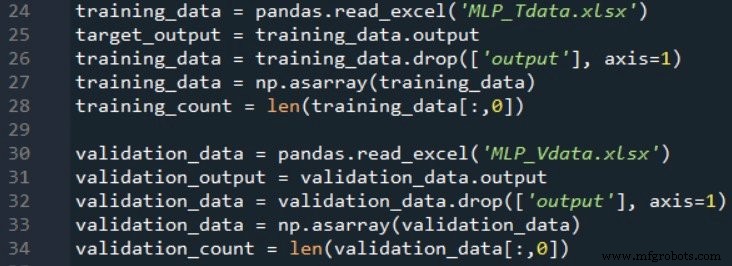
次のコードの抜粋は、基本的な検証を実行する方法を示しています。
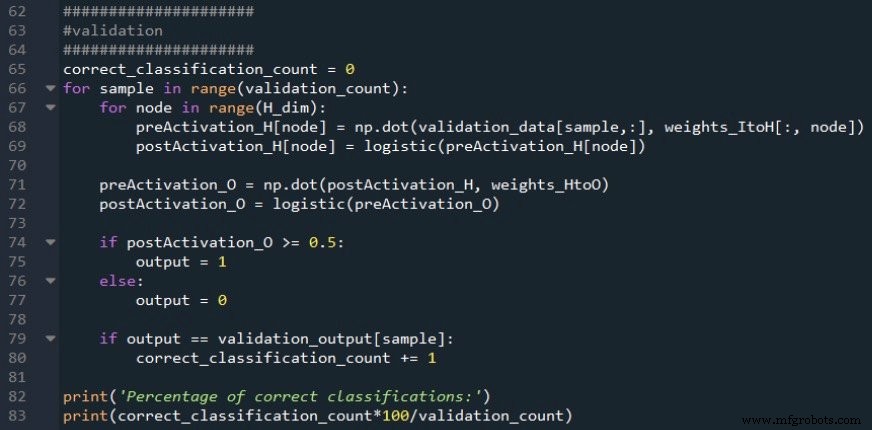
標準のフィードフォワード手順を使用して出力ノードのアクティブ化後の信号を計算してから、if / elseステートメントを使用して、アクティブ化後の値をtrue / false分類値に変換するしきい値を適用します。
分類の精度は、分類値を現在の検証サンプルの目標値と比較し、正しい分類の数を数え、検証サンプルの数で割ることによって計算されます。
np.random.seed(1)がある場合は、覚えておいてください。 コメントアウトされた命令では、プログラムを実行するたびに重みが異なるランダム値に初期化されるため、分類の精度は実行ごとに変化します。上記で指定したパラメーター、5000のトレーニングサンプル、および1000の検証サンプルを使用して15回の個別の実行を実行しました。
分類精度の最低値は88.5%、最高値は98.1%、平均値は94.4%でした。
結論
ニューラルネットワークのトレーニングデータに関連するいくつかの重要な理論情報を取り上げ、Python言語の多層パーセプトロンを使用して最初のトレーニングと検証の実験を行いました。ニューラルネットワークに関するAACのシリーズを楽しんでいただければ幸いです。最初の記事から多くの進歩がありましたが、まだまだ話し合う必要があります。
産業用ロボット
- Pythonで現在の日付と時刻を取得するには?
- スパイキングニューラルネットワーク用のニューロモルフィックAIチップがデビュー
- VHDL シミュレーターとエディターを無料でインストールする方法
- ニューラルネットワークトレーニングにおける極小値の理解
- 隠れ層ニューラルネットワークの精度を上げる方法
- ニューラルネットワークにはいくつの隠しレイヤーと隠しノードが必要ですか?
- ニューラルネットワークを使用した信号処理:ニューラルネットワーク設計での検証
- 5Gの上位5つの問題と課題
- ワイヤレスセンサーネットワークにフィードしてケアする方法
- あなたと私のためのベッカーの真空ポンプトレーニング
- ロボット溶接のトレーニング時間を短縮する方法