


データサイエンスのライフサイクルを深く掘り下げる
ビッグデータの登場以来、現代のコンピュータサイエンスは、新しい機能と処理能力のベンチマークに到達しています。今日では、ビッグデータと見なされる100テラバイト以上のデータセットを生成するアプリケーションを見つけることは珍しくありません。
このように大量の情報が手元にあると、混乱しやすく、無駄なコンテンツで時間を無駄にすることがあります。これらが、ビッグデータプロジェクトの有効性と効率を高める方法論に従うことが非常に重要である2つの理由です。

図1。 現代のデータサイエンスは、ビッグデータとも呼ばれる非常に大きなデータセットで機能します。
データサイエンスのライフサイクルは、ビッグデータプロジェクトの定義、収集、整理、評価、および展開を支援するフレームワークを提供します。これは、論理的な順序で配置された一連のステップで構成される反復プロセスであり、フィードバックとピボットを容易にします。
ライフサイクルシーケンスはどのように見えますか?答えは、誰もが従う単一のユニバーサルモデルはないということです。ビッグデータプロジェクトを実施する多くの企業は、データサイエンスのライフサイクルをビジネスプロセスに適合させます。これには通常、より多くのステップが含まれます。それにもかかわらず、多くのモデルとプロセスフローにはすべて共通の分母があります。この記事では、最初で最も人気のあるデータサイエンスライフサイクルモデルの1つであるCRISP-DMプロセスモデルを使用します。
CRISP-DMモデル
CRISP-DMは、データマイニングの業界標準プロセスの略です。これは、情報技術(IT)の研究を促進するためのヨーロッパのプログラムであるESPRITによって1999年に最初に発行されました。 CRISP-DMモデルは、ビッグデータプロジェクトを導く6つのステップまたはフェーズで構成されています。問題に関する重要な質問を提起して回答することにより、利害関係者がビジネスについて考えるように促します。
CRISP-DMモデルの6つのフェーズを詳しく確認しましょう。
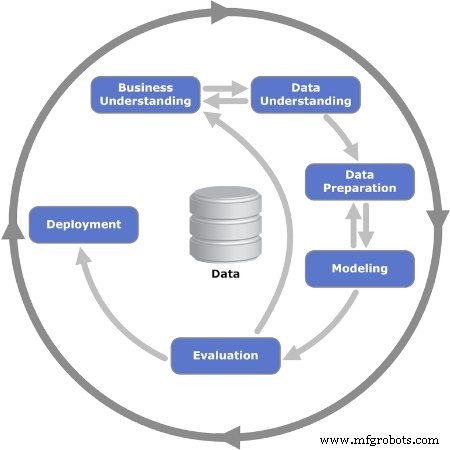
図2。 CRISP-DMモデルの反復的な6つのフェーズが示されています。使用した画像 ケネスジェンセン
フェーズ1:ビジネスの理解
最初のフェーズは、問題を定義し、目標を設定するいくつかのタスクで構成されます。これは、プロジェクトの目標がビジネス、つまり顧客に焦点を合わせて設定される場合です。通常、ビッグデータプロジェクトに取り組むために集まったチームは、顧客にソリューションを提供する必要があります。顧客は、社内の別の領域または部門である可能性があります。
ビジネスニーズまたは問題が確立されたら、次のステップは成功基準を定義することです。これらは、主要業績評価指標(KPI)またはサービスレベル契約(SLA)であり、進捗状況と完了を評価するための客観的な手段を提供します。
次に、ビジネス状況を分析して、リスク、ロールバック計画、緊急時対策、さらに重要なことに、リソースの可用性を特定する必要があります。マイルストーンリソースを含むプロジェクト計画が作成されます。
フェーズ2:データの理解
前のフェーズでファンダメンタルズが確立されたら、データに焦点を当てます。このフェーズは、必要と思われるデータの初期定義から始まり、データの場所、データの種類、形式、さまざまなデータフィールド間の関係など、そのデータに関する詳細を文書化します。
最初のドキュメントの準備ができたら、次のステップは最初のデータ収集の実行を実行することです。これは、構造がどのように形成されているかについての有用なスナップショットを提供します。次に、この情報のスナップショットの品質が評価されます。
フェーズ3:データの準備
3番目のフェーズでは、前のフェーズを強化し、モデリング用のデータセットを準備します。最初のコレクションのデータフィールドはさらに精選され、不要と思われる情報はセットから削除されます。これはデータのクリーニングと呼ばれます。
また、特定の情報は、入手可能な他の情報から導き出す必要がある場合があります。それ以外の場合は、組み合わせる必要があります。つまり、最終的な形式を作成するには、データを処理する必要があります。
フェーズ4:モデリング
このフェーズで最も重要なタスクは、収集されたデータを処理するアルゴリズムを選択することです。このコンテキストでは、アルゴリズムは、ビッグデータプロジェクト用に設計されたコンピューターソフトウェアでプログラムされた一連のシーケンスステップとルールです。
多くのアルゴリズムを使用できます。線形回帰、決定木、サポートベクターマシンなどがその例です。問題を解決するための適切なアルゴリズムを選択するには、経験豊富なデータサイエンティストが持っているスキルが必要です。
図3。 線形回帰は、ビッグデータモデリングで使用されるアルゴリズムの一種です。
次のステップは、アルゴリズムをソフトウェアアプリケーションにコーディングすることです。これは、テストと検証のために特定のデータセットを割り当てることで構成されるテストフェーズが計画されている場合でもあります。
フェーズ5:評価
最初からアルゴリズムを選択するのが難しい場合があります。これが発生すると、科学者はいくつかのアルゴリズムを実行し、結果を分析して最終決定を下します。テストフェーズが完了すると、結果の完全性と正確性が確認されます。
さらに重要なことに、これは結果が解決につながるかどうかを評価する機会です。反復モデルでは、これは主要な反復シーケンスを開始できる重要な交差点です。または、最終フェーズに進むという決定に達することができます。
フェーズ6:展開
これは、プロジェクトがテスト環境から実稼働環境に移行するときです。導入スケジュールと戦略を計画することは、リスクと潜在的なシステムのダウンタイムを減らすために非常に重要です。
モデル図はこれでプロジェクトが終了したことを示していますが、監視と保守という、その後のフォローアップにはまだ多くのステップがあります。モニタリングは、稼働直後の綿密な観察期間であり、ハイパーケアとも呼ばれます。メンテナンスは、実装されたソリューションをメンテナンスおよびアップグレードするための半永久的なプロセスです。
ビッグデータは、次の理由でそう呼ばれます。解析するデータが大量にあるからです。データサイエンスライフサイクルモデルの1つを実装すると、予知保全などのプロセスで保持および使用する価値のある情報を決定するのに役立ちます。
モノのインターネットテクノロジー