


高度なデータ分析のためのOCRとAIおよびRPAの組み合わせ
この投稿は共同執筆者です コスミンニコラエ。 NicolaeはUiPathのプロダクトマネージャーです。
非構造化データはいたるところにあり、ドキュメント、オーディオファイル、ビデオ、電子メール、画像、ログファイルなどの場所に隠れています。リストは続きます。実際、非構造化データは現在、すべてのデータの約80〜90%を占めています。それでも、その豊富さと価値にもかかわらず、非構造化データは、企業がデータを抽出して分析するために必要なツールを欠いているため、依然として最も無駄なエンタープライズリソースの1つです。
ビッグデータ分析とワークフローの自動化に対する需要が高まっているため、これは変化しています。どちらも構造化データを必要とします。印刷または手書きのテキストを機械でエンコードされたテキストに変換できる光学式文字認識(OCR)と呼ばれるテクノロジーを活用する企業が増えています。スタンドアロンテクノロジーとして、OCRは多少制限されています(詳細は以下を参照)。それでも、OCR、ロボティックプロセスオートメーション(RPA)、人工知能(AI)の3つの機能により、企業は高度なレベルのデータ処理と自動化を実現できます。
OCRは、2つのUiPathソリューションの主要コンポーネントの1つです。
-
UiPathドキュメントの理解により、さまざまなドキュメントの自動処理が可能になります
-
UiPath AI Computer Visionにより、開発者は仮想デスクトップ上および動的インターフェイスで自動化できます
このブログでは、UiPathがテクノロジーを使用して次世代のデータ処理と分析を可能にする方法を探りながら、OCRの概要を説明します。
まず、OCRの簡単な入門書です。
OCR:概要
素人の言葉で言えば、OCRはテキストを画像から編集可能なドキュメントに変換するプロセスです。
OCRは、特定のタスクの手作業を削減し、さらには排除することができます。その結果、バックエンドワークフローを迅速化すると同時に、ワーカーがより重要な責任を引き受けることができるようになります。
企業がOCRを使用する一般的な方法は次のとおりです。
1。データ入力の自動化
手動でのデータ入力には時間がかかり、エラーが発生しやすくなります。 OCRを使用することで、企業は人的介入の必要性を最小限に抑え、データの整合性を高めながら、事務処理をデジタル化できます。
2。ドキュメントの編集(スキャンまたはPDF)
従業員は、編集可能な形式ではないスキャンされたドキュメントやファックス通知を受け取ることがよくあります。これは、財務、供給管理、人材育成、法務、コンプライアンスなどの部門でよく見られるケースです。従来のスキャナーは、ドキュメントを画像またはPDFとしてのみエクスポートできます。たとえば、契約書や発注書をスキャンして、MicrosoftWordやGoogleドキュメントで編集することはできません。ただし、OCRエンジンを利用すると、テキストを認識して機械可読形式にエクスポートし、さらに編集および処理することができます。
3。視覚障害のある従業員を可能にする
視覚障害のある従業員は、紙の文書をデジタル形式に変換する必要があることがよくあります。 OCRは、書かれたテキストをテキスト読み上げに変換し、プロセスを合理化することで役立ちます。
4。ドキュメントの整理
OCRは、さまざまなドキュメントの山を自動的に並べ替え、特定のルールに従って整理できます。典型的な例は、タイプまたはベンダーに基づいて請求書を整理することです。または、住所をスキャンして郵便システムを介してメールをルーティングする方法を決定する郵便区分機で複数行OCR(MLOCR)を利用するなどの重要なプロセスで。
5。インターフェイスを介したテキストの理解
OCRを使用すると、リモートインターフェイスを介してデータを処理できるため、リモートチームのコラボレーションがより迅速かつ簡単になります。
OCRの制限
OCRは非常に強力ですが、スタンドアロンテクノロジーとして使用する場合はいくつかの制限があります。
OCRの主な制限のいくつかを次に示します。
1。 OCRはそれ自体ではデータを理解できません
何よりもまず、OCRはドキュメントからテキストをデジタル化して機械で読み取り可能にすることしかできません。 OCRは、補完的なメカニズムなしではデータを理解または解釈できません。そのため、OCRは、より大規模でインテリジェントなソリューション内のコンポーネントとして利用されることがよくあります。大規模な真のプロセス自動化を可能にするために、OCRとRPAはAIと組み合わされています。
2。 OCRにはコンテキストがありません
OCRシステムにもコンテキストがありません。たとえば、OCRシステムは、実際の単語がボールである場合に、単語を保釈として転記する場合があります。 OCRエンジン自体には、文の残りの部分をスキャンしてどの単語を使用すべきかを確認するために必要な認知機能がありません。このため、スタンドアロンテクノロジとしてのOCRはエラーが発生しやすくなります。エントリの正確性をチェックするには、ヒューマンインザループコンポーネントが必要です。その結果、OCR自体には自動化ツールとしての最適な価値がありません。
3。 OCRは変動性を処理できません
さらに、OCRはドキュメントのテキストやレイアウトの変動を処理できません。これは、構造が異なるドキュメントを処理するときに大きな問題になります。
4。 OCRはドキュメントを分離できません
自動化プロセスに含める前にファイルをドキュメントに分割する必要がある場合、またはワークフローのインデックスフィールドやキー値に繰り返しがある場合は、さらに問題が発生する可能性があります。
5。 OCRは正確またはスケーラブルではありません
結局のところ、純粋なOCRは、複雑で認知的なプロセスに対して十分に正確またはスケーラブルではありません。企業は、制限されてエラーが発生しやすいコンポーネントとは対照的に、成熟した柔軟なソリューションを必要としています。
ご覧のとおり、スタンドアロンテクノロジとしてのOCRは、今日の高度なエンタープライズワークフローをサポートするほど高度ではありません。それでも、RPAソフトウェアおよびAIと組み合わせると、OCRは非常に便利なツールになります。次のセクションでは、UiPathがOCRを使用して高精度の自動化を実現する方法について説明します。
ユースケース:UiPathドキュメント理解におけるOCR
UiPathドキュメント理解では、RPAとAIを使用してドキュメントのデータをデジタル化し、処理と分析を行えるようにします。ドキュメントの理解は、構造化データと非構造化データの両方を処理でき、手書き、表、チェックボックス、署名などのさまざまなオブジェクトで機能します。
ドキュメントの理解により、正確で柔軟なドキュメント処理、運用効率の向上、人的エラーのリスクの軽減、複雑なプロセスのエンドツーエンドの自動化など、多くのメリットが得られます。
ドキュメント理解テクノロジーはOCRではないことに注意してください。 2つが同じであるという事実は一般的な誤解です。むしろ、ドキュメントの理解は、OCRを利用して非デジタルドキュメントのテキストをデジタル化する高度なテクノロジーです。
注目すべき違いの1つは、UiPathがOCRをデータ抽出から切り離すことです。この分野の多くの企業には、抽出機能を備えたOCRが含まれています。 2つを分離することにより、UiPathは、抽出側で発生していることを中断することなく、必要に応じて別のOCRエンジンを選択できるようになるため、より多くの選択肢、柔軟性、および精度を提供します。必要に応じて、UiPathOCRパブリックコントラクトを使用して独自のOCRエンジンをデプロイすることもできます。
ドキュメントの理解でOCRを使用する方法
OCRは、ドキュメント理解プロセスの早い段階で機能します。分類法がワークフローに読み込まれ、すべてのファイルとデータが抽出用に定義された直後です。
ドキュメントの理解では、OCRエンジンを使用してテキストを検出およびデジタル化し、ロボットがテキストを読み取れるようにします。そこから、ドキュメントは指定されたリストから分類され、データが抽出されます。必要に応じて、人間は抽出されたデータを確認してから、関連するリポジトリにエクスポートできます。
UiPathドキュメントの理解では、独自のUiPathドキュメントOCRと、サードパーティのOCRエンジンを利用してテキストをデジタル化できます。お客様は、ユースケースに最も正確に機能するエンジンを選択できます。
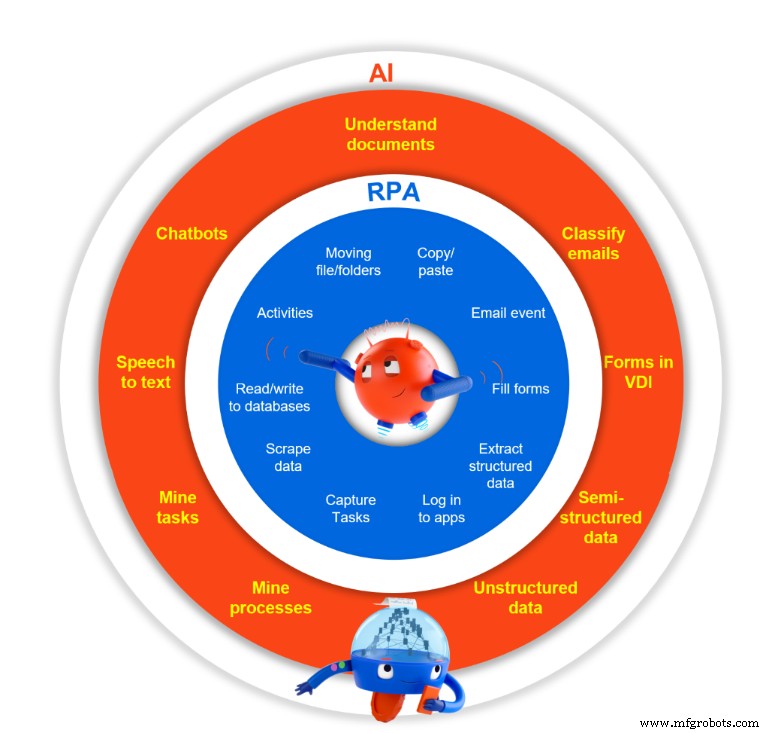
この図が示すように、OCRはUiPathドキュメント理解フレームワークの一部です。その唯一の目的は、テキストマシンを読み取り可能にすることです。
ユースケース:UiPathAIコンピュータービジョンのOCR
UiPath AI Computer Visionは、RPAの最大の課題の1つである、Citrix、VMware、Microsoft Windowsリモートデスクトップなどの仮想デスクトップインフラストラクチャ(VDI)の自動化を解決します。
AI Computer Visionを使用すると、ソフトウェアロボットは、非表示のプロパティに依存して意思決定を行うのではなく、コンピューター画面上のすべての要素を確認して理解できます。 AI Computer Visionを使用すると、企業やRPA開発者は、フレームワークやオペレーティングシステムに関係なく、VDIの自動化を実現できます。
AI Computer Visionは、ドロップダウンメニューやチェックボックスなどの動的ユーザーインターフェイス(UI)要素を含む自動化を可能にします。幅広いインターフェイスタイプをサポートします。このソリューションは、自動化の復元力と信頼性を高めながら、仮想マシンを自動化する際の実装時間を短縮できます。
AI Computer VisionはOCRを利用しますが、ドキュメントのデジタル化には使用されません。これは微妙ですが、よくある誤解です。
UiPath AIComputerVisionがOCRを使用する方法
リモートデスクトップは最終的には単なるビデオフィードであるため、標準のOCRとRPAを使用して仮想環境で自動化することは不可能です。テキストを解釈するには高度なソリューションが必要であり、さらに重要なのは、インターフェース内でのテキストのタイプと目的を理解することです。
AI Computer Visionは、過去数年間にUiPathで開発されたカスタム画面OCRを備えた高度なニューラルネットワークを利用して、仮想デスクトップフィード上のUIを分析し、人間のように理解します。このソリューションは、ボタンをクリックするだけでなく、テーブル全体の抽出やドロップダウンメニューの操作など、利用可能なインターフェイスを簡単にナビゲートできます。
AI Computer Visionは、要素の識別に、あいまいマッチングと呼ばれるテキスト解釈手法を使用します。この手法により、UiPath Robotsは、OCRの結果に一貫性がない場合でも、毎回正しい要素を識別できるため、結果として得られる自動化の信頼性が向上し、開発時間が短縮されます。
UiPathでOCRを次のレベルに引き上げる
ご覧のとおり、OCRを組み込んだAIベースのソリューションを使用することには大きな価値があります。 UiPathドキュメント理解ツールとUiPathコンピュータービジョンツールは、基本的なOCRをはるかに超えており、エンタープライズスケーラビリティを備えた迅速で信頼性の高い自動化を可能にします。これにより、非構造化データやVDIの背後にあるものなど、データの価値を最大限に引き出すことができます。
これは、ドキュメントの理解とコンピュータビジョンのどちらがニーズに適しているかを判断するのに役立つチャートです。
ドキュメントデータとVDIシステムを機能させる準備はできましたか?
開始するには、UiPathドキュメント理解とUiPathAIコンピュータービジョンの使用を今すぐ開始できるUiPathAutomationCloudに登録します。
無料のUiPathAutomationCloudトライアルを開始して、非構造化データを活用してビジネスプロセスの構造と効率を高めることがいかに簡単かを確認してください。
自動制御システム
- シークレットマネージャーで機密データを保存および管理する
- フィールドバスでさらに速く、さらに進む
- データのパックおよびアンパックのためのC言語の共用体
- 企業がIoTを活用して大規模なデータ収集と分析を行う方法
- Arch Systemsは、製造データ変換のためにFlexと提携しています
- インダストリーAIoT:インダストリー4.0向けの人工知能とIoTの組み合わせ
- 航空宇宙および防衛OEM向けのIIoTによる収益成長への新しい経路の開発
- 将来の展望:クレーン制御におけるAIとデータ分析
- スマートマニュファクチャリングのためのLitmusおよびOdenヒューズIIoTソリューション
- AIと製造業のビッグデータに関するPwCで5分
- データとAIで製造の課題に取り組む