


マルチコアプログラミングとデバッグの課題をマスターする
この記事では、さまざまなタイプのマルチコアプロセッサや、これらのデバイスが今日一般的で人気が高まっている理由など、マルチコア処理のさまざまな側面について説明します。次に、チップ上に複数のコアを搭載することによってもたらされるいくつかの課題と、最新のマルチコア対応デバッガーがこれらの複雑なタスクをより管理しやすくするためにどのように役立つかを見ていきます。
システムパフォーマンス
巧妙なコンパイラアルゴリズムから効率的なハードウェアソリューションに至るまで、組み込みコンピューティングシステムのパフォーマンスを向上させる方法はたくさんあります。コンパイラの最適化は、読みやすく理解しやすい高級言語コードから最も効率的な命令スケジューリングを取得するために重要です。これに加えて、システムはプロジェクトで利用可能な並列処理を利用して、一度に複数のものを処理できます。そしてもちろん、クロック周波数をスケーリングすることは、コンピューティングシステムからより多くのパフォーマンスを引き出すための効果的な方法です。
残念ながら、クロック速度が幾何学的に増加すると想定できる時代は過ぎ去りました。そして、コードの最適化は、何世代にもわたるコンパイラー技術の開発の後で、特に今、あなたにそれほど多くの改善をもたらすことができるだけです。これにより、時間の経過とともにシステムパフォーマンスを拡張し続けるための最良の機会として、並列処理に目を向けることができます。
並列処理

井戸を掘るのは、並列化するのが難しい作業です。他の人は土をかき集めて助けることができますが、穴を実際に掘るのは通常一人の仕事です。その結果、穴に人を追加しても、仕事が早く完了することはありません。実際、他の人が邪魔をしてプロセスを遅くする可能性があります。一部のタスクは並列化に適していません。
他のタスクは簡単に並列化できます。溝を掘ることは、並列化に適したタスクです。多くの人が隣同士で働くことができます。

この図は、MIMD、Multiple Instruction MultipleDataと呼ばれる並列処理の形式を示しています。各掘削機は個別のユニットであり、さまざまなタスクを実行できます。この場合、4人の掘り出し人が約1/4 th で仕事を終えることができると想像できます。 一人の掘り出し物の時間。
SIMD、単一命令複数データを使用すると、1人の掘削機がこのようなシャベルを使用する可能性があります。
SIMDユニットは、一度に1種類の計算しか実行できませんが、複数のデータに対して並行して実行できます。これらのタイプの命令は、多くのプロセッサのベクトル処理ユニットで一般的です。これは、データが非常に規則的であり、画像処理などの大規模なデータセットに対して同じ操作を繰り返し実行する必要がある場合に役立ちます。ただし、より一般的なコンピューティングタスクの場合、このモデルには柔軟性がなく、パフォーマンスが向上しません。
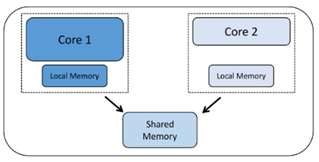
これにより、複数のフルCPUサブシステムを1つのチップに配置して、マルチコアプロセッサを作成することができます。 1つのチップ上の複数のコアでパフォーマンスを拡張できます。各コアはフルCPUであり、独立して、または他のコアと連携して動作できます。
さまざまなタイプのマルチコア処理
プロセッサチップ上にあるコアの種類のさまざまな組み合わせと、それらの間で作業がどのように分散されるかがあります。
同種のマルチコアプロセッサには、同じプロセッサコアのコピーが2つ以上あります。各コアは自律的に実行され、共有メモリやメールボックスシステムなどの多くのメカニズムを介して他のコアと通信および同期する場合があります。各プロセッサには独自のレジスタと機能ユニットがあり、独自のローカルメモリまたはキャッシュがある場合があります。ただし、これを均質にしているのは、私たちが見ているすべてのコアが同じタイプであるという事実です。
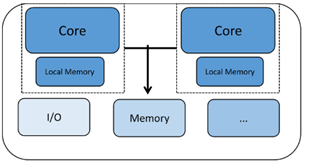
別のタイプのマルチコアチップは、2つ以上の異なる種類のCPUコアを備えたヘテロジニアスマルチコアと呼ばれます。ここで、コアは非常に異なる特性を持っている可能性があり、システム処理のニーズのさまざまな部分に適しています。一例として、一方のコアがBluetoothプロトコルスタックの管理専用で、もう一方のコアが外部通信、アプリケーション処理、ヒューマンインターフェイスなどを管理するBluetooth通信チップがあります。この種のマルチコアチップは、両方を必要とするアプリケーションに使用できます。一方のコアでのリアルタイム専用パフォーマンスと、もう一方のコアでのシステム管理機能。
次に、コアがどのように使用されるかを見ていきます。対称型マルチプロセッシング(SMP)は、複数のコアがあり、コアが同じプロジェクトコードベースを実行している場合に発生します。異なるコアが同時にコードの異なる部分を実行している可能性がありますが、コードは単一のプロジェクトとして構築され、リアルタイムオペレーティングシステム(RTOS)などの制御プログラムによって別々のコアにディスパッチされます。必然的に、このように機能するコアは、1つのタイプのプロセッサ用にコンパイルされた同じプロジェクトコードを使用するため、同じタイプである必要があります。
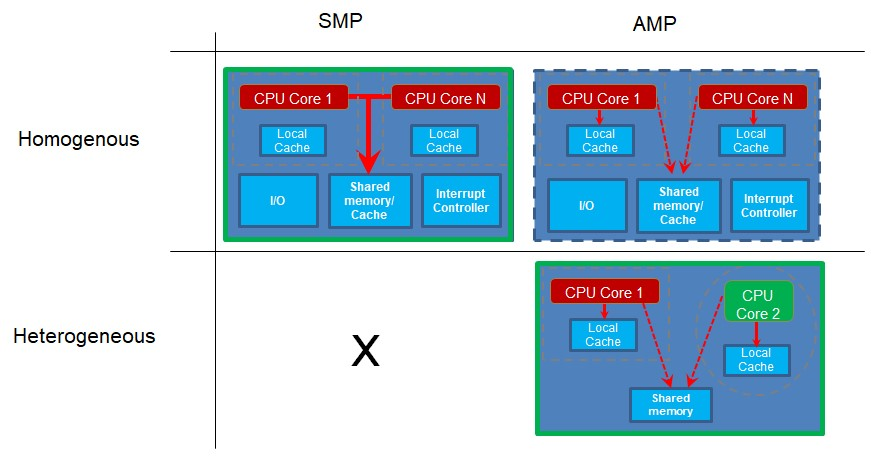
非対称型マルチプロセッシング(AMP)は、複数のコアまたはプロセッサがあり、各プロセッサが独自のプロジェクトアプリケーションを実行している場合に発生します。個別のコアは時々同期または通信する場合がありますが、それぞれが実行する独自のコードベースを持っています。それぞれが独自のプロジェクトを実行しているため、これらのコアは異なるタイプでも、異種コアでもかまいません。ただし、これは必須ではありません。同じタイプのコアが2つ以上異なるプロジェクトコードを実行している場合、それらは同種のコアであり、AMPを実行しています。
SMP操作の場合、すべてが同じ単一のプロジェクトコードベースからコードを実行するため、複数の同種コアが必要であることに注意してください。ただし、実行するコアごとに異なるコードベースを持つ複数のプロジェクトがある場合、これらは異種システムなどの異なるコアである可能性があります。ただし、コアが同じであれば、それも機能します。
マルチコアを使用する理由
過去数年にわたって、1960年代半ばに造られたムーアの法則は、ようやく勢いを失っているか、少なくとも減速しているように見えます。プロセッサのクロックレートは2〜3年ごとに倍増することはなくなり、実際、最高速度のCPUは、長年にわたって1桁の低いGHz範囲で上限に達しています。
パフォーマンスの限界を押し上げ続ける1つの方法は、効率的に使用できる場合は、より多くのCPUコアを連携させることです。
速度は頭打ちになっていますが、トランジスタのサイズは縮小し続けています。以前よりも低速ですが、小さなトランジスタにより、1つのチップにより多くのロジックを搭載できます。その結果、これらのトランジスタを使用して複数のCPUコアを単一のチップに配置すると、複数のCPUとメモリサブシステム間のはるかに高速で幅の広いバス相互接続を利用できます。
異種非対称マルチプロセッシングは、アプリケーションに非常に異なる特性と要件を持つ2つ以上のワークロードがある場合に非常に役立ちます。 1つはリアルタイムで割り込み遅延に依存する可能性があり、もう1つは応答時間よりもスループットに依存する可能性があります。このモデルは非常にうまく機能します。たとえば、デバイスがBluetoothやZigbeeなどの通信プロトコルスタックを管理するために1つのコアを専用にし、別のコアが人間の対話と全体的なシステム管理操作を実行するアプリケーションプロセッサとして機能する場合があります。通信プロセッサは分離されているため、プロトコルスタックに必要な優れたリアルタイム応答を提供できます。さらに、通信ソフトウェアは標準に認定されているため、システムのこの部分から機能の変更を分離することで、製品全体の認定が容易になります。
マルチコアを使用した課題
チップに複数のCPUコアを搭載すると、どのような課題が発生しますか?さて、それを掘り下げましょう。
モノリシックアプリケーションまたはソフトウェアは、利用可能なコンピューティングリソースを効率的に使用できない場合があります。複数のコアのリソースを使用するには、アプリケーションを同時に実行できる並列タスクに編成する必要があります。これには、ソフトウェアエンジニアが組み込み設計について考えるためのなじみのない方法が必要になる場合があります。既存のシングルループコードの移行は非常に簡単ではない場合があります。スレッドが少なすぎるか、スレッドが多すぎると、パフォーマンスの障壁になる可能性があります。
複数のスレッドまたはプロセス間でデータ構造またはI / Oデバイスを共有するアプリケーションには、シリアルのボトルネックが発生する可能性があります。データの整合性を維持するために、これらの共有リソースへのアクセスは、ロック技術(読み取りロック、読み取り/書き込みロック、書き込みロック、スピンロック、ミューテックスなど)を使用してシリアル化する必要がある場合があります。非効率的に設計されたロックは、共有リソースを使用するためにロックを取得しようとする複数のスレッドまたはプロセス間の高いロック競合のためにボトルネックを作成する可能性があります。これにより、アプリケーションまたはソフトウェアのパフォーマンスが低下する可能性があります。一部のコアが共通のロックを待機している他のコアを停止させ、2つのコアのパフォーマンスが1よりも低下した場合、コアまたはプロセッサの数が増えると、アプリケーションのパフォーマンスが低下する可能性があります。
不均一に分散されたワークロードは、コンピューティングリソースの利用において非効率的である可能性があります。大きなタスクを、並行して実行できる小さなタスクに分割する必要がある場合があります。パフォーマンスとスケーラビリティを向上させるために、シリアルアルゴリズムをパラレルアルゴリズムに変更する必要がある場合があります。ただし、一部のタスクが非常に高速に実行され、他のタスクにかなりの時間がかかる場合、クイックタスクは、長いタスクが完了するのを待つのにかなりの時間を費やす可能性があります。その結果、貴重なコンピューティングリソースがアイドリングし、パフォーマンスのスケーリングが低下します。
RTOSはおそらく役に立ちますが、すべてを解決できるわけではありません。 SMPシステムでは、これは事実上、多数の同様のコアでタスクをスケジュールするために必須です。実行する作業は、データまたは機能によって分割できます。物事をデータチャンクで分割すると、各スレッドが処理のパイプラインのすべてのステップを実行する可能性があります。または、1つのスレッドで関数の1つのステップを実行し、別のスレッドで次のステップを実行することもできます。一方の手法の他方に対する利点は、実行する作業の特性によって異なります。
マルチコア環境でのデバッグ
マルチコアシステムをデバッグするときに最初に役立つのは、すべてのコアの可視性です。理想的には、コアを同時にまたは個別に開始および停止できる必要があります。つまり、他のコアが実行または停止しているときに1つのコアをシングルステップで実行できる必要があります。マルチコアブレークポイントは、あるコアの動作を別のコアの状態に基づいて制御するのに非常に役立ちます。
マルチコアトレースの実装は非常に難しい場合があります。複数のコアからのトレース情報の高帯域幅を管理すること、およびさまざまな種類のコアからの潜在的にさまざまな種類のトレースデータを処理することは、実際の課題です。
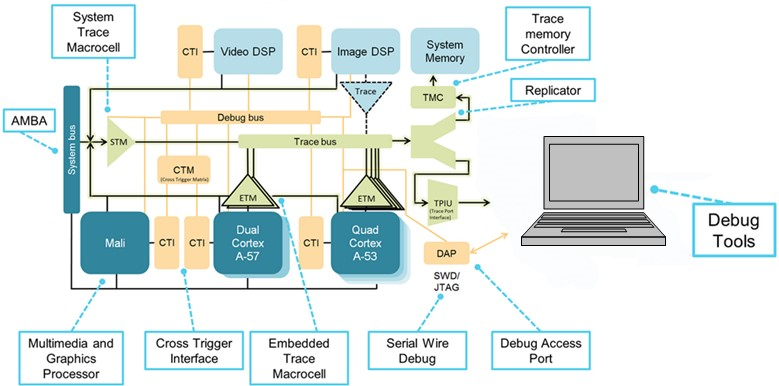
(出典:IAR Systems、Arm Ltd.提供の図)
これは、異種および同種のマルチコア実装の両方を備えたプロセッサの例です。 2つの同種のコアグループがあります。1つはデュアルArmCortex-A57に基づいており、もう1つはクアッドCortex-A53に基づいています。これらのグループは、それ自体では同質ですが、2つのグループ間では異質です。
CoreSightデバッグアーキテクチャは、すべてのコアのデバッグリソースと通信するためのプロトコルとメカニズムを提供し、このすべての情報を管理し、さまざまなコアからのメッセージを解析するのはデバッガーに任されています。クロストリガーインターフェイスとマトリックス(CTI、CTM)により、両方のコアの同時停止、トレースのトリガーなどが可能になります。トレースインフラストラクチャには、トレースフローを平滑化するために使用されるシリアル(SWD)およびパラレル(TPIU)トレースポートと、各ソースからのトレースを単一のフローに結合するトレースファネルが含まれます。デュアルコア部分と比較して、示されている図は、制御するのがはるかに複雑なチップを表しています。
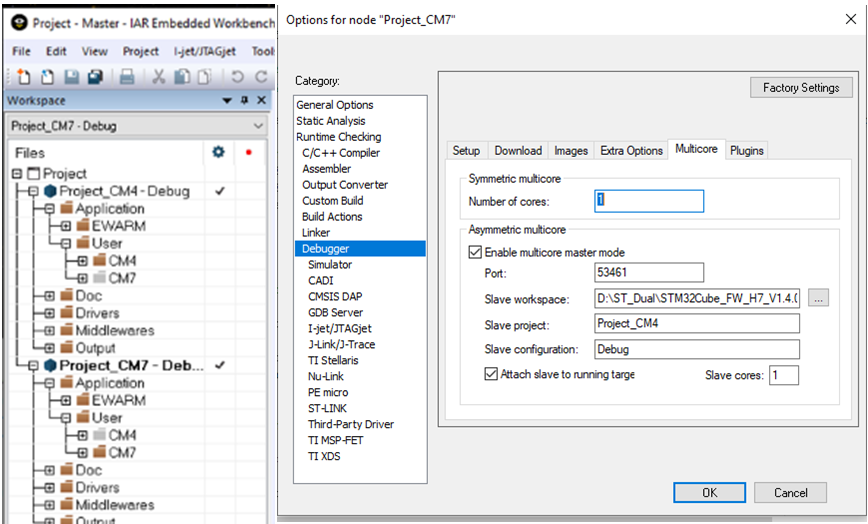
IAR Embedded WorkbenchのC-SPYデバッガは、対称および非対称の両方のマルチコアデバッグをサポートします。これは、[マルチコア]タブのデバッガーオプションで有効になります。対称マルチコアデバッグを有効にするには、コアの数を入力して、通信するさまざまなプロセッサの数をデバッガに通知するだけです。他のIDEでも同様のオプションを利用できる場合があります。
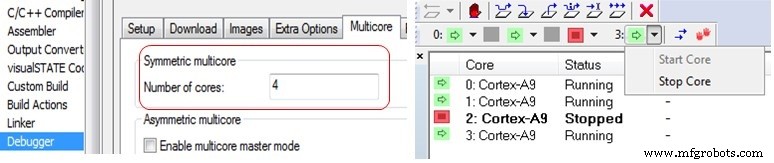
右側(上)では、4コアのCortex-A9 SMPクラスターのコアのステータスが表示され、他の3つのコアの実行中にコア番号2が停止している様子をデバッガーで確認できます。
非対称マルチコアシステムは、1つのCortex-M7コアと個別のCortex-M4を持つST STM32H745 / 755のような異種マルチコアパーツを使用する場合があります。この場合、デバッガーを実行すると、IDEの2つのインスタンス(マスターとノード)が使用されます。 2つのコアが異なるプロジェクトコードを実行しているため、コアごとに1つ。
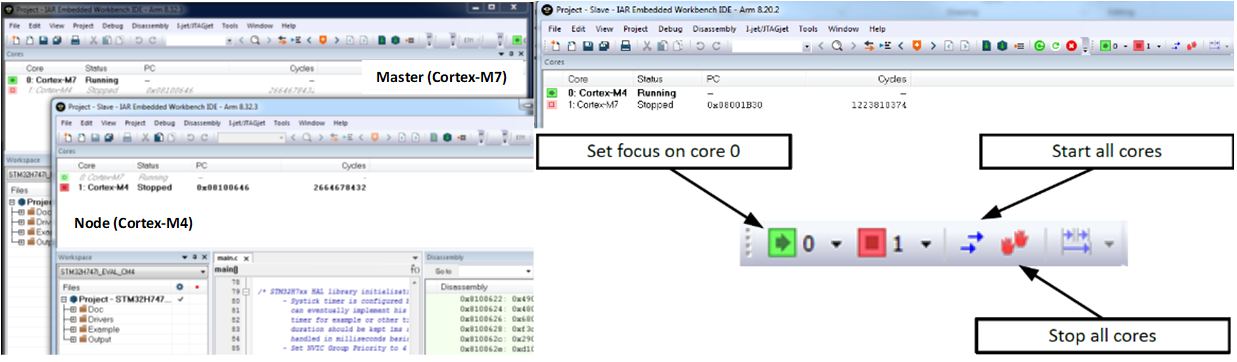
IDEの各インスタンスには、制御されているコアと、他のウィンドウで制御されている他のコアに関するステータス情報があります。コアを一緒にまたは別々に開始および停止することが開発者の制御下にあるように、デバッガーの動作を制御するために選択できるオプションがあります。
この完全な制御は、クロストリガーインターフェイス(CTI)とクロストリガーマトリックス(CTM)が一緒になってArm組み込みクロストリガー機能を形成することで可能になります。 3つのCTIコンポーネントがあり、1つはシステムレベル、1つはCortex-M7専用、もう1つはCortex-M4専用です。次の図に示すように、3つのCTIはCTMを介して相互に接続されています。システムレベルおよびCortex-M4CTIは、システムアクセスポートおよび関連するAPB-Dを介してデバッガーにアクセスできます。 Cortex-M7 CTIはCortex-M7コアに物理的に統合されており、Cortex-M7アクセスポートを介してアクセスできます。
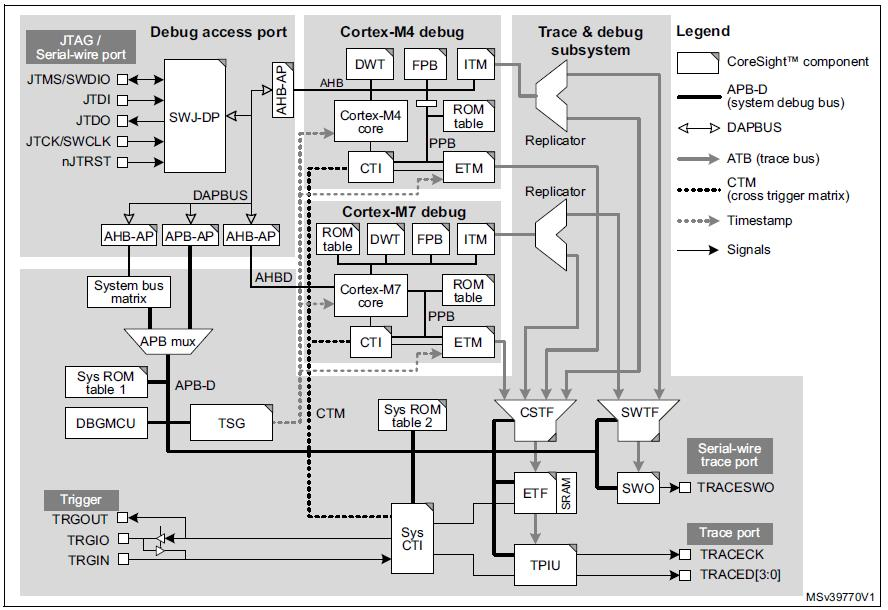
(出典:IAR Systems、図はM0399リファレンスマニュアルのSTMicroelectronics提供)
CTIを使用すると、さまざまなソースからのイベントでデバッグおよびトレースアクティビティをトリガーできます。たとえば、プロセッサコアの1つでブレークポイントに到達すると、他のプロセッサが停止したり、外部トリガー入力で検出された遷移を設定してコードトレースを開始したりできます。
シングルチップ上にCortex-M7コアとCortex-M4コアを搭載した異種マルチコアプロセッサを使用したこの例では、2つの別々のプログラムが使用されています。1つはCortex-M4で実行され、もう1つはCortex-M7で実行されます。各プロジェクトはFreeRTOSを使用して、プロセッサで実行されているソフトウェアを管理します。 2つのコアは、共有メモリインターフェイスを介して通信します。ただし、アプリケーションは両方ともFreeRTOSメッセージパッシングメカニズムを使用して他のプロセッサと通信し、基盤となるメカニズムの複雑さを隠します。したがって、あるCPUの観点からは、別のタスクでメッセージを送受信しているだけです。他のタスクがたまたま別のCPUコアで実行されていることは透過的です。
以下の画像は、IDEのWorkspaceExplorer未亡人です。 2つのプロジェクトの概要がここに表示されるので、Cortex-M7プロジェクトとCortex-M4プロジェクトの両方の内容を確認できます。
ウィンドウの下部にある他のタブの1つを選択することで、フォーカスをM4プロジェクトまたはM7プロジェクトのいずれかに切り替えることができます。
Cortex-M7プロジェクトには、Cortex-M4で実行されているタスクにメッセージを送信するタスクがあります。 Cortex-M4には、実行中の受信タスクの2つのインスタンスがあります。 Cortex-M7には、定期的に実行される「チェック」タスクがあり、正常に実行されているかどうかを確認します。
最後に、デバッガーは両方のプロジェクトをロードします。これは、2番目のデバッガー用のEmbeddedWorkbenchの追加インスタンスが開始されることを意味します。
非対称マルチプロセッシングをサポートするデバッガーをセットアップするには、一方のプロジェクトを「マスター」として指定し、もう一方のプロジェクトを「ノード」プロジェクトとして指定する必要があります。実際、選択は任意であり、起動時に他のプロジェクトを起動する機能があるプロジェクトを決定するだけです。
「ノード」プロジェクトには特別な設定はなく、別のプロジェクトの「ノード」として実行されていることを認識していません。
このように、「マスター」プロジェクトでデバッガーが開始されると、IDEの別のインスタンスが自動的に起動され、2番目のプロジェクトが実行される2番目のデバッガーセッションに対応します。
概要
マルチコアは、ムーアの法則がなくなったときにパフォーマンスを向上させることができます。ただし、マルチコアにはデバッグの課題があり、アプリケーションがマルチコアアーキテクチャを最大限に活用できるように、特定の開発アプローチが必要です。
デバッグ設定が構成されると、マルチコアデバッグがこれまでになく簡単になります。以前にモノコアをデバッグするためのツールを使用したことがある場合は、これに含まれるすべてのものを認識し、マルチコアデバッグが彼らにとってどれほど難しいかについて他の人が話していることをおそらく理解できないでしょう。
最新のハードウェアおよびソフトウェアツールは、マルチコアデバッグの課題を克服するのに役立ちます。
注:図の画像は、特に明記されていない限り、IARシステムズによるものです。
>
 アーロンバウフ は、IAR Systemsのシニアフィールドアプリケーションエンジニアであり、米国東部とカナダの顧客と協力しています。 Aaronは、Intel、Analog Devices、Digital EquipmentCorporationなどの企業向けの組み込みシステムおよびソフトウェアと協力してきました。彼の設計は、医療機器、ナビゲーション、銀行システムなど、幅広いアプリケーションをカバーしています。アーロンはまた、ニューハンプシャー州南部大学の教授として、組み込みシステム設計を含む多くの大学レベルのコースを教えてきました。 Bauch氏は、ニューヨーク州ニューヨークで、クーパーユニオンで電気工学の学士号を取得し、コロンビア大学で電気工学の修士号を取得しています。
アーロンバウフ は、IAR Systemsのシニアフィールドアプリケーションエンジニアであり、米国東部とカナダの顧客と協力しています。 Aaronは、Intel、Analog Devices、Digital EquipmentCorporationなどの企業向けの組み込みシステムおよびソフトウェアと協力してきました。彼の設計は、医療機器、ナビゲーション、銀行システムなど、幅広いアプリケーションをカバーしています。アーロンはまた、ニューハンプシャー州南部大学の教授として、組み込みシステム設計を含む多くの大学レベルのコースを教えてきました。 Bauch氏は、ニューヨーク州ニューヨークで、クーパーユニオンで電気工学の学士号を取得し、コロンビア大学で電気工学の修士号を取得しています。 >
関連コンテンツ:
- 重要なマルチコアベースの組み込みシステムでのソフトウェアタイミング動作の保証
- マルチコアシステム、ハイパーバイザー、マルチコアフレームワーク
- 高性能組み込みコンピューティング–並列処理とコンパイラの最適化
- ソフトウェアは機能すると思いますか?証明してください!
- 現場に配備されたデバイスでのソフトウェアトレース
- 機能安全の異星人の世界のコンパイラ
Embeddedの詳細については、Embeddedの週刊メールニュースレターを購読してください。
埋め込み