


IoTデータのETLの課題に対応し、ROIを最大化する
組織は、ETL(抽出、転送、読み込み)テクノロジーの専門知識を開発することで、IoTデータを最適化し、ビジネス価値を迅速かつコスト効率よく引き出すことができます。
IoTの可能性はかつてないほど大きくなっています。2021年までにIoT対応デバイスへの投資が倍増すると予想され、データと分析のセグメントで機会が急増しているため、主なタスクは課題を克服し、周囲のコストを抑えることです。 IoTデータプロジェクト。
組織は、ストリーム処理やデータレイクなどのETL(抽出、転送、読み込み)テクノロジーの専門知識を開発することで、IoTデータを最適化し、ビジネス価値を迅速かつコスト効率よく引き出すことができます。
関連項目: 元のデータレイクを実現するための4つの原則
ただし、多くの組織では、これによりITのボトルネック、プロジェクトの長期遅延、データサイエンスの延期が発生する可能性があります。結果:予測分析データが運用効率の向上とイノベーションの促進に重要な役割を果たすことを目的としたIoTプロジェクト コンセプトの証明のしきい値を超えておらず、ROIを確実に実証することはできません。
IoTが直面するETLの課題を理解する
次の図は、問題をよりよく理解するのに役立ちます。
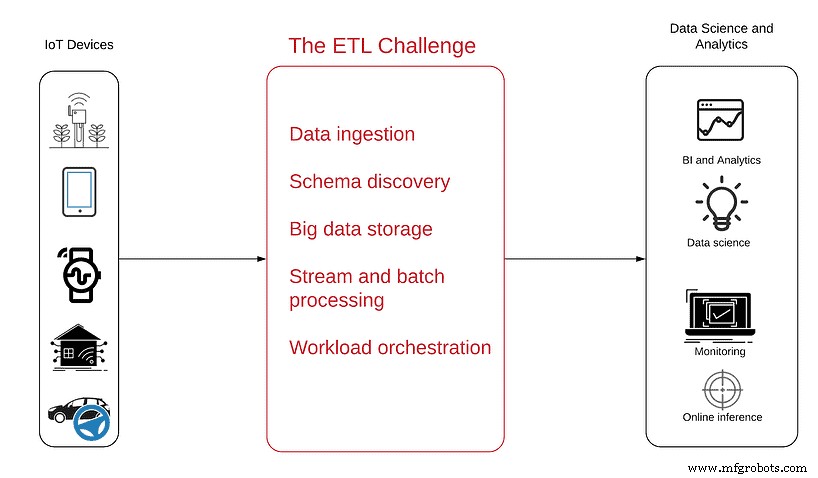
データソースは左側にあります。単純なアンテナから、IoTデータを生成し、それらを中断のない半構造化データのストリームとしてWeb経由で送信する複雑な自律型車両まで、センサーで満たされた無数のデバイスです。
右側は、上記のデータの消費が達成する必要のある目標であり、プロジェクトの結論として得られる分析製品には、次のものが含まれます。
- ビジネスインテリジェンス 製品の使用傾向とパターンを可視化するため
- 運用監視 停止や非アクティブなデバイスをリアルタイムで確認するには
- 異常検出 データのピークまたは急激な低下について予防的なアラートを取得するため
- 埋め込まれた分析 顧客が自分の使用状況データを見て理解できるようにするため
- データサイエンス 予知保全、ルート最適化、またはAI開発における高度な分析と機械学習のメリットを享受する
これらの目標を達成するには、最初にデータを生のストリーミングモードから、SQLやその他の分析ツールでクエリできる分析対応のテーブルに変換する必要があります。
IoTデータには、通常のリレーショナルデータベース、ETL、およびBIツールと常に同期しているとは限らない独自の品質セットが含まれているため、ETLプロセスは分析プロジェクトの中で最も理解しにくいセグメントであることがよくあります。例:
- IoTデータはストリーミングデータです 小さなファイルで継続的に生成され、蓄積されて大規模で広大なデータセットになります。これらは従来の表形式のデータとは大きく異なり、結合、集計、データの強化を実行するには、より複雑なETLが必要です。
- IoTデータは今すぐ保存し、後で分析する必要があります。 通常のデータセットとは異なり、IoTデバイスによって作成される膨大な量のデータは、分析する前に座る場所、つまりクラウドまたはオンプレミスのデータレイクが必要であることを意味します。
- IoTデータは複数のデバイスが原因で順序付けられていないイベントを示します インターネット接続領域に出入りする可能性があります。これは、ログがさまざまな時点で、常に「正しい」順序でサーバーに到達する可能性があることを意味します。
- IoTデータには、多くの場合、低レイテンシアクセスが必要です。 運用上、異常または特定のデバイスをリアルタイムまたはほぼリアルタイムで特定する必要がある場合があるため、バッチ処理によって発生する遅延を許容することはできません。
オープンソースフレームワークを使用してデータレイクを作成する必要がありますか?
データ分析用のエンタープライズデータプラットフォームを構築するために、多くの組織はこの一般的なアプローチを使用しています。オープンソースストリーム処理フレームワークをビルディングブロックとして使用し、Apache Spark / Hadoop、Apache Flink、InfluxDBなどの時系列データベースを使用してデータレイクを作成します。
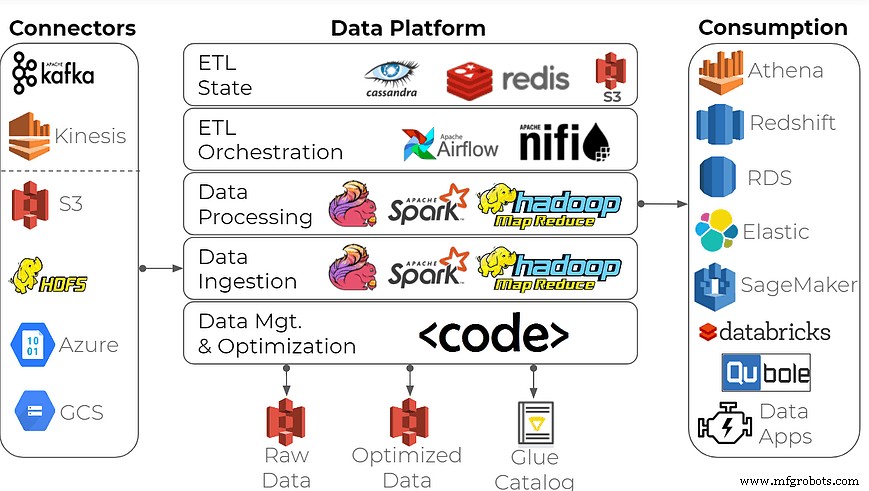
このツールセットはその仕事をすることができますか?確かに、しかしそれを正しく行うことは、ほとんどのデータ経験のある企業を除いてすべてにとって圧倒される可能性があります。このようなデータプラットフォームを構築するには、ビッグデータエンジニアの専門的なスキルと、データインフラストラクチャへの強い注意が必要です。通常、製造業や家電製品、IoTデータと緊密に連携する業界には適していません。納期の遅れ、高額な費用、大量のエンジニアリング時間の浪費が予想されます。
組織で高性能に加えて、運用レポート、アドホック分析、機械学習用のデータ準備などのあらゆる機能とユースケースが必要な場合は、適切なソリューションを採用してください。例としては、ストリームを分析対応のデータセットに変換するために専用に構築されたデータレイクETLプラットフォームを使用する場合があります。
このソリューションは、Spark/Hadoopデータプラットフォームほど厳格で複雑ではありません。これは、Java / Scalaでの集中的なコーディングではなく、セルフサービスのユーザーインターフェイスとSQLで構築されています。 DevOpsおよびデータエンジニアリングのアナリスト、データサイエンティスト、プロダクトマネージャー、データプロバイダーにとって、次のような真にユーザーフレンドリーなツールになる可能性があります。
- ITやデータエンジニアリングに依存することなく、データ利用者にセルフサービスを提供します
- ETLフローとビッグデータストレージを最適化して、インフラストラクチャのコストを削減します
- フルマネージドサービスのおかげで、組織はインフラストラクチャではなく機能に集中できます
- リアルタイムデータ、アドホック分析、レポート作成のために複数のシステムを維持する必要がなくなります
- 完全なセキュリティのために、データがお客様のAWSアカウントを離れないようにします
IoTデータの恩恵を受けることができます-それはそれを有用にするために適切なツールを必要とします。
モノのインターネットテクノロジー