


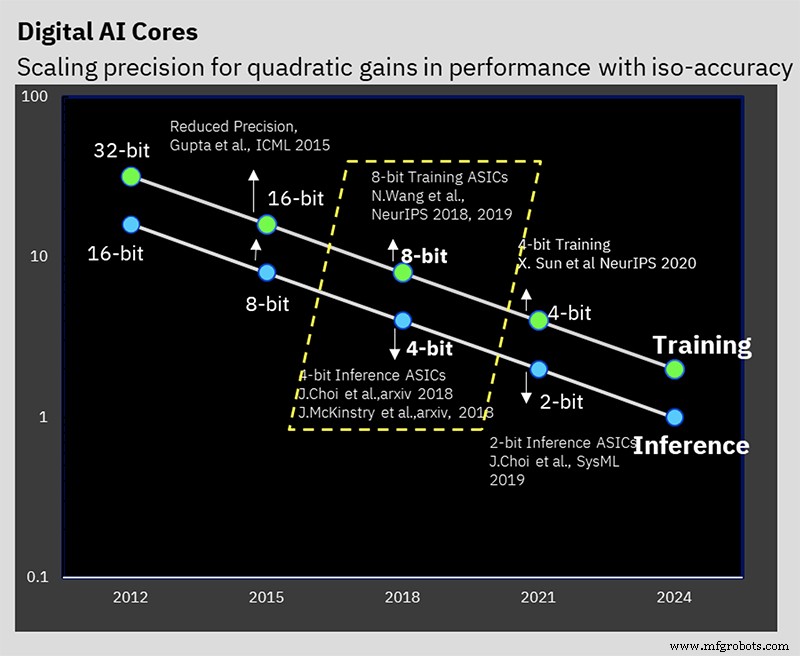
研究者は、精度の低いトレーニングでAIチップを示しています
ISSCCで、IBM Researchは、低精度のAIトレーニングと推論アルゴリズムに関する長年の作業のハードウェアの兆候を表すテストチップを発表しました。 7nmチップは、16ビットと8ビットのトレーニング、および4ビットと2ビットの推論をサポートします(32ビットまたは16ビットのトレーニングと8ビットの推論は今日の業界標準です)。
精度を下げると、AI計算に必要な計算量と電力を削減できますが、IBMには、効率を高めるためのアーキテクチャ上のトリックがいくつかあります。課題は、計算結果に悪影響を与えることなく精度を下げることです。これは、IBMがアルゴリズムレベルで何年にもわたって取り組んできたものです。
IBMのAIハードウェアセンターは2019年に設立され、AIコンピューティングのパフォーマンスを年間2.5倍に向上させるという同社の目標をサポートし、2029年までにパフォーマンス効率(FLOPS / W)を1000倍に向上させるという野心的な全体目標を掲げています。 AIモデルのサイズ、およびそれらをトレーニングするために必要なコンピューティングの量は、急速に増加しています。特に自然言語処理(NLP)モデルは現在、数兆パラメータの巨大なものであり、これらの獣のトレーニングに伴う二酸化炭素排出量は見過ごされていません。
IBM Researchのこの最新のテストチップは、IBMがこれまでに達成した進歩を示しています。 8ビットトレーニングの場合、4コアチップは25.6 TFLOPSに対応し、4ビット整数計算の推論パフォーマンスは102.4 TOPSです(これらの数値は、クロック周波数1.6GHz、電源電圧0.75Vの場合)。クロック周波数を1GHzに下げ、供給電圧を0.55Vに下げると、電力効率が3.5 TFLOPS / W(FP8)または16.5 TOPS / W(INT4)に向上します。
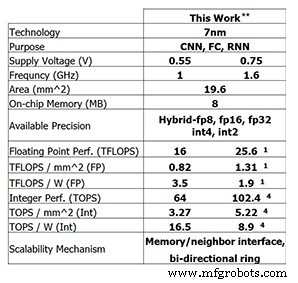
IBM Researchのテストチップのパフォーマンス(画像:IBM Research)** 0%のスパース性でパフォーマンスが報告されました。 (1)FP8。 (4)INT4。
低精度トレーニング
このパフォーマンスは、低精度のトレーニングと推論手法に関する長年のアルゴリズム作業に基づいています。このチップは、NeurIPS 2019で最初に発表されたIBMの特別な8ビットハイブリッド浮動小数点形式(ハイブリッドFP8)をサポートする最初のものです。この新しい形式は、特に8ビットトレーニングを可能にするために開発され、16ビットに必要な計算を半分にします。結果に悪影響を与えることなくトレーニングします(AI処理の数値形式について詳しくはこちらをご覧ください)。
IBM Researchは、精度を下げながら精度を維持するという問題の解決に取り組んできました(画像:IBM)
「長年にわたるさまざまな研究で学んだことは、低精度のトレーニングは非常に難しいことですが、適切な数値形式があれば8ビットのトレーニングを行うことができます」とIBMフェローでアクセラレーターアーキテクチャーのシニアマネージャーであるKailashGopalakrishnanは述べています。 IBMResearchの機械学習は EE Times 。 「適切な数値形式を理解し、ディープラーニングで適切なテンソルに配置することは、その重要な部分でした。」
ハイブリッドFP8は、実際には2つの異なるフォーマットの組み合わせです。 1つの形式は、深層学習のフォワードパスでの重みとアクティブ化に使用され、もう1つの形式はバックワードパスで使用されます。推論はフォワードパスのみを使用しますが、トレーニングにはフォワードフェーズとバックワードフェーズの両方が必要です。
「私たちが学んだことは、ディープラーニングのフォワードパスでの重みとアクティベーションの表現に関して、より忠実でより正確なものが必要であるということです」とGopalakrishnan氏は述べています。 「[逆相]の反対側では、勾配のダイナミックレンジが高く、[より大きな]指数が必要であると認識しています。これは、深層学習のテンソルが必要とする方法の間のトレードオフです。他のテンソルはより広いダイナミックレンジを必要としますが、より正確で忠実な表現が必要です。これは、2019年後半に発表したハイブリッドFP8形式の起源であり、現在はハードウェアに変換されています。」
IBMの研究では、8ビットを指数と仮数の間で分割する最良の方法は、順方向フェーズで1-4-3(1符号ビット、4ビット指数、および3ビット仮数)であり、代替の5であると判断しました。 2 32 の動的範囲を提供する逆方向フェーズのビット指数バージョン 。ハイブリッドFP8対応ハードウェアは、これら両方の形式をサポートするように設計されています。
階層的蓄積
研究者が「階層的蓄積」と呼ぶ革新により、重みと活性化とともに蓄積の精度を下げることができます。一般的なFP16トレーニングスキームは、精度を維持するために32ビット演算に蓄積されますが、IBMの8ビットトレーニングはFP16に蓄積できます。 FP32に蓄積し続けると、そもそもFP8に移行することで得られるメリットが制限されていたでしょう。
「浮動小数点演算で何が起こるかというと、たとえば、10,000の長さのベクトルであり、すべてを足し合わせているとすると、浮動小数点表現自体の精度があなたの精度を制限し始めます。合計」とGopalakrishnanは説明しました。 「それを行うための最良の方法は、順次加算を行うことではないと結論付けましたが、長い蓄積をグループに分割する傾向があります。これをチャンクと呼びます。次に、チャンクを相互に追加します。これにより、この種のエラーが発生する可能性が最小限に抑えられます。」
低精度の推論
現在、ほとんどのAI推論では、8ビット整数形式(INT8)が使用されています。 IBMの研究によると、4ビット整数は、予測の精度を大幅に低下させることなく、精度を低くすることができるという点で最先端です。量子化(モデルをより低い精度の数値に変換するプロセス)に続いて、量子化を意識したトレーニングが実行されます。これは事実上、量子化に起因するエラーを軽減する再トレーニングスキームです。この再トレーニングにより、精度の低下を最小限に抑えることができます。 IBMは、精度をわずか0.5%低下させるだけで、4ビット整数演算に「簡単に」量子化できます。Gopalakrishnanによると、ほとんどのアプリケーションで「非常に許容できる」とのことです。
オンチップリング
低精度の演算に重点を置いているほかに、チップの効率に貢献する他のハードウェアの革新があります。
1つは、オンチップリング通信です。これは、ディープラーニング用に最適化されたネットワークオンチップであり、各コアが他のコアにデータをマルチキャストできるようにします。コアは重みを共有し、結果を他のコアに伝達する必要があるため、マルチキャスト通信はディープラーニングにとって重要です。また、オフチップメモリからロードされたデータを複数のコアにブロードキャストすることもできます。これにより、メモリを読み取る必要がある回数と全体的に送信されるデータの量が減り、必要なメモリ帯域幅が最小限に抑えられます。
IBMResearchの機械学習およびアクセラレーターアーキテクチャーの研究スタッフメンバーであるAnkurAgrawalは、次のように述べています。 「リングの動作周波数をコアの動作周波数から切り離しました。これにより、コアに関してリングの性能を独立して最適化することができます。」
電力管理
IBMの革新のもう1つは、効率を最大化するために周波数スケーリング方式を導入することでした。
「ディープラーニングのワークロードは少し特別です。コンパイルフェーズでも、この非常に大きなワークロードで遭遇する計算のフェーズがわかっているからです」とAgrawal氏は述べています。 「事前設定を行って、計算のさまざまな部分で電力プロファイルがどのようになるかを把握できます。」
ディープラーニングのパワープロファイルには、通常、大きなピーク(畳み込みなどの計算量の多い操作の場合)と谷(おそらく活性化関数の場合)があります。
IBMのスキームは、チップの初期動作電圧と周波数を非常に積極的に設定しているため、最低電力モードでも、チップはほぼ電力エンベロープの限界にあります。その後、より多くの電力が必要になると、動作周波数が低下します。
「最終的な結果は、さまざまなフェーズを経ても、計算全体を通してほぼピーク電力で動作するチップです」とAgrawal氏は説明しました。 「全体として、これらの低消費電力フェーズがないため、すべてをより高速に実行できます。消費電力の低下をパフォーマンスの向上に変換したのは、運用のすべてのフェーズで消費電力をほぼピーク時の消費電力に保つことです。」
オンザフライで行うのは難しいため、電圧スケーリングは使用されません。新しい電圧で安定するのにかかる時間は、深層学習の計算には長すぎます。したがって、IBMは通常、そのプロセスノードの可能な限り低い供給電圧でチップを実行することを選択します。
テストチップ
IBMのテストチップには4つのコアがあり、一部はすべての異なる機能のテストを可能にします。 Gopalakrishnanは、コアサイズが最適になるように意図的に選択された方法について説明しました。何千もの小さなコアのアーキテクチャは、相互に接続するのが複雑ですが、大きなコア間で問題を分割することも難しい場合があります。この中間コアは、IBMとAIハードウェアセンターのパートナーのニーズを満たすように設計されており、サイズの点でスイートスポットを見つけています。
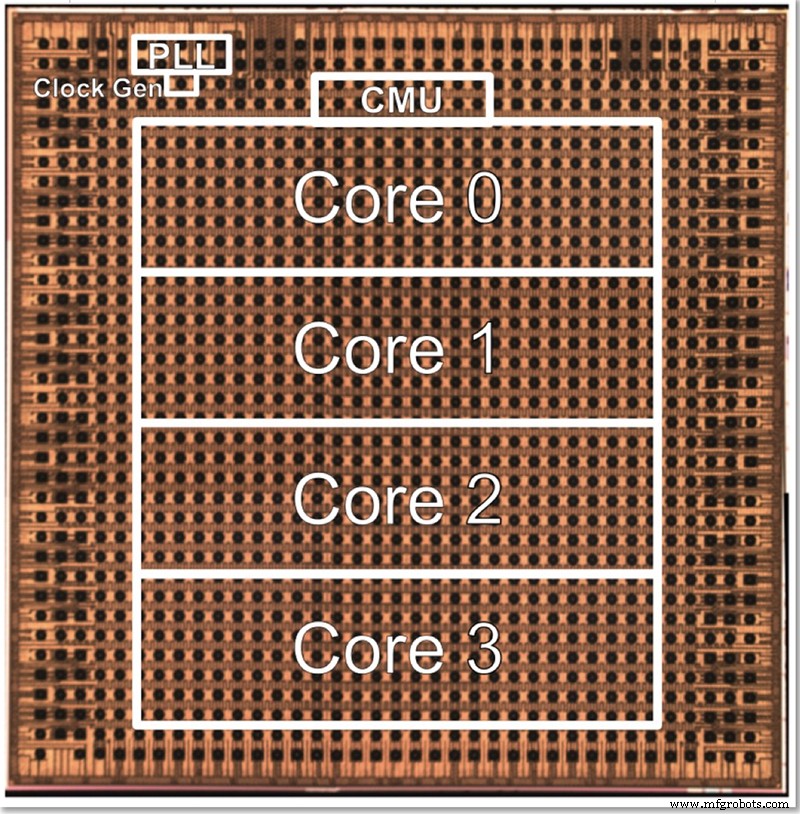
IBMの4コア低精度テストチップのダイ写真(画像:IBM)
コアの数を変更することで、アーキテクチャをスケールアップまたはスケールダウンできます。最終的に、Gopalakrishnanは、1〜2コアのチップがエッジデバイスに適していると考えていますが、32〜64コアのチップはデータセンターで機能する可能性があります。複数のフォーマット(FP16、ハイブリッドFP8、INT4、INT2)をサポートしているという事実も、ほとんどのアプリケーションに十分な汎用性を備えていると彼は述べています。
「[アプリケーション]ドメインが異なれば、エネルギー効率や精度などの要件も異なります」と彼は言います。 「それぞれが個別に最適化された精度のスイスアーミーナイフにより、そのプロセスでエネルギー効率を必ずしもあきらめることなく、さまざまなドメインでこれらのコアをターゲットにすることができます。」
IBM Researchは、ハードウェアに加えて、コンパイラーがチップの高い使用率(60〜90%)を可能にするツールスタック(「ディープツール」)も開発しました。
EE Times のIBMResearchとの以前のインタビューでは、このアーキテクチャに基づく低精度のAIトレーニングと推論チップが約2年で市場に出るはずであることが明らかになりました。
>>この記事はもともと姉妹サイトのEETimes。
>
関連コンテンツ:
- AIチップはモデル縮小で精度を維持します
- エッジでAIモデルをトレーニングする
- エッジでAIの競争が始まっています
- エッジAIはメモリテクノロジーに挑戦します
- エンジニアリンググループは、1mWのAIを限界まで押し上げようとしています
- 小規模タスク用のニューラルネットワークアプリケーション
- AI ICの調査では、代替アーキテクチャを調査しています
Embeddedの詳細については、Embeddedの週刊メールニュースレターを購読してください。
埋め込み
- Bluetoothメッシュを使用した設計:チップまたはモジュール?
- 研究者は小さな認証IDタグを作成します
- 削減されたメンテナンススタッフへの対応
- ミネソタ大学とのロックウェル提携により、自動化トレーニングへのアクセスが拡大
- 研究者は、BluetoothClassicのセキュリティ上の欠陥を悪用する方法を示しています
- IBMWatsonがAIを使用して他のすべてのビジネスをどのように強化しているか
- エージェンシープレシジョンで実行するマーケティング活動を向上させる
- エージェンシープレシジョンで実行するマーケティング活動を向上させる
- IBM:EAMによる信頼性と安全性の積極的な確保
- 精密機械加工による優れた油圧システムの構築
- CNC工作機械で製造された10個の精密部品