


ディープラーニングにFPGAを活用
最近、シリコンバレーで開催された2018ザイリンクス開発フォーラム(XDF)に参加しました。このフォーラムで、フィールドプログラマブルゲートアレイ(FPGA)に関連するAI関連の問題を解決したと主張する人工知能(AI)の分野の新興企業であるMipsologyという会社を紹介されました。 Mipsologyは、FPGAの展開に固有の制約なしに、FPGAで達成可能な最高のパフォーマンスでニューラルネットワーク(NN)の計算を高速化するという壮大なビジョンを持って設立されました。
Mipsologyは、毎秒20,000を超えるイメージを実行し、ザイリンクスから新しく発表されたAlveoボードで実行し、ResNet50、InceptionV3、VGG19などのNNのコレクションを処理する能力を実証しました。
ニューラルネットワークとディープラーニングの紹介
人間の脳のニューロンのウェブ上で大まかにモデル化されたニューラルネットワークは、それ自体でタスクを学習できる複雑な数学システムであるディープラーニング(DL)の基盤です。多くの例や関連を見ると、NNは学ぶことができます。 従来の認識プログラムよりも高速な接続と関係。 学習に基づいて特定のタスクを実行するようにNNを構成するプロセス 同じタイプの何百万ものサンプルはトレーニングと呼ばれます 。
たとえば、NNは多くの音声サンプルを聞き、DLを使用して特定の単語の音を「認識する」ことを学習する場合があります。次に、このNNは、新しい音声サンプルのリストをふるいにかけ、推論と呼ばれる手法を使用して、学習した単語を含むサンプルを正しく識別できます。 。
その複雑さにもかかわらず、DLは、数十億または数兆の単純な演算(主に加算と乗算)の実行に基づいています。このような操作を実行するための計算上の要求は気が遠くなるようなものです。より具体的には、DL推論を実行するためのコンピューティングのニーズは、DLトレーニングの場合よりも大きくなります。 DLトレーニングは1回だけ実行する必要がありますが、NNは、トレーニングされると、受け取った新しいサンプルごとに何度も推論を実行する必要があります。
深層学習の推論を加速するための4つの選択肢
時間の経過とともに、エンジニアリングコミュニティは、NNを処理するために4つの異なるコンピューティングデバイスに頼りました。処理能力と消費電力の昇順、および柔軟性/適応性の降順で、これらのデバイスには、中央処理装置(CPU)、グラフィックス処理装置(GPU)、FPGA、および特定用途向け集積回路(ASIC)が含まれます。次の表は、4つのコンピューティングデバイスの主な違いをまとめたものです。
<中央> 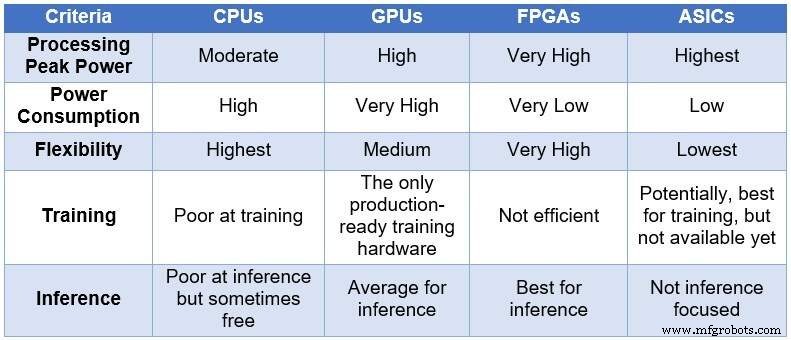
DLコンピューティング用のCPU、GPU、FPGA、およびASICの比較(出典:Lauro Rizzatti)
CPUはフォンノイマンアーキテクチャに基づいています。 CPUは柔軟性がありますが(存在する理由)、メモリアクセスが単純なタスクを実行するために数クロックサイクルを消費するため、長いレイテンシの影響を受けます。 NN計算、特にDLトレーニングや推論など、待ち時間が最も短いタスクに適用する場合、これらは最も不適切な選択です。
GPUは、柔軟性を低下させますが、高い計算スループットを提供します。さらに、GPUは冷却を必要とする大量の電力を消費するため、データセンターでの導入には理想的とは言えません。
カスタムASICは理想的なソリューションのように見えるかもしれませんが、独自の問題があります。 ASICの開発には何年もかかります。 DLとNNは、継続的なブレークスルーによって急速に進化しており、昨年のテクノロジーは無関係になっています。さらに、CPUまたはGPUと競合するには、ASICは最も薄いプロセスノードテクノロジを使用して大きなシリコン領域を使用する必要があります。これにより、長期的な関連性が保証されることなく、先行投資が高額になります。考えてみれば、ASICは特定のタスクに効果的です。
FPGAデバイスは、推論のための最良の選択肢として浮上しています。これらは高速で柔軟性があり、電力効率が高く、データセンター、特に急速に変化するDLの世界、ネットワークのエッジ、AI科学者のデスクの下でのデータ処理に適したソリューションを提供します。
現在利用可能な最大のFPGAには、数百万の単純なブール演算子、数千のメモリとDSP、およびいくつかのCPUARMコアが含まれています。これらのリソースはすべて並行して機能し、クロックティックごとに最大数百万の同時操作がトリガーされ、毎秒数兆の操作が実行されます。 DLに必要な処理は、FPGAリソースに非常によく対応しています。
FPGAには、DLに使用されるCPUやGPUに比べて、次のような他の利点があります。
-
特定の種類のデータに限定されません。 DLのスループットを向上させるのに適した、非標準の低精度を処理できます。
-
CPUやGPUよりも消費電力が少なく、通常、同じNN計算の平均電力は5〜10分の1です。データセンターでの定期的なコストは低くなります。
-
任意のタスクに合うように再プログラムできますが、さまざまな作業に対応するのに十分な汎用性があります。 DLは急速に進化しており、同じFPGAが次世代シリコン(ASICで一般的)を必要とせずに新しい要件に適合し、それによって所有コストを削減します。
-
大規模なデバイスから小規模なデバイスまでさまざまです。これらは、データセンターまたはモノのインターネット(IoT)ノードで使用できます。唯一の違いは、含まれるブロックの数です。
輝くものすべてが金ではない
FPGAの高い計算能力、低消費電力、および柔軟性には代償が伴います。プログラミングが困難です。
モノのインターネットテクノロジー
- ETSIレポートは、AIセキュリティを標準化するための道を開きます
- CEVA:ディープニューラルネットワークワークロード用の第2世代AIプロセッサ
- AIコンピューティングのためのニューロモルフィックチップの主張
- ICP:深層学習推論用のFPGAベースのアクセラレータカード
- 医療業界におけるAIの外部委託とディープラーニング–データのプライバシーは危険にさらされていますか?
- ハイテク産業がAIを活用してビジネスを飛躍的に成長させる方法
- 人工知能vs機械学習vsディープラーニング|違い
- エンタープライズモバイル機械学習のためのApple&IBMWatsonチーム
- ディープラーニングとその多くのアプリケーション
- 深穴加工用の工具安定性ソリューション
- ライフ サイエンス業界でディープ ラーニングが検査を自動化する方法