


早期失明を検出して予防するためのアルゴリズムをトレーニングする方法
インターネットに接続しなくても、糖尿病性網膜症のさまざまな段階を正確に検出できる携帯型医療機器は、世界中の網膜症による失明の症例数を大幅に減らすことができます。組み込みの機械学習により、電池式の医療機器で直接実行し、検出または診断を実行できるアルゴリズムの開発が可能になりました。この記事では、EdgeImpulseのソフトウェアプラットフォームを使用してこの機能を提供するアルゴリズムをすばやくトレーニングするために必要な手順のウォークスルーを提供します。
糖尿病性網膜症は、目の後ろにある組織の血管に損傷が生じる状態です。これは、糖尿病で血糖値の管理が不十分な人に発生する可能性があります。極端な慢性の場合、糖尿病性網膜症は失明につながる可能性があります。
糖尿病を患うアメリカ人の5人に2人以上が、何らかの形の糖尿病性網膜症を患っています。そのため、早期に発見することが重要になり、その時点でライフスタイルや医学的介入を行うことができます。視力ケアへのアクセスが制限されている世界中の農村地域では、網膜症の病期は、症例が重症になる前に早期に発見するのがさらに困難です。糖尿病性網膜症の検出を目標として使用して、公開されている医療データを取得し、エッジデバイスで直接推論を実行できるEdgeImpulseで機械学習モデルをトレーニングすることを検討しました。アルゴリズムは、理想的には、網膜カメラによって撮影された目の画像間の糖尿病性網膜症の重症度を評価することができるでしょう。このプロジェクトで使用したデータセットはここにあります。
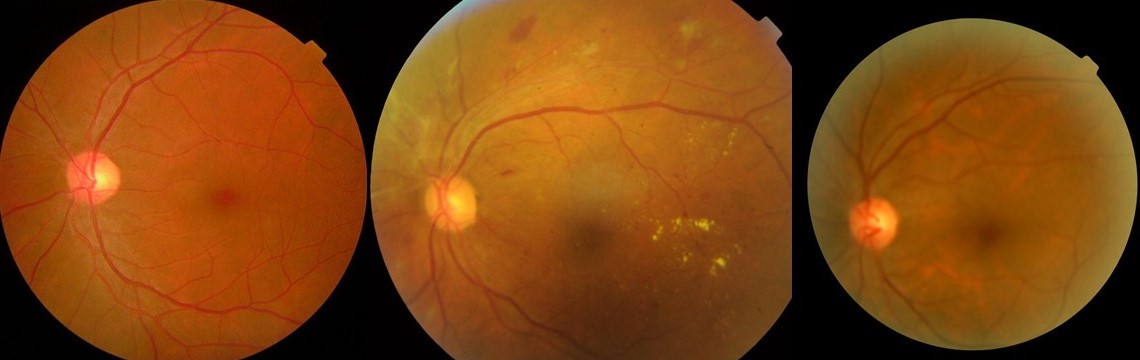
このアルゴリズムでは、クラスを5つの異なるデータセットに分割しました。
- 糖尿病性網膜症なし(DRなし)
- マイルドDR
- 中程度のDR
- 重大なDR
- 増殖性DR
多くの公開されているデータセットと同様に、データのクレンジングとラベル付けを行う必要がありました。
患者のIDを保護するために、データセット内の各画像には、id_codeと0〜5の診断が与えられました。0はDRなしの最低の重大度、5は最悪または増殖性DRです。
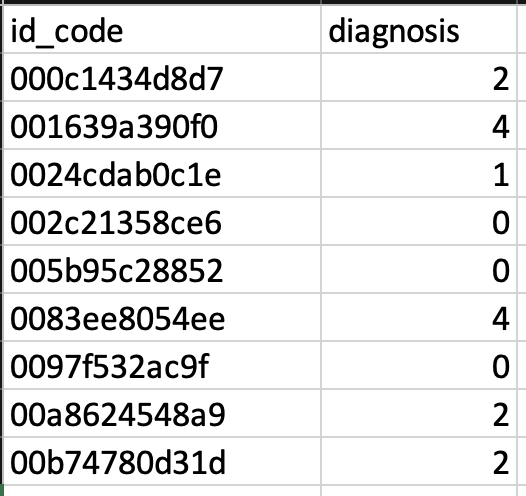
データをEdgeImpulseに取り込むには、画像の分割を行う必要がありました。データがどのように分割されるかという単純な性質を考慮して、Excelから画像id_codeを読み取り、関連する画像を取得して、それぞれのフォルダーに配置するVBAスクリプトを作成することにしました。これらのファイルを移動するスクリプトはここにリンクされています。 Pythonやその他のスクリプト言語のスキルが優れている場合は、これを行う方法がたくさんありますが、それはさらに簡単かもしれません。
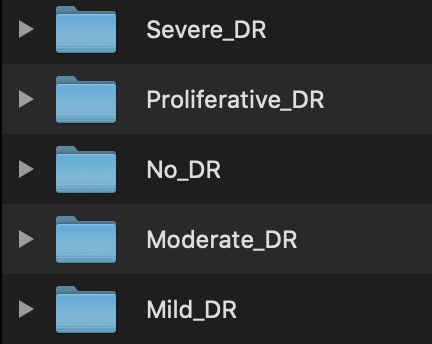
Edge Impulseには、クラウドデータバケットの統合やデバイスからのデータ収集など、他のデータ取り込み機能がありますが、ここで使用した方法はデータのアップロードでした。データアップロードオプションを使用して、5つの異なるクラスに一連の5つのアップロードを取り込むことができました。各アップロードは、データを5つのクラスの1つとしてラベル付けし、各フォルダーに含まれる関連画像をアップロードすることで構成されていました。
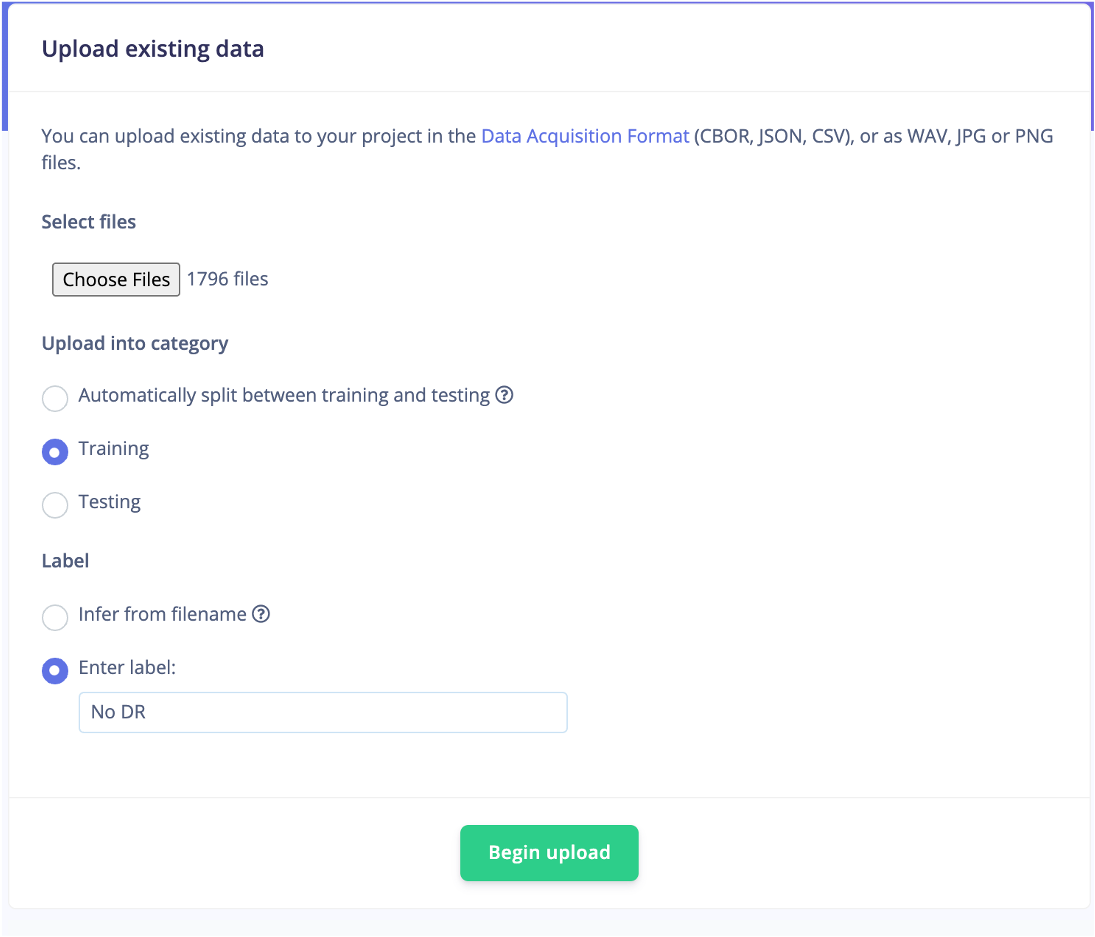
Edge Impulseには、データを80/20分割でトレーニングデータまたはテストデータに自動的に分割するオプションがあります。ただし、さまざまなクラスの約500枚の画像を手動でテストデータセットに追加しました。
次に、モデルを設定し、このモデルの信号処理ブロックとニューラルネットワークブロックを選択します。このモデルでは、5つの異なるクラスを区別することを目的として、画像ブロックを転移学習ブロックにフィードしました。
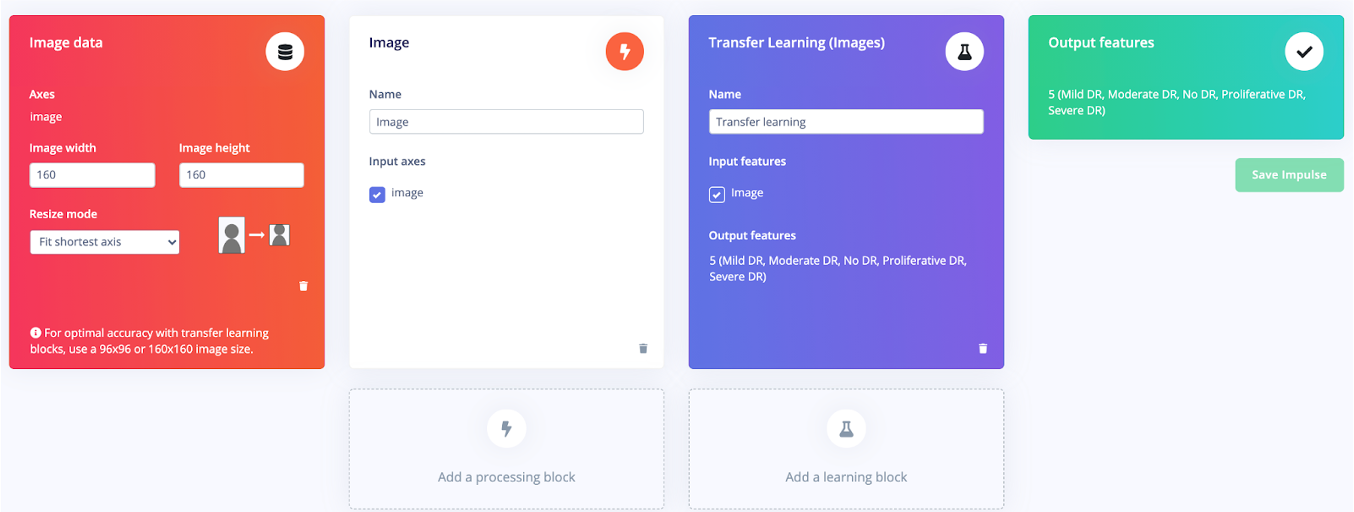
ここから、ニューラルネットワークのトレーニングに行きました。ニューラルネットワークの設定をいじってみると、私が得た最高の精度は約74%でした。悪くはありませんが、いくつかのエッジケースに関しては、モデルがスタックしていました。たとえば、重度のDRは軽度のDRとして分類されることがありました。下のスクリーンショットでわかるように、DRが進行するにつれて、モデルはそれほど正確ではありませんでした。
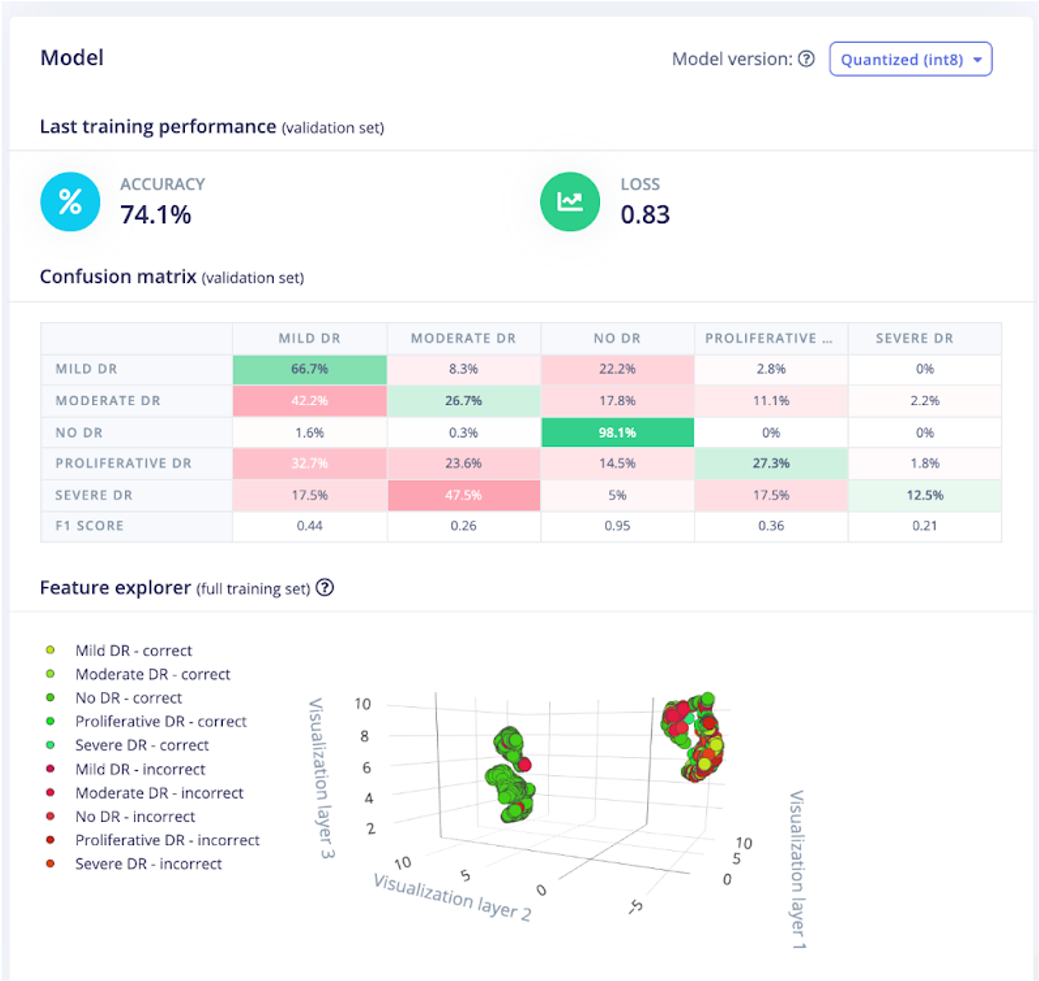
これにより、このようなプロジェクトの実際のアプリケーションについて、そしてこのレベルの精度が許容できるかどうかについて考えさせられました。理想的には、ある種のポータブル網膜イメージングカメラ(低ワイヤレス接続環境)は、デバイス自体でこのようなアルゴリズムを実行できます。写真が撮影され、処理され、結果が出力されると、その時点で、視力検査を実施する人は、結果に応じて、さらなる医療支援または介入を求める必要があることを患者に伝えることができます。
このアプリケーションでは、患者が何らかの予防的治療を開始できるように、またはより重症の場合は直ちに医療支援を求めることができるように、すべての段階でDRをキャッチすることがより重要です。このユースケースを考えると、モデルは実際にその潜在的なアプリケーションに比較的よく役立ちます。
頭から離れて、モデルに加えることができるいくつかの変更または改善があります。これにより、DRの重大度の診断に関して、結果の出力がより正確になる可能性があります。
- データが多いほど常に優れています。ただし、この限られたデータセットを考えると、さらにデータを収集する必要があります。
- 1つのアイデアは、軽度から中程度のクラスと増殖性から重度のクラスを作成することにより、クラスを組み合わせることです。軽度と中等度のDRの特定のケース間の類似性を考えると、アルゴリズムがより適切に分類されるのに役立つのではないかと思います。これらはすべて同じグループに分類されます。
ニューラルネットワーク(NN)内のレイヤー数とドロップアウトを試してみてください。

展開の観点から、このトレーニング済みモデルはメモリの面でより大きなフットプリントを持ち、推定306kBのフラッシュと236kBのRAMを使用していました。推論を実行するために選択したデバイスに応じて、80MHzのCortex-M4または216MHzのCortex-M7のいずれかでベンチマークを行った場合、推論結果が返されるのに必要な時間は0.8秒から6秒の範囲でした。ただし、この最終製品では画像を撮影する必要があるため、Cortex-M7の処理能力以上のものが必要になると思います。
要約すると、オープンソースのデータセットを使用して、さまざまな形態の糖尿病性網膜症(DR)を検出するための比較的十分に機能する機械学習モデルをトレーニングすることができました。最終的な目標は、このようなモデルを組み込みマイクロコントローラーまたはLinuxデバイスに直接展開し、以下のようなより多くの医療機器にエッジで推論を実行させることです。これにより、農村部で使用できる医療技術が提供され、医療へのアクセスが少ない人々にテストを提供するためのワイヤレス接続がなく、医療サービスの新しい可能性が開かれます。
確かに、医療機器に組み込み機械学習(ML)を導入する良い機会があります。さらなる改善の可能性を含む、このプロジェクトの詳細については、こちらをご覧ください。
埋め込み