


2017年は音声インターフェースの年ですか?
過去数年間で、自動音声認識(ASR)の大幅な進歩により、音声をメインインターフェイスとして使用するデバイスやアプリケーションが豊富に登場しました。 IEEEスペクトラム 雑誌は2017年を音声認識の年と宣言しました。 ZDNetはCES2017から、音声が次のコンピューターインターフェイスであると報告しました。そして他の多くの人も同様の見解を共有しています。では、音声インターフェースの進歩に関して、私たちはどこにいるのでしょうか。この投稿では、音声インターフェイスとその実現テクノロジーの現状を調査します。
何台のデバイスがあなたと会話しますか?
音声アクティベーションは私たちの周りにあります。ほとんどすべてのスマートフォンには音声インターフェースがあり、Apple iPhone7やSamsungGalaxyS7などの主力製品には常時リスニング機能が含まれています。ほとんどのスマートウォッチは、音声アクティベーションだけでなく、他のウェアラブル、特にAppleのAirPodsやSamsungのGearIconXなどのヒアラブルを提供します。これらのデバイスのほとんどでは、他のインターフェイスを統合する便利な方法がなく、音声が理想的で必要なソリューションになっています。 GoPro Hero 5などの新しいカメラは、音声コマンドを使用して操作できます。これは、自分撮りに最適です。音声起動のカーインフォテインメントシステムが商品になり、運転中に駅を変更するのがはるかに安全になりました。
Amazon Echoは、Google Homeが競合しようとしている会話アシスタントのトレンドに火をつけ、CES 2017で展示されたさまざまな同様のクローンを紹介しました。Alexaという名前のEchoの音声サービスには、いくつかのスキルが組み込まれています。たとえば、「アレクサ、冗談を言って」と言うことができます (非常に苦痛な配達)、「アレクサ、ウォリアーズは勝ちましたか?」 (もちろん彼らはそうしました)、または「映画2001年宇宙の旅に出演したアレクサ?」 (他の誰も知らないようです)。 「アレクサ、自己破壊シーケンスを開始して」と言ったときの応答のように、面白いイースターエッグもたくさんあります。 (Alexaのイースターエッグの一部を紹介するこのビデオも参照してください)。
組み込みの機能に加えて、Alexa Skills Kit(ASK)を使用して、サードパーティが新しい機能をAlexaに追加できます。このASKを使用すると、開発者はAlexaに新しいスキルを教えることができるため、Alexa(またはそれ?)はより多くの製品やサービスを制御および操作できます。たとえば、このビデオでわかるように、ある人がiRobot Roombaをハッキングし、掃除機ロボットを制御するスキルを追加しました。
その他のAlexaのスキルには、さまざまな飲食店に食べ物を注文したり、Uberを呼んだりするなどの便利なものや、魔法の8ボールの質問、サインフェルドの雑学クイズ、果物に関する新しい事実の学習などのランダムな娯楽が含まれます。 Amazonと、WhirlpoolやGEなどの企業とのコラボレーションにより、洗濯機、冷蔵庫、ランプなどの家電製品を制御する機能が追加され、スマートホームでのAlexaの適性も強化されます。
現在、アマゾンはこの市場でリードしているようですが、他の人は追いつくために多大な努力(そして投資)をしています。マーク・ザッカーバーグは、モーガン・フリーマンを彼の人工知能(AI)音声アシスタントの声として採用しました。彼がどのようにそれを構築したかを説明するメモによると、ザッカーバーグは、自宅の運営を支援するためのシンプルなAIとしてアプリケーションを開発するのに1年を費やしました「アイアンマンのジャービスのように」 (彼もそれをジャービスと名付けました)。ジャービスは、誰が話しているのかを声で識別し、顔も認識するため、ザッカーバーグに報告している間、許可された人を玄関に入れることができます。
もう1つの興味深い候補は、Gateboxと呼ばれる日本のAmazon-Echoのようなデバイスで、AzumaHikariという名前のホログラフィックキャラクターが特徴です。

Amazon Echoに対する日本の回答(出典:Gatebox)
シンプルなスピーカーに加えて、このデバイスはスクリーンとプロジェクターを利用して、仮想アシスタントを視覚的にも聴覚的にも生き生きとさせます。マイクに加えて、カメラ、モーションセンサー、温度センサーも備えているため、より包括的な方法でユーザーとやり取りできます。
その遠距離音声ピックアップはどのように機能しますか?
部屋の反対側で音楽を再生しているときに、デバイスはどのように音声コマンドを聞いて理解しますか?この偉業を可能にするために関与する多くのコンポーネントがありますが、それらのいくつかは最も重要です。 1つは、自動音声認識(ASR)エンジンです。これにより、機械は、私たちが作成した音を実行可能な命令に変換できます。 ASRエンジンが正しく機能するには、クリーンな音声サンプルを受信する必要があります。これには、干渉を除去するために、ノイズリダクションとエコーキャンセレーションが必要です。以下は、遠方界の音声ピックアップを可能にする最も重要なテクノロジーの一部です。
ディープラーニング これには大きな役割があります。自然言語を理解する能力はかなり数年前に確立されましたが、最近の改良により、自然言語は人間レベルの能力に近づきました。ディープニューラルネットワーク(DNN)のような学習ベースの技術を使用して、言語処理と視覚オブジェクト認識の両方が、多くのテストケースで人間のパフォーマンスと同等またはそれを上回っています。 DNNは、トレーニングフェーズ中に大量のデータセットを使用して生成されます。トレーニングがオフラインで実行された後、DNNはリアルタイムでその機能を実行するために使用されます。
アダプティブビームフォーミング 堅牢な音声起動ユーザーインターフェイスの鍵です。ノイズリダクション、ユーザーが話しているときに移動している場合のスピーカートラッキング、複数のユーザーが同時に話している場合のスピーカーの分離などの機能を有効にします。
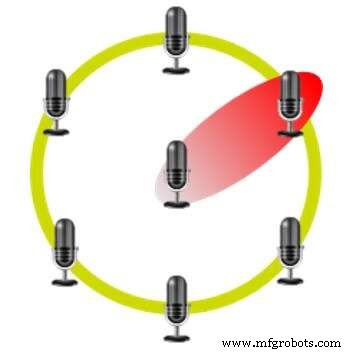
六角形のマイクアレイを使用したビームフォーミング(出典:CEVA)
この方法では、複数のマイクを相互に固定した位置で使用します。たとえば、Amazon Echoは、六角形のレイアウトで7つのマイクを使用し、各頂点に1つのマイク、中央に1つのマイクを使用します。さまざまなマイクで信号を受信するまでの時間遅延により、デバイスは音声がどこから来ているかを識別し、他の方向から来る音をキャンセルすることができます。
アコースティックエコーキャンセレーション 自動音声認識を実行する製品の多くは、それ自体も音を生成するため、必要です。たとえば、音楽を再生したり、情報を配信したりします。これらのアクションを実行している間でも、ユーザーが音楽を中断(バージイン)して停止したり、別のアクションを要求したりできるように、デバイスは聞こえる必要があります。聴き続けるには、機械が発する音を打ち消すことができなければなりません。これは、音響エコーキャンセレーション(AEC)と呼ばれます。
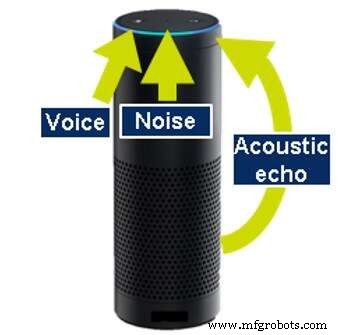
音響エコーキャンセレーション(出典:CEVA)
AECを実行するには、デバイスは、出力データを分析するか、追加の専用マイクで生成された音を聞くことによって、生成している音を認識している必要があります。同様のテクノロジーを適用して、デバイスの周囲の壁やその他のオブジェクトから跳ね返るエコーを除去します。

DNN、ビームフォーミング、およびエコーキャンセレーションアルゴリズムをモデル化するためのマルチマイク開発プラットフォーム(出典:CEVA)
別のタイプのエコーは、オブジェクトまたは壁から跳ね返るときにユーザーコマンド自体によって生成されます。このような予測不可能なエコーをキャンセルするには、残響除去と呼ばれるさらに別のアルゴリズムが必要です。その後、サウンドはフィルタリングされ、マシンはユーザーからのコマンドをリッスンできます。
今日の音声インターフェースは完璧にはほど遠いです
一方で、2017年は、音声インターフェースがすでに普及していることを考えると、音声インターフェースにとって注目に値する年のように見えます。一方で、過去数年間の目覚ましい進歩にもかかわらず、まだ長い道のりがあります。
大量生産されたデバイスでの音声インターフェイスの現在の実装には多くの問題が残っていますが、それは将来のコラムのトピックになります。次の投稿では、今日の音声インターフェイスを悩ませているいくつかの欠陥と欠落している機能を調べる予定です。必ず調整してください。
エランベラッシュ はCEVAのオーディオおよび音声製品ラインの製品マーケティングマネージャーであり、音声トリガーやモバイル音声からワイヤレスオーディオや高精細ホームオーディオに至るまで、絶妙なソリューションを作り上げています。没入型サウンドの魅力的な世界に夢中になっているわけではありませんが、エランは水中世界の魅惑的な沈黙にフリーダイビングするのが好きです。
埋め込み