


ArduinoでのTinyMLによる咳の検出
コンポーネントと消耗品
>  |
| × | 1 |
アプリとオンラインサービス
>  |
|
このプロジェクトについて
COVID-19やその他のインフルエンザ関連の早期発見のための安価で簡単に展開できるソリューションが非常に必要とされています。国連、ハックスター、エッジインパルス、その他多くの人々と協力して、開発途上国でインフルエンザを予防および検出するための簡単に展開できるソリューションを作成することを目的として、最近、国連コビッド検出および保護チャレンジを開始しました。このチュートリアルでは、Arduino Nano BLESenseでEdgeImpulse機械学習を使用して、リアルタイムオーディオの咳の存在を検出する方法を示します。咳とバックグラウンドノイズのサンプルのデータセットを構築し、高度に最適化されたTInyMLモデルを適用して、Nano BLESenseの20kB未満のRAMでリアルタイムに実行される咳検出システムを構築しました。この同じアプローチは、高齢者介護、安全、機械監視など、他の多くの組み込みオーディオパターンマッチングアプリケーションにも当てはまります。このプロジェクトとデータセットは、もともとCOVID-19の取り組みを支援するためにKartikThakoreによって開始されました。
はじめに
このチュートリアルには、次の要件があります。
- ソフトウェア開発とArduinoの基本的な理解
- インストールされたArduinoIDEまたはCLI
- AndroidまたはiOS携帯電話
- Arduino Nano BLESenseまたは同等のマイク付きCortex-M4 +ボード(オプション)
エッジデバイスでの機械学習用のオンライン開発プラットフォームであるEdgeImpulseを使用します。こちらからサインアップして、無料のアカウントを作成してください。アカウントにログインし、タイトルをクリックして新しいプロジェクトに名前を付けます。私たちは私たちを「Arduino咳チュートリアル」と呼んでいます。
<図>
データセットの収集
機械学習プロジェクトの最初のステップは、Arduinoデバイスで照合できるようにしたいデータの既知のサンプルを表すデータセットを収集することです。開始するために、「咳」と「ノイズ」の2つのクラスで10分の音声を含む小さなデータセットを作成しました。このデータセットをEdgeImpulseプロジェクトにインポートする方法、独自のサンプルを追加する方法、または独自のデータセットを最初から開始する方法を示します。このデータセットは小さく、咳とソフトバックグラウンドノイズのサンプル数が限られています。したがって、データセットは実験にのみ適切であり、このチュートリアルで作成されたモデルは、静かなバックグラウンドノイズと狭い範囲の咳のみを区別できます。パフォーマンスを向上させるために、咳、バックグラウンドノイズ、および人間の発話などの他のクラスの範囲を広げてデータセットを拡張することをお勧めします。
注: 声帯に咳を強いるのは非常に難しいので、データを収集してテストするときは注意してください!
まず、咳のデータセットをダウンロードし、PCの選択した場所でファイルを抽出します:https://cdn.edgeimpulse.com/datasets/cough.zip
Edge Impulse CLIアップローダーを使用して、このデータセットをEdgeImpulseプロジェクトにインポートできます。これらのインストール手順に従って、Edge ImpulseCLIをインストールします。
ターミナルまたはコマンドプロンプトを開き、ファイルを抽出したフォルダーに移動します。
実行:
$ edge-impulse-uploader --clean
$ edge-impulse-uploader--categoryトレーニングトレーニング/ *
$ edge-impulse-uploader--categoryテストテスト/ * Edge Impulseのユーザー名、パスワード、およびデータセットを追加するプロジェクトの入力を求められます。データセットのサンプルがデータ取得に表示されるようになります ページ。サンプルをクリックすると、サンプルがどのように見えるかを確認でき、各グラフの下にある再生ボタンをクリックして音声を聞くことができます。
<図>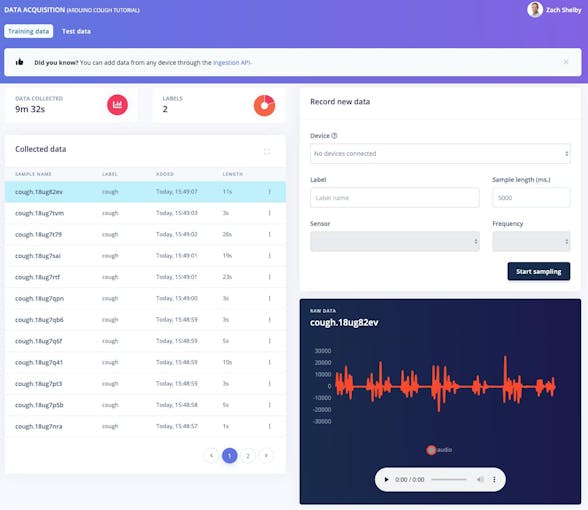
開始するには、10分間の咳とノイズのデータサンプルで十分です。オプションで、独自の咳とバックグラウンドノイズのサンプルを使用してデータセットを拡張できます。 データ取得からデバイスから直接新しいデータサンプルを収集できます ページ。 WAV形式のオーディオサンプルは、Edge ImpulseCLIアップローダーを使用してアップロードすることもできます。
始める最も簡単な方法は、携帯電話を使用してオーディオデータを収集することです(完全なチュートリアルはこちら)。 デバイスに移動します ページをクリックし、右上の[+新しいデバイスを接続]ボタンをクリックします。 [携帯電話を使用する]を選択します。これにより、電話のブラウザでWebアプリケーションを開くための一意のQRコードが生成されます。 QRコードの写真を撮り、選択してリンクを開きます。
<図>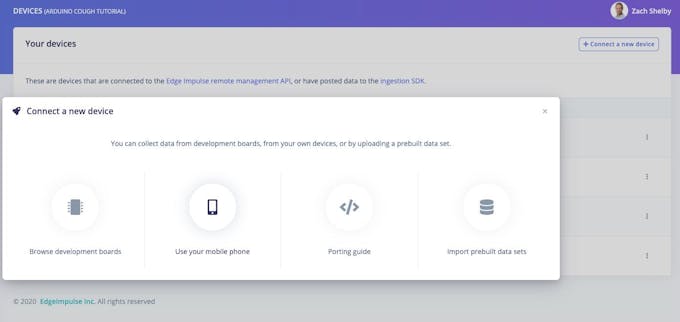
WebアプリケーションはEdgeImpulseプロジェクトに接続し、次のようになります。
<図>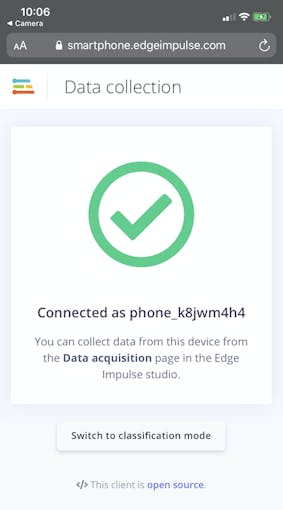
データ取得から電話から直接オーディオデータサンプルを収集できるようになりました エッジインパルスのページ。 [新しいデータの記録]セクションで、「咳」または「ノイズ」のラベルを入力し、センサーとして「マイク」が選択されていることを確認して、「サンプリングの開始」をクリックします。これで、携帯電話が音声サンプルを収集し、データセットに追加します。
<図>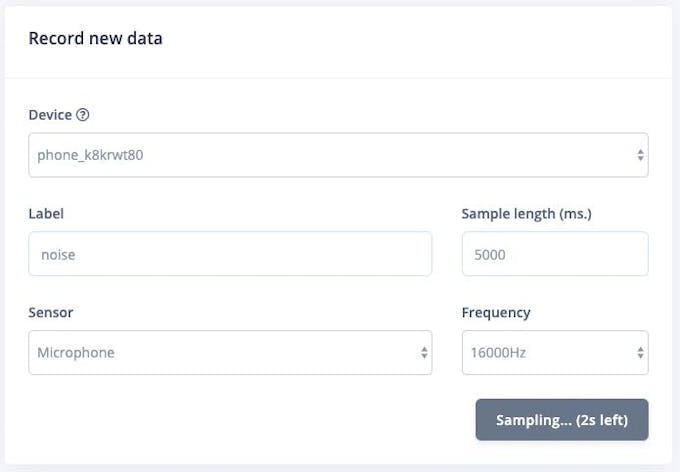
Nano BLESenseボードから直接オーディオデータを収集することもサポートされています。次の手順に従って、EdgeImpulseファームウェアとデーモンをインストールします。デバイスがEdgeImpulseに接続されると、上記の携帯電話と同じようにデータサンプルを収集できます。
<図>
インパルスを作成する
次に、インパルスの作成で、信号処理と機械学習ブロックを選択します ページ。インパルスは、生データと出力機能ブロックで空白で始まります。 1000ミリ秒のウィンドウサイズと500ミリ秒のウィンドウ増加のデフォルト設定のままにします。これは、オーディオデータが一度に1秒ずつ処理され、0.5秒ごとに処理されることを意味します。小さなウィンドウを使用すると、組み込みデバイスのメモリを節約できますが、咳の間に大きな切れ目がないサンプルの咳データが必要になることを意味します。
<図>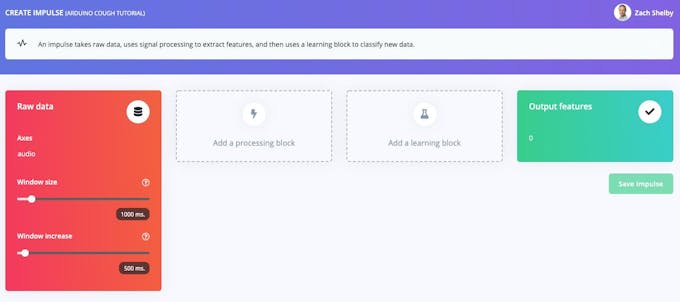
[処理ブロックを追加]をクリックして、オーディオ(MFCC)を選択します ブロック。次に、[学習ブロックを追加]をクリックして、ニューラルネットワーク(Keras)を選択します ブロック。 [インパルスを保存]をクリックします。オーディオブロックはオーディオの各ウィンドウのスペクトログラムを抽出し、ニューラルネットワークブロックはトレーニングデータセットに基づいてスペクトログラムを「咳」または「ノイズ」として分類するようにトレーニングされます。結果として生じる衝動は次のようになります:
<図>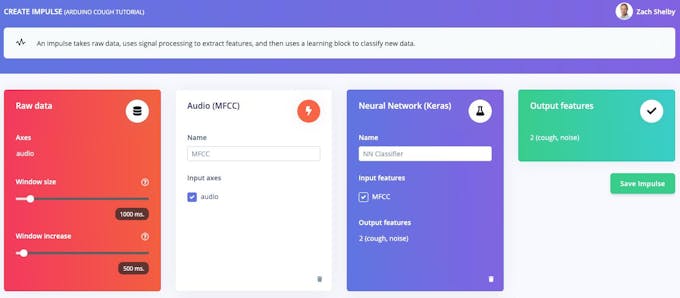
次に、 MFCC のトレーニングデータセットから機能を生成します ページ。このページは、任意のデータセットサンプルから1秒ごとに抽出されたスペクトログラムがどのように見えるかを示しています。パラメータはデフォルトのままにしておくことができます。
<図>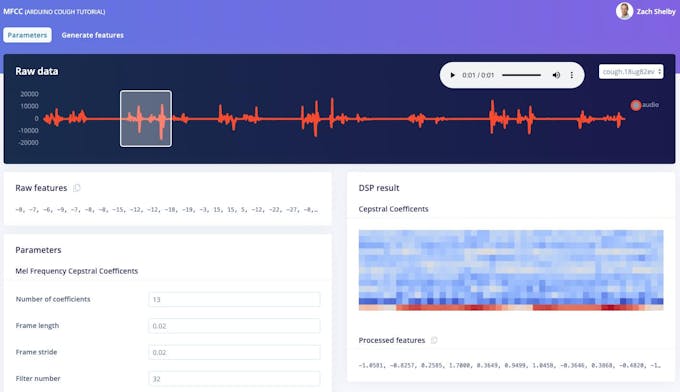
次に、[機能の生成]ボタンをクリックします。このボタンは、この処理ブロックを使用してトレーニングデータセット全体を処理します。これにより、次のステップでニューラルネットワークをトレーニングするために使用される機能の完全なセットが作成されます。 [機能の生成]ボタンを押して処理を開始します。完了するまでに数分かかります。
<図>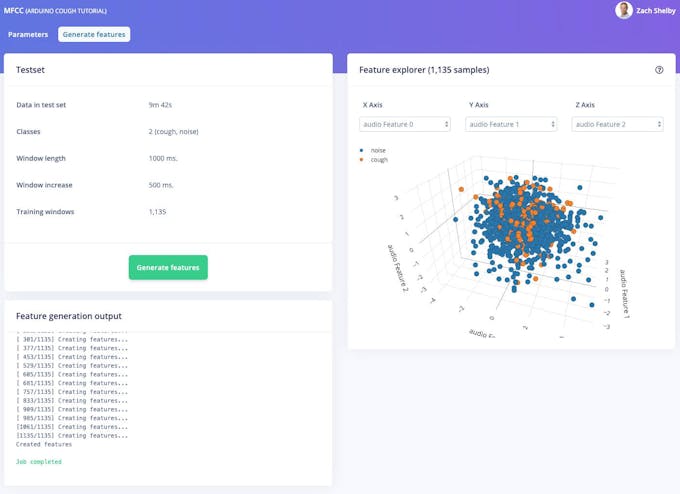
これで、 NN分類器でニューラルネットワークのセットアップとトレーニングに進むことができます。 ページ。デフォルトのニューラルネットワークは、水が流れるような継続的な音に適しています。咳の検出はより複雑なので、各ウィンドウのスペクトログラム全体で2D畳み込みを使用してよりリッチなネットワークを構成します。 2D畳み込みは、画像分類と同様の方法でオーディオスペクトログラムを処理します。 [ニューラルネットワーク設定]セクションの右上隅を押して、[Keras(エキスパート)モードに切り替える]を選択します。
<図>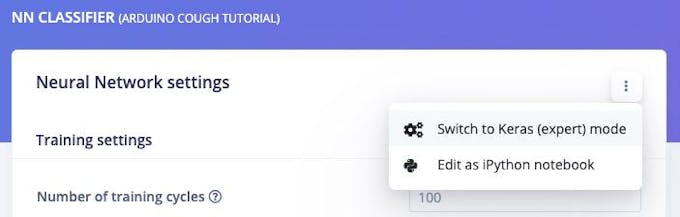
「ニューラルネットワークアーキテクチャ」の定義を次のコードに置き換え、「最小信頼度」設定を「0.70」に設定します。次に、[トレーニングを開始]ボタンをクリックします。トレーニングには数秒かかります。
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense、InputLayer、Dropout、Flatten、Reshape、BatchNormalization、Conv2D、MaxPooling2D、AveragePooling2D
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.constraints import MaxNorm
#モデルアーキテクチャ
model =Sequential()
model.add(InputLayer( input_shape =(X_train.shape [1]、)、name ='x_input'))
model.add(Reshape((int(X_train.shape [1] / 13)、13、1)、input_shape =( X_train.shape [1]、)))
model.add(Conv2D(10、kernel_size =5、activation ='relu'、padding ='same'、kernel_constraint =MaxNorm(3)))
model.add(AveragePooling2D(pool_size =2、padding ='same'))
model.add(Conv2D(5、kernel_size =5、activation ='relu'、padding ='same'、kernel_constraint =MaxNorm(3 )))
model.add(AveragePooling2D(pool_size =2、padding ='same'))
model.add(Flatten())
model.add(Dense(classes、activation ='softmax'、name ='y_pred'、kernel_co nstraint =MaxNorm(3)))
#これは学習率を制御します
opt =Adam(lr =0.005、beta_1 =0.9、beta_2 =0.999)
#ニューラルネットワークをトレーニングします
model.compile(loss ='categorical_crossentropy'、optimizer =opt、metrics =['accuracy'])
model.fit(X_train、Y_train、batch_size =32、epochs =9、validation_data =(X_test、Y_test) 、verbose =2) このページには、トレーニングのパフォーマンスとデバイス上のパフォーマンスが表示されます。データセットによっては、次のようになります。
<図>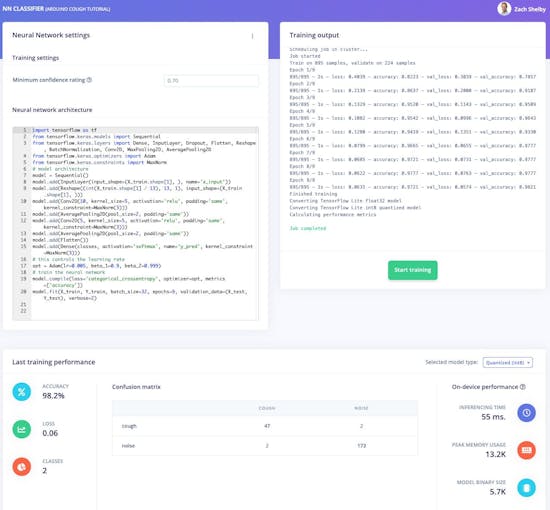
これで、Arduinoの咳検出アルゴリズムを試す準備が整いました!
トレーニングとテスト
ライブ分類 このページでは、データセットに付属している既存のテストデータを使用するか、携帯電話またはArduinoデバイスからオーディオデータをストリーミングすることによって、アルゴリズムをテストできます。テストサンプルのいずれかを選択し、[サンプルの読み込み]を押すことで、簡単なテストから始めることができます。これにより、テストサンプルが分類され、結果が表示されます。
<図>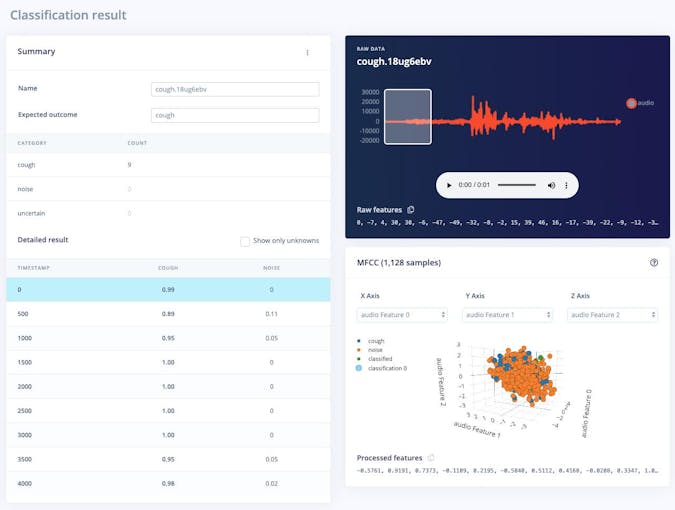
ライブデータを使用してアルゴリズムをテストすることもできます。以前に開いた携帯電話のブラウザページを更新して、携帯電話から始めます。次に、[新しいデータの分類]セクションでデバイスを選択し、[サンプリングの開始]を押します。データ収集ステップのように、edge-impulse-daemonを介してプロジェクトに接続すると、同様にNano BLESenseからオーディオサンプルをストリーミングできます。
導入
咳検知アルゴリズムを携帯電話に簡単に導入できます。携帯電話のブラウザウィンドウに移動して更新し、[分類モードに切り替える]ボタンを押します。これにより、プロジェクトが自動的にWebAssemblyパッケージに組み込まれ、携帯電話で継続的に実行されます(その後、クラウドは必要ありません。機内モードに移行することもできます)
<図>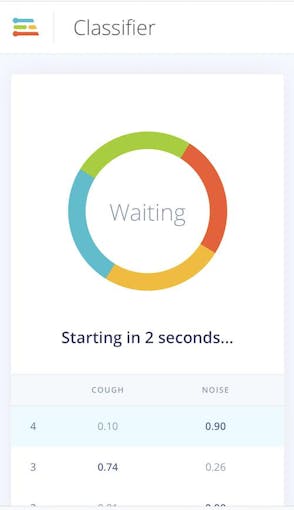
次に、導入に移動して、アルゴリズムをNano BLESenseに導入できます。 ページ。 [ファームウェアのビルド]で[ArduinoNano 33 BLE Sense]を選択し、[ビルド]をクリックします。
<図>
これにより、最新のアルゴリズムを含むNano BLESenseの完全なファームウェアが構築されます。画面の指示に従って、Arduinoボードをバイナリでフラッシュします。
<図>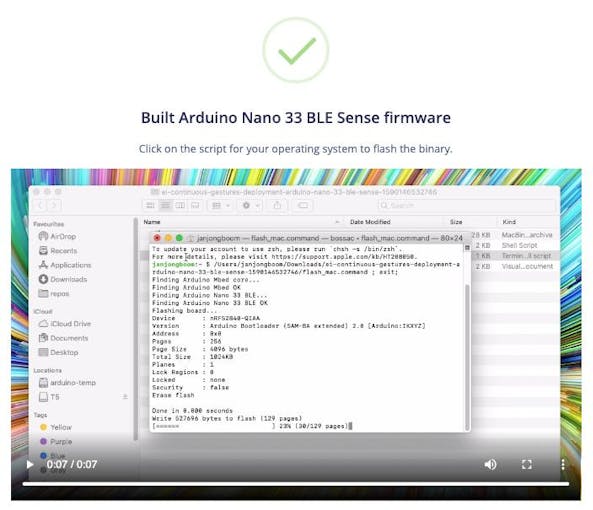
Arduinoがフラッシュされると、115、200ボーでUSBに接続されている間、デバイスへのシリアルポートを開くことができます。シリアルポートが開いたら、Enterキーを押してプロンプトを表示し、次に:
> AT + RUNIMPULSE
推論設定:
間隔:0.06ms。
フレームサイズ:16000
サンプル長:1000ms。
いいえ。クラスの数:2
推論を開始し、「b」を押して中断します
記録...
記録が完了しました
予測(DSP:495ミリ秒、分類:84ミリ秒、異常:0ミリ秒):
咳:0.01562
ノイズ:0.98438
2秒で推論を開始...
記録中...
記録完了
予測(DSP:495ミリ秒、分類:84ミリ秒、異常:0ミリ秒):
咳:0.01562
ノイズ:0.98438
2秒で推論を開始...
記録中...
記録完了
予測(DSP:495ミリ秒、分類:84ミリ秒、異常:0ミリ秒):
咳:0.86719
ノイズ:0.13281
2秒で推論を開始します...
記録しています...
記録が完了しました
予測(DSP:495ミリ秒、分類:84ミリ秒、異常:0ミリ秒) :
咳:0.01562
ノイズ:0.98438
今後の作業
空はArduinoのTinyML、センサー、エッジインパルスの限界です。これからの作業のアイデアをいくつか紹介します。
- 独自の咳と背景音でデフォルトのデータセットを拡張し、定期的に再トレーニングしてテストすることを忘れないでください。 [テスト]ページで単体テストを設定して、モデルが拡張されても機能していることを確認できます。
- 背景のスピーチ、あくびなど、咳をしていない人間の音の新しいクラスとデータを追加します。
- 新しいデータセットから始めて、オーディオサンプルを収集し、新しいものを検出します。ヒント:このデータセットからノイズクラスデータだけをアップロードして開始できます!
- これらの手順から、Arduinoスケッチの一部としてArduinoライブラリにデプロイし、LEDまたはディスプレイを使用して咳の検出を表示します
- このチュートリアルに従って、Nano BLESenseの3軸加速度計などの他のセンサーを利用してください。
製造プロセス