


Hadoop とは? Hadoop ビッグデータ処理
ビッグデータの進化は、新しいソリューションを必要とする新しい課題を生み出しました。史上かつてないほど、サーバーは膨大な量のデータをリアルタイムで処理、並べ替え、保存する必要があります。
この課題により、大規模なデータセットを簡単に処理できる Apache Hadoop などの新しいプラットフォームが出現しました。
この記事では、Hadoop とは何か、その主なコンポーネントは何か、Apache Hadoop がビッグ データの処理にどのように役立つかについて説明します。
Hadoop とは
Apache Hadoop ソフトウェア ライブラリは、分散コンピューティング環境でビッグデータを効率的に管理および処理できるオープンソース フレームワークです。
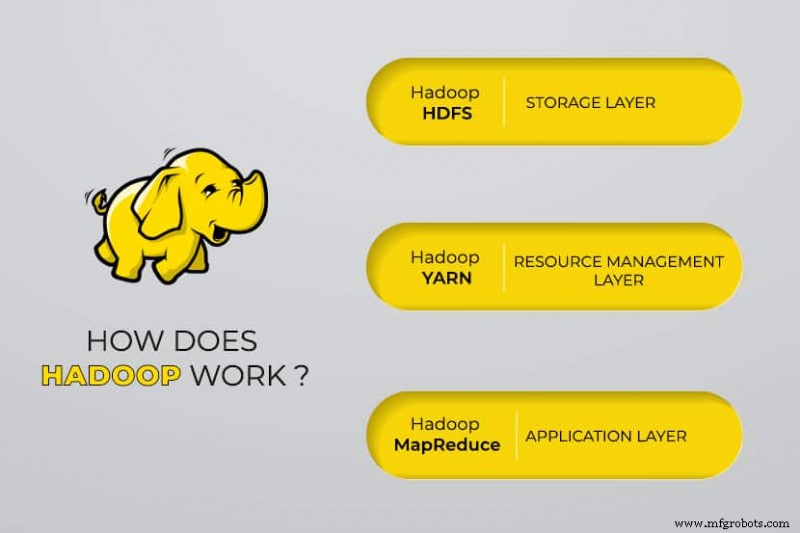
Apache Hadoop は 4 つのメイン モジュールで構成されています :
Hadoop 分散ファイル システム (HDFS)
データは、Hadoop の分散ファイル システムに存在します。これは、一般的なコンピューターのローカル ファイル システムに似ています。 HDFS は、従来のファイル システムと比較して、より優れたデータ スループットを提供します。
さらに、HDFS は優れたスケーラビリティを提供します。 1 台のマシンから数千台のマシンまで、コモディティ ハードウェアで簡単に拡張できます。
さらに別のリソース ネゴシエーター (YARN)
YARN は、スケジュールされたタスク、クラスター ノードおよびその他のリソース全体の管理と監視を容易にします。
MapReduce
Hadoop MapReduce モジュールは、プログラムが並列データ計算を実行するのに役立ちます。 MapReduce の Map タスクは、入力データをキーと値のペアに変換します。 Reduce タスクは、入力を消費して集計し、結果を生成します。
Hadoop 共通
Hadoop Common は、すべてのモジュールで標準の Java ライブラリを使用します。
Hadoop が開発された理由
World Wide Web は過去 10 年間で指数関数的に成長し、現在では数十億のページで構成されています。膨大な量のため、オンラインで情報を検索することは困難になりました。このデータはビッグデータになり、次の 2 つの主な問題で構成されています。
<オール>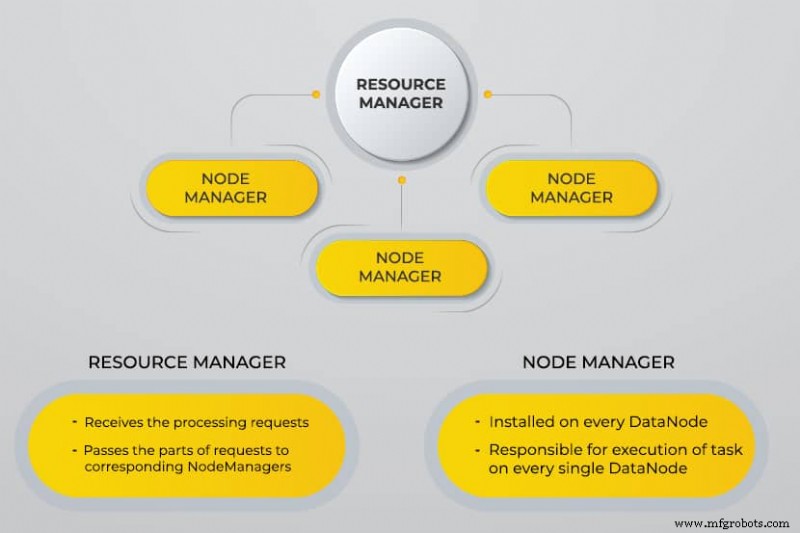
開発者は、上記の問題に対処することで、Web 検索結果をより迅速かつ効率的に返すために、多くのオープンソース プロジェクトに取り組んできました。彼らの解決策は、サーバーのクラスター全体にデータと計算を分散させて同時処理を実現することでした。
最終的に、Hadoop はこれらの問題の解決策となり、サーバー導入コストの削減など、他の多くの利点をもたらしました。
Hadoop ビッグデータ処理のしくみ
Hadoop を使用して、クラスターのストレージと処理能力を活用し、ビッグデータの分散処理を実装します。基本的に、Hadoop はビッグデータを処理する他のアプリケーションを構築するための基盤を提供します。
さまざまな形式でデータを収集するアプリケーションは、NameNode に接続する Hadoop の API を介して Hadoop クラスターにデータを保存します。 NameNode は、ファイル ディレクトリの構造と、作成された各ファイルの「チャンク」の配置をキャプチャします。 Hadoop は、並列処理のためにこれらのチャンクを DataNode 全体に複製します。
MapReduce はデータのクエリを実行します。すべての DataNode をマップし、HDFS 内のデータに関連するタスクを削減します。 「MapReduce」という名前自体が、その機能を説明しています。マップ タスクは、提供された入力ファイルのすべてのノードで実行されますが、リデューサーはデータをリンクして最終出力を整理するために実行されます。
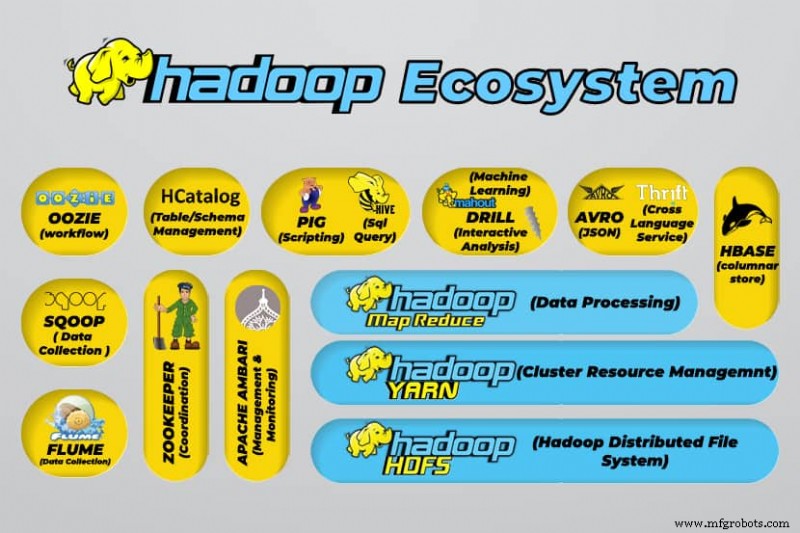
Hadoop ビッグデータ ツール
Hadoop のエコシステムは、さまざまなオープンソースのビッグデータ ツールをサポートしています。これらのツールは、Hadoop のコア コンポーネントを補完し、ビッグ データの処理能力を強化します。
最も有用なビッグデータ処理ツールには次のものがあります:
- アパッチ ハイブ
Apache Hive は、Hadoop のファイル システムに保存された大量のデータ セットを処理するためのデータ ウェアハウスです。
- Apache Zookeeper
Apache Zookeeper はフェイルオーバーを自動化し、失敗した NameNode の影響を軽減します。
- Apache HBase
Apache HBase は、Hadoop 用のオープンソースのノンリレーション データベースです。
- Apache Flume
Apache Flume は、大量のログデータをストリーミングするための分散サービスです。
- Apache Sqoop
Apache Sqoop は、Hadoop とリレーショナル データベースの間でデータを移行するためのコマンドライン ツールです。
- アパッチ ピッグ
Apache Pig は、Hadoop で実行されるジョブを開発するための Apache の開発プラットフォームです。使用されているソフトウェア言語は Pig Latin です。
- アパッチ ウージー
Apache Oozie は、Hadoop ジョブの管理を容易にするスケジューリング システムです。
- Apache HCatalog
Apache HCatalog は、さまざまなデータ処理ツールからのデータを並べ替えるためのストレージおよびテーブル管理ツールです。
Hadoop の利点
Hadoop はビッグ データ処理の堅牢なソリューションであり、ビッグ データを扱う企業にとって不可欠なツールです。
Hadoop の主な機能と利点を以下に詳しく説明します。
- 大量のデータの保存と処理の高速化
保存するデータ量は、ソーシャル メディアとモノのインターネット (IoT) の登場により劇的に増加しました。これらのデータセットの保存と処理は、データセットを所有する企業にとって重要です。 - 柔軟性
Hadoop の柔軟性により、テキスト、シンボル、画像、動画などの非構造化データ タイプを保存できます。 RDBMS のような従来のリレーショナル データベースでは、データを保存する前に処理する必要があります。しかし、Hadoop では、データをそのまま保存し、後でどのように処理するかを決定できるため、データの前処理は必要ありません。つまり、NoSQL データベースとして動作します。 - 処理能力
Hadoop は、分散コンピューティング モデルを通じてビッグ データを処理します。処理能力を効率的に使用することで、高速かつ効率的になります。 - コストの削減
多くのチームは、Hadoop のようなフレームワークが登場する前に、コストが高くつくためにプロジェクトを断念しました。 Hadoop はオープンソースのフレームワークであり、無料で使用でき、安価な汎用ハードウェアを使用してデータを保存します。 - スケーラビリティ
Hadoop を使用すると、クラスタ内のノード数を変更するだけで、多くの管理を必要とせずにシステムをすばやくスケーリングできます。 - 耐障害性
分散データ モデルを使用することの多くの利点の 1 つは、障害を許容できることです。 Hadoop は、可用性を維持するためにハードウェアに依存しません。デバイスに障害が発生した場合、システムはタスクを別のデバイスに自動的にリダイレクトします。クラスター全体でデータの複数のコピーを保存することによって冗長データが維持されるため、フォールト トレランスが可能になります。つまり、高可用性はソフトウェア レイヤーで維持されます。
3 つの主な使用例
ビッグデータの処理
通常、ペタバイト以上の膨大な量のデータには Hadoop をお勧めします。膨大な処理能力を必要とする大量のデータに適しています。 Hadoop は、数百ギガバイトの範囲の少量のデータを処理する組織にとって最適な選択肢ではない可能性があります。
さまざまなデータ セットの保存
Hadoop を使用する多くの利点の 1 つは、柔軟性が高く、さまざまなデータ型をサポートすることです。データがテキスト、画像、またはビデオ データで構成されているかどうかに関係なく、Hadoop はデータを効率的に格納できます。組織は、要件に応じてデータの処理方法を選択できます。 Hadoop は、格納されたデータに柔軟性を提供するため、データ レイクの特性を備えています。
並列データ処理
Hadoop で使用される MapReduce アルゴリズムは、格納されたデータの並列処理を調整します。つまり、複数のタスクを同時に実行できます。ただし、Hadoop の標準的な方法論を混乱させるため、共同操作は許可されていません。データが互いに独立している限り、並列処理が組み込まれます。
実世界での Hadoop の用途
世界中の企業が Hadoop ビッグデータ処理システムを使用しています。 Hadoop の多くの実用的な用途のいくつかを以下に示します:
- お客様の要件を理解する
現在、Hadoop は顧客の要件を理解するのに非常に役立つことが証明されています。金融業界やソーシャルメディアの大手企業は、この技術を使用して、顧客の活動に関するビッグデータを分析することで、顧客の要件を理解しています。
企業はそのデータを使用して、パーソナライズされたオファーを顧客に提供します。これは、ソーシャル メディアや e コマース サイトに表示される広告を通じて、私たちの興味やインターネット活動に基づいて経験したことがあるかもしれません。 - ビジネス プロセスの最適化
Hadoop は、トランザクションと顧客データをより適切に分析することで、ビジネスのパフォーマンスを最適化するのに役立ちます。トレンド分析と予測分析は、企業が製品や在庫をカスタマイズして売上を伸ばすのに役立ちます。このような分析は、より良い意思決定を容易にし、より高い利益につながります。
さらに、企業は Hadoop を使用して、相互のやり取りに関するデータを収集して従業員の行動を監視し、職場環境を改善しています。 - 医療サービスの改善
医療業界の機関は、Hadoop を使用して、健康問題や治療結果に関する膨大な量のデータを監視できます。研究者はこのデータを分析して、健康上の問題を特定し、投薬を予測し、治療計画を決定できます。このような改善により、各国は医療サービスを迅速に改善できます。 - 金融取引
Hadoop には、事前定義された設定で市場データをスキャンして、取引機会と季節的な傾向を特定する洗練されたアルゴリズムがあります。金融会社は、Hadoop の堅牢な機能を通じて、これらの業務のほとんどを自動化できます。 - IoT に Hadoop を使用する
IoT デバイスが効率的に機能するには、データの可用性に依存します。メーカーや発明者は、何十億ものトランザクションのデータ ウェアハウスとして Hadoop を使用しています。 IoT はデータ ストリーミングの概念であるため、Hadoop は、それに含まれる膨大な量のデータを管理するための適切で実用的なソリューションです。
Hadoop は継続的に更新され、IoT プラットフォームで使用される命令を改善することができます。
Hadoop のその他の実用的な用途には、デバイスのパフォーマンスの改善、個人の定量化とパフォーマンスの最適化の改善、スポーツと科学研究の改善が含まれます。
Hadoop を使用する上での課題は何ですか?
すべてのアプリケーションには、利点と課題の両方が伴います。 Hadoop にはいくつかの課題もあります。
- MapReduce アルゴリズムが常に解決策であるとは限りません
MapReduce アルゴリズムは、すべてのシナリオをサポートしているわけではありません。独立したユニットにまとめられた単純な情報要求と問題には適していますが、反復的なタスクには適していません。
MapReduce は、高度な分析コンピューティングには非効率的です。反復アルゴリズムには集中的な相互通信が必要であり、MapReduce フェーズで複数のファイルが作成されるためです。 - 完全に開発されたデータ管理
Hadoop は、データ管理、メタデータ、およびデータ ガバナンスのための包括的なツールを提供しません。さらに、データの標準化と品質の決定に必要なツールが不足しています。 - 才能のギャップ
Hadoop の学習曲線は急勾配であるため、MapReduce で生産性を上げるのに十分な Java スキルを持つ初心者レベルのプログラマーを見つけるのは難しい場合があります。 MapReduce のスキルよりも SQL の十分な知識を持つプログラマーを見つける方がはるかに簡単であるため、プロバイダーが Hadoop の上にリレーショナル (SQL) データベース テクノロジを配置することに関心を持っている主な理由は、この集中力にあります。
Hadoop の管理は技術と科学の両方であり、オペレーティング システム、ハードウェア、Hadoop カーネル設定に関する低レベルの知識が必要です。 - データ セキュリティ
Kerberos 認証プロトコルは、Hadoop 環境を安全にするための重要なステップです。断片化されたデータ セキュリティの問題からビッグデータ システムを保護するには、データ セキュリティが不可欠です。
結論
Hadoop は、その課題を克服するために必要な手順で効果的に実装された場合、ビッグ データ処理に非常に効果的に対処できます。これは、大量のデータを扱う企業にとって汎用性の高いツールです。
その主な利点の 1 つは、任意のハードウェアで実行でき、Hadoop クラスターを数千のサーバーに分散できることです。このような柔軟性は、infrastructure-as-code 環境では特に重要です。
クラウドコンピューティング