


ZephyrベースのIoTアプリケーションをデバッグするためのベストプラクティス
Linux Foundation Zephyrオープンソースプロジェクトは、多くのIoTプロジェクトのバックボーンに成長しました。 Zephyrは、複数のアーキテクチャにわたって、リソースに制約のあるデバイス向けに最適化された、クラス最高の小型でスケーラブルなリアルタイムオペレーティングシステム(RTOS)を提供します。このプロジェクトには現在、1,000人の貢献者と50,000人のコミットがあり、ARC、Arm、Intel、Nios、RISC-V、SPARC、Tensilica、および250を超えるボードを含む複数のアーキテクチャの高度なサポートを構築しています。
Zephyrを使用する場合、接続を維持して確実に機能させるための重要な考慮事項がいくつかあります。開発者は自分のデスクですべてのクラスの問題を解決することはできず、デバイスのフリートが増えたときにのみ明らかになるものもあります。ネットワークとネットワークスタックが進化するにつれて、アップグレードによって不要な問題が発生しないようにする必要があります。
たとえば、家畜を追跡するために展開されたGPSトラッカーで直面した状況を考えてみます。デバイスは、フットプリントの小さいセンサーベースのカラーでした。ある日、動物はモバイルネットワークからモバイルネットワークに移動しました。国から国へ;場所から場所へ。このような動きは、電力損失につながる可能性のある誤った構成や予期しない動作をすぐに明らかにし、大きな経済的損失をもたらしました。問題について知る必要はありませんでした。問題が発生した理由と修正方法を知る必要がありました。接続されたデバイスを操作する場合、リモートモニタリングとデバッグは、何がうまくいかなかったか、状況に対処するための次の最善のステップ、そして最終的には通常の操作を確立して維持する方法を即座に把握するために重要です。
Zephyrとクラウドベースのデバイス可観測性プラットフォームMemfaultを組み合わせて使用し、デバイスの監視と更新をサポートします。私たちの経験では、両方を活用して、再起動、ウォッチドッグ、障害/アサート、および接続メトリックを使用したリモート監視のベストプラクティスを確立できます。
可観測性プラットフォームの設定
Memfaultを使用すると、開発者はファームウェアをリモートで監視、デバッグ、および更新できます。これにより、次のことが可能になります。
- 最小限の実行可能な製品と0日目の更新を優先して、生産の凍結を回避します
- デバイス全体の状態を継続的に監視する
- エンドユーザーが問題に気付く前に、更新とパッチをプッシュします
MemfaultのSDKは、クラウド分析と重複排除の問題のためにデータのパケットを収集するために簡単に統合されます。マニフェストファイルに追加する一般的なZephyrモジュールのように機能します。
#west.yml [...] -名前:memfault-firmware-sdk url:https://github.com/memfault/memfault-firmware-sdk パス:modules / memfault-firmware-sdk リビジョン:マスター #prj.conf CONFIG_MEMFAULT =y CONFIG_MEMFAULT_HTTP_ENABLE =y
最初の重点分野:再起動
デバイスのリセットが大幅に増加したとします。これは多くの場合、トポロジ内の何かが変更されたか、ハードウェアの欠陥が原因でデバイスで問題が発生し始めていることを示す初期の指標です。これは、デバイスの状態に関する洞察を得るために収集できる最小の情報であり、ハードウェアのリセットとソフトウェアのリセットの2つの部分で考えるのに役立ちます。
ハードウェアのリセットは、多くの場合、ハードウェアウォッチドッグと電圧低下が原因です。ソフトウェアのリセットは、ファームウェアの更新、アサート、またはユーザーが開始することによって発生する可能性があります。
発生しているリセットの種類を特定すると、フリート全体に影響を及ぼしている問題があるのか、それともデバイスのごく一部に限定されているのかを理解できます。
再起動の理由を記録する
void fw_update_finish(void){ // ... memfault_reboot_tracking_mark_reset_imminent(kMfltRebootReason_FirmwareUpdate、...); sys_reboot(0); } Zephyrには、Memfaultがフックするリセット全体で保持される領域を登録するためのメカニズムがあります。プラットフォームを再起動する場合は、開始する直前に保存することをお勧めします。プラットフォームを再起動するときは、再起動の理由(この場合はファームウェアの更新)を記録してから、Zephyrsys_rebootと呼びます。
Zephyrでのデバイスリセットのキャプチャ
起動情報を読み取るinitハンドラーを登録します
静的 int record_reboot_reason(){ // 1。ハードウェアリセット理由レジスタを読み取ります。 (レジスタ名についてはMCUデータシートを確認してください) // 2.noinitRAMからソフトウェアリセット理由をキャプチャします // 3。集計のためにサーバーにデータを送信します } SYS_INIT(record_reboot_reason、APPLICATION、 CONFIG_KERNEL_INIT_PRIORITY_DEFAULT); MCUリセット理由レジスタを介して、リセット前にシステム情報をキャプチャするマクロを設定できます。デバイスが再起動すると、Zephyrは system_intマクロを使用してハンドラーを登録します。 MCUリセット理由レジスタはすべてわずかに異なる名前を持っており、ハードウェアの問題や欠陥があるかどうかを確認できるので便利です。
例:電源の問題
再起動と電源を調べることで、リモート監視がフリートの健全性に関する重要な洞察をどのように提供できるかの例を見てみましょう。ここでは、少数のデバイスが12,000回を超える再起動を占めていることがわかります(図1)。
クリックしてフルサイズの画像を表示

図1:電源の問題の例、15日間の再起動のグラフ。 (出典:著者)
- 12Kデバイスが1日に再起動する– 多すぎる
- 再起動の99%は10台のデバイスによるものです
- デバイスの再起動が頻繁に発生する原因となる機械部品の不良
この場合、一部のデバイスは1日に1,000回再起動します。これは、機械的な問題(部品の不良、バッテリーの接触不良、またはさまざまな慢性的な速度の問題)が原因である可能性があります。
デバイスが本番環境に入ると、ファームウェアの更新を通じてこれらの問題の多くを処理できます。アップデートを公開することで、ハードウェアの欠陥を回避し、デバイスの回復と交換を試みる必要性を回避できます。
2番目の重点分野:ウォッチドッグ
接続されたスタックを操作する場合、ウォッチドッグは、デバイスを手動でリセットせずにシステムをクリーンな状態に戻すための最後の防衛線です。ハングは、次のような多くの理由で発生する可能性があります
- send()の接続スタックブロック
- 無限再試行ループ
- タスク間のデッドロック
- 破損
ハードウェアウォッチドッグはMCUの専用周辺機器であり、デバイスがリセットされないように定期的に「フィード」する必要があります。ソフトウェアウォッチドッグはファームウェアに実装され、ハードウェアウォッチドッグの前に起動して、ハードウェアウォッチドッグにつながるシステム状態のキャプチャを可能にします
ZephyrにはハードウェアウォッチドッグAPIがあり、すべてのMCUが汎用APIを経由して、プラットフォームでウォッチドッグをセットアップおよび構成できます。 (詳細については、Zephyr APIを参照してください:zephyr / include / drivers / watchdog.h)
// ... 無効 start_watchdog(void){ //使用可能なハードウェアウォッチドッグについてはデバイスツリーを参照してください s_wdt =device_get_binding(DT_LABEL(DT_INST(0、nordic_nrf_watchdog))); struct wdt_timeout_cfg wdt_config ={ / *ウォッチドッグタイマーの期限が切れたらSoCをリセットします。 * / .flags =WDT_FLAG_RESET_SOC、 / *最大ウィンドウの後にウォッチドッグを期限切れにする* / .window.min =0U、 .window.max =WDT_MAX_WINDOW、 }; s_wdt_channel_id =wdt_install_timeout(s_wdt、&wdt_config); const uint8_t options =WDT_OPT_PAUSE_HALTED_BY_DBG; wdt_setup(s_wdt、options); // TODO:ソフトウェアウォッチドッグを起動します } 無効 feed_watchdog(void){ wdt_feed(s_wdt、s_wdt_channel_id); // TODO:フィードソフトウェアウォッチドッグ } 北欧のnRF9160のこの例を使用して、いくつかの手順を見ていきましょう。
- デバイスツリーに移動して、NordicnRFウォッチタイムフォルダを設定します。
- 公開されたAPIを介してウォッチドッグの構成オプションを設定します。
- ウォッチドッグをインストールします。
- 動作が期待どおりに実行されている場合は、ウォッチドッグに定期的にフィードします。これは、優先度の最も低いタスクから実行される場合があります。システムがスタックしている場合は、再起動がトリガーされます。
ZephyrでMemfaultを使用すると、タイマー周辺機器を搭載したカーネルタイマーを利用できます。ソフトウェアウォッチドッグタイムアウトをハードウェアウォッチドッグよりも先に設定できます(たとえば、ハードウェアウォッチドッグを60秒に設定し、ソフトウェアウォッチドッグを50秒に設定します)。コールバックが呼び出されると、アサートがトリガーされ、Zephyrフォールトハンドラーを介して、システムがスタックしたその時点で何が起こっていたかに関する情報を取得します。
例:SPIドライバーがスタックしている
開発には含まれていないが、現場で発生している問題の例をもう一度見てみましょう。図2では、SPIドライバーチップのタイミング、事実、および劣化を確認できます。
クリックしてフルサイズの画像を表示
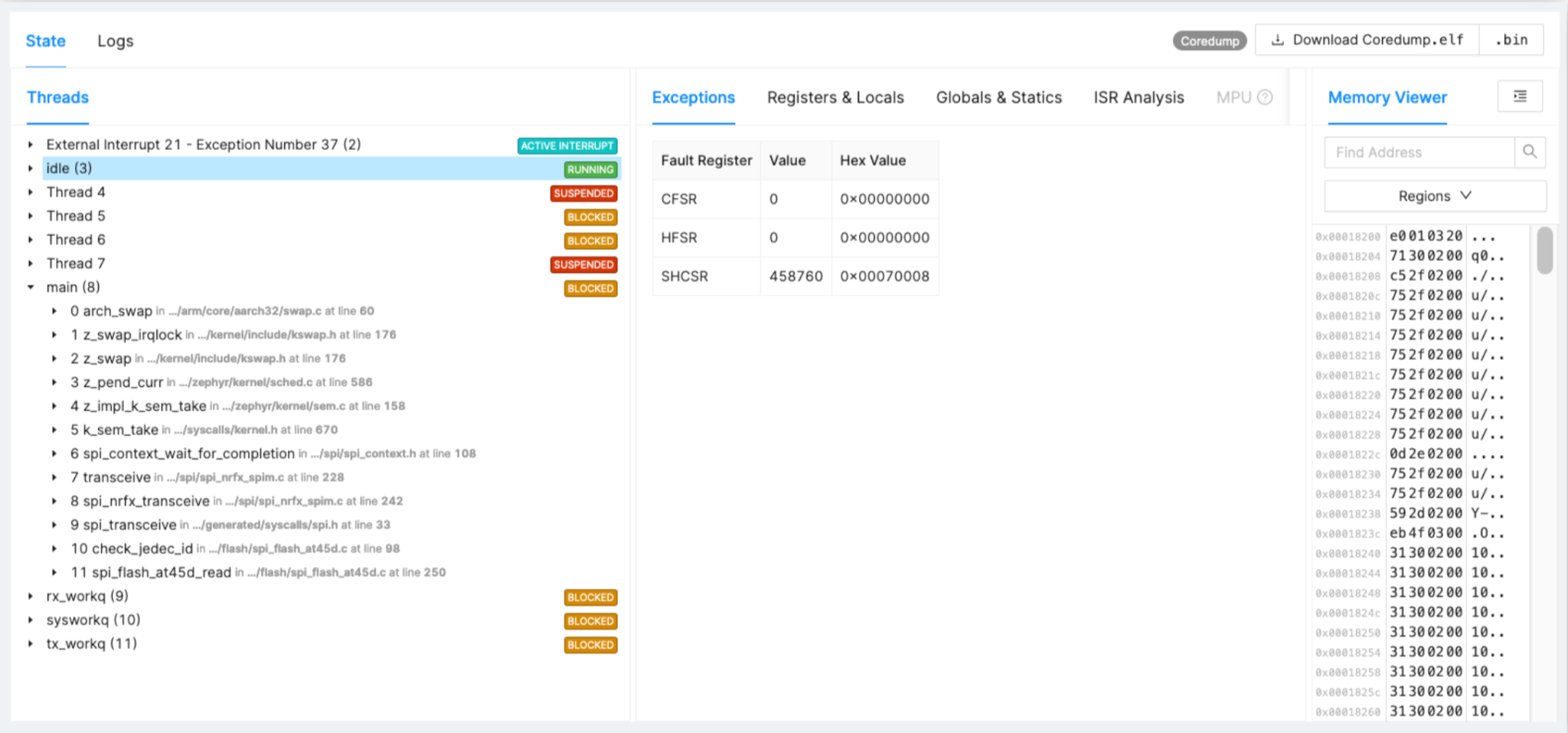
図2:SPIドライバーがスタックした例。 (出典:著者)
- SPIフラッシュが時間の経過とともに劣化し、通信のタイミングが正しくない
- 16か月のフィールド展開後、デバイスの1%でこれを追跡しました
- ドライバーの修正と次のリリースでの展開
Flashの場合、現場で1年経つと、SPIトランザクションやさまざまなコードの断片でスタックしたために、突然エラーが発生し始めたことがわかります。トレース全体を把握しておくと、根本的な原因を見つけて解決策を開発するのに役立ちます。
下のウォッチドッグ(図3)は、Zephyrフォールトハンドラーを開始しています。
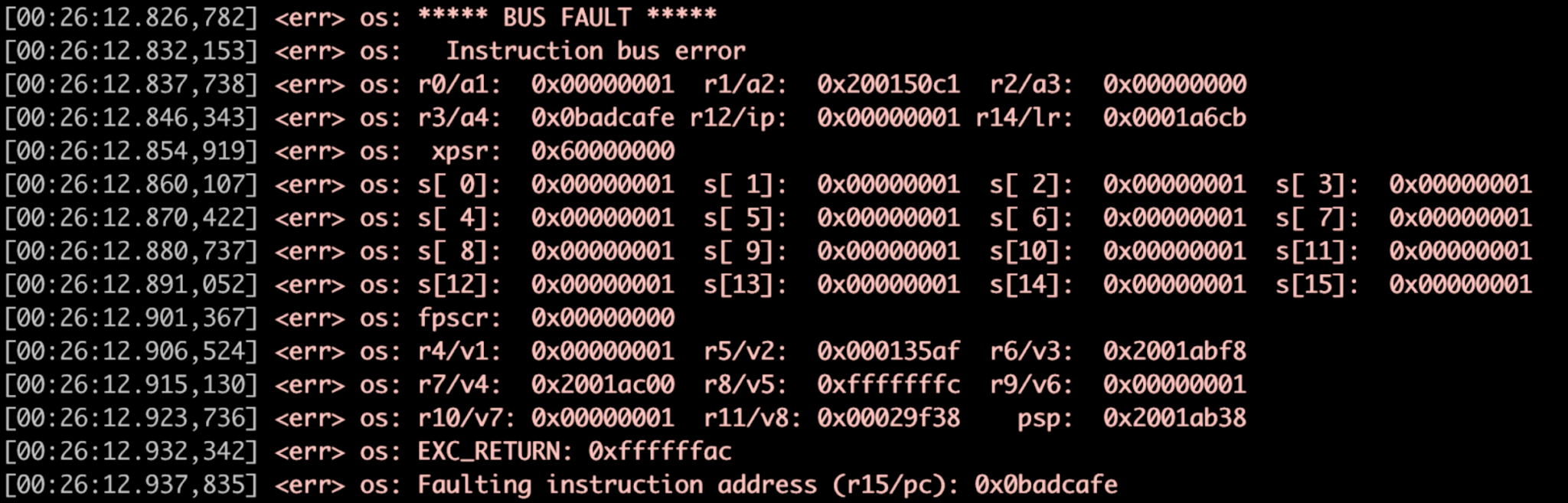
図3:フォールトハンドラーの例、レジスタダンプ。 (出典:著者)
3番目の領域の焦点:障害/アサート:
追跡する3番目のコンポーネントは、障害とアサートです。ローカルデバッグを行ったり、独自の機能を構築したことがある場合は、プラットフォームで障害が発生したときのレジスタの状態について同様の画面が表示される可能性があります。これらの原因は次のとおりです。
- アサート、または
- 不良メモリへのアクセス
- ゼロ除算
- 周辺機器を間違った方法で使用する
ZephyrのCortexMマイクロコントローラーで採用されている障害処理フローの例を次に示します。
void network_send(void){ const size_t packet_size =1500; void * buffer =z_malloc(packet_size); // NULLチェックがありません! memcpy(buffer、0x0、packet_size); // ... } ↓ void network_send(void){ const size_t packet_size =1500; void * buffer =z_malloc(packet_size); // NULLチェックがありません! memcpy(buffer、0x0、packet_size); // ... } ↓ブール memfault_coredump_save(const sMemfaultCoredumpSaveInfo * save_info){ //レジスタの状態を保存 // _ kernelとタスクのコンテキストを保存する //選択した.bssおよび.dataリージョンを保存 } ↓ void sys_arch_reboot(int type){ // ... } アサートまたはフォールトが開始されると、割り込みが発生し、クラッシュ時のレジスタ状態を提供するフォールトハンドラーがZephyrで呼び出されます。
Memfault SDKは、障害処理フローに自動的に組み込まれ、レジスタの状態、カーネルの状態、クラッシュ時にシステムで実行されていたすべてのタスクの一部など、重要な情報をクラウドに保存します。
ローカルまたはリモートでデバッグする場合は、次の3つを探す必要があります。
- Cortex M障害ステータスレジスタは、プラットフォームがアサートまたは障害を起こした理由を示します。
- Memfaultは、クラッシュ前にシステムが実行していたコードの正確な行と、他のすべてのタスクの状態を回復します。
- _kernel を収集します Zephyr RTOSで構造化して、スケジューラーを確認します。接続されているアプリケーションの場合は、BluetoothまたはLTEパラメーターの状態を確認します。
4番目の重点分野:デバイスの可観測性に関する指標の追跡
指標を追跡することで、システムで起こっていることのパターンの構築を開始し、デバイスとフリート全体を比較して、どのような変更が影響を及ぼしているかを理解できます。
追跡に役立ついくつかの指標は次のとおりです。
- CPU使用率
- 接続パラメータ
- 熱の使用
Memfault SDKを使用すると、2行のコードでZephyrにメトリックを追加して定義を開始できます。
- 指標を定義する
MEMFAULT_METRICS_KEY_DEFINE( LteDisconnect、 kMemfaultMetricType_Unsigned)
- コードの指標を更新
void lte_disconnect(void){ memfault_metrics_heartbeat_add( MEMFAULT_METRICS_KEY(LteDisconnect)、1); // ... } Memfault SDK +クラウド
- トランスポートのメトリックをシリアル化および圧縮します
- デバイスおよびファームウェアバージョンごとのインデックスメトリック
- デバイスごとおよびフリート全体で指標を閲覧するためのウェブインターフェースを公開します
デバイスとファームウェアのバージョンごとに、数十のメトリックを収集してインデックスを作成できます。いくつかの例:
- NB-IoT / LTE-Mの基本的な接続: 接続または接続することにより、モデムがバッテリー寿命にどのように影響するかを確認します。
- NB-IoT / LTE-Mでの基地局とPSMの追跡: モバイルの信号品質は苦痛を伴う可能性があり、管理されていない場合はバッテリーの寿命を縮める可能性があります。ネットワークステータス、イベント、セルタワー情報、設定、タイマーなどのメトリックを作成します。変更を監視し、アラートを使用します。
- 大型艦隊のテスト: 予想外に大きなデータは、デバイスの接続コストを増加させ、外れ値を特定するのに役立ちます。
例:NB-IoT / LTE-Mデータサイズ
クリックしてフルサイズの画像を表示
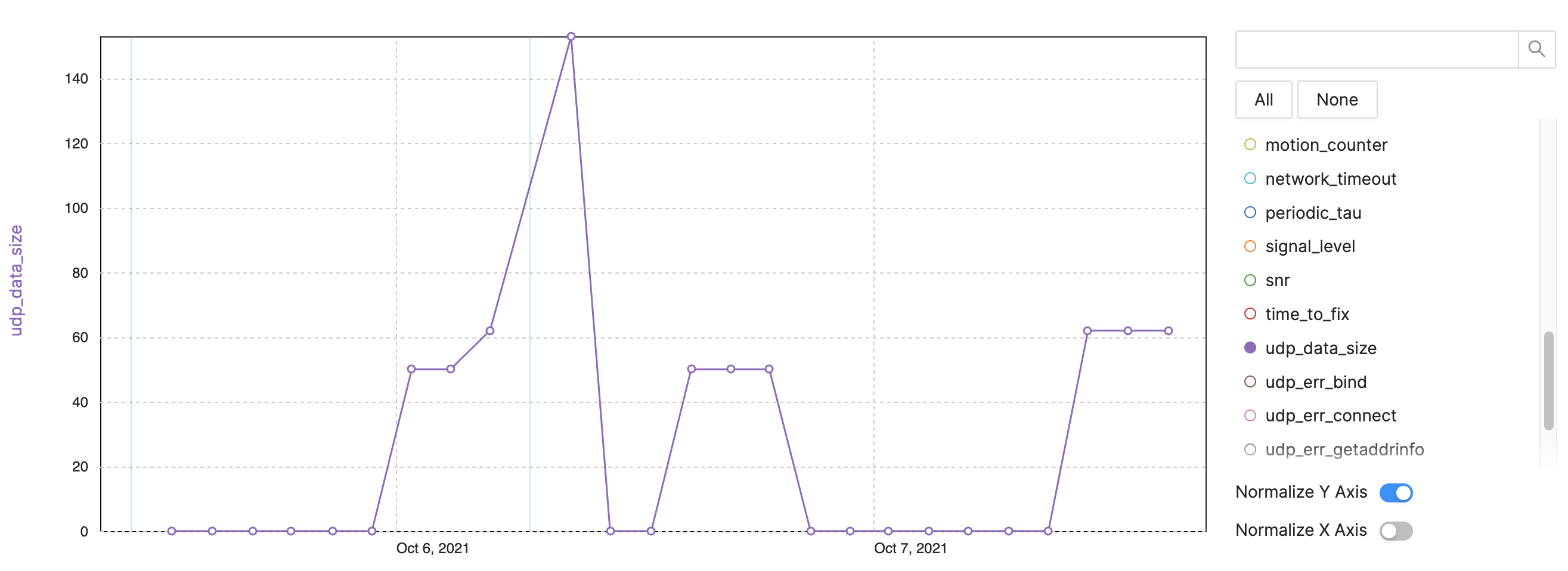
図4:デバイスの可観測性の追跡指標– NB-IoTの例、LTE-Mデータサイズ。 (出典:著者)
- UDPデータサイズ:送信間隔ごとのトラックバイト(図4)
- 再起動後、より多くのデータが送信されます
- 一部のパケットは、より多くの情報またはトレースのために大きくなっています
- データ消費の問題を追跡する
結論
ZephyrとMemfaultを活用することで、開発者はリモートモニタリングを実装して、接続されたデバイスの機能の可観測性を向上させることができます。再起動、ウォッチドッグ、障害/アサート、接続メトリックに焦点を当てることで、開発者はIoTシステムのコストとパフォーマンスを最適化できます。
2021 Zephyr DeveloperSummitの記録されたプレゼンテーションを見て詳細をご覧ください。
モノのインターネットテクノロジー
- 合成モニタリングのベストプラクティス
- フォグコンピューティングのベストセキュリティプラクティス
- サービスプロバイダーおよびIoTアプリケーション向けの1G双方向トランシーバー
- ETSIは緊急通信におけるIoTアプリケーションの基準を設定するために動きます
- IICとTIoTAがIoT/ブロックチェーンのベストプラクティスで協力
- NISTは、IoTメーカー向けのセキュリティに関する推奨事項のドラフトを公開しています
- パートナーシップは無限のIoTデバイスのバッテリー寿命を目指しています
- 資産管理にIoTテクノロジーを使用する3つの理由
- IoTを環境モニタリングに最適なプラットフォームと考える理由
- 圧縮空気システムに最適なアプリケーション
- 2019 年の製造マーケティングのベスト プラクティス