


深層学習に基づくスプリットリング共振器を備えたメタマテリアルの予測ネットワーク
要約
「メタマテリアル」の導入は、電磁気学を含むいくつかの分野に大きな影響を与えました。ただし、メタマテリアルの構造をオンデマンドで設計することは、依然として非常に時間のかかるプロセスです。効率的な機械学習手法として、近年、データの分類と回帰にディープラーニングが広く使用されており、実際に優れた一般化パフォーマンスが示されています。オンデマンド設計のための深いニューラルネットワークを構築しました。必要な反射率を入力として使用すると、構造のパラメータが自動的に計算されてから出力され、オンデマンドで設計する目的を達成します。私たちのネットワークは、トレーニングセットとテストセットの両方で0.005のMSEで、低い平均二乗誤差(MSE)を達成しました。結果は、深層学習を使用してデータをトレーニングすることで、トレーニングされたモデルが構造の設計をより正確にガイドできることを示しています。これにより、設計プロセスが高速化されます。従来の設計プロセスと比較して、メタマテリアルの設計をガイドするためにディープラーニングを使用すると、より速く、より正確で、より便利な目的を達成できます。
はじめに
ナノ光学は、ナノテクノロジーと光学の学際的な主題です。近年、入射光との特別な相互作用を実現するために、さまざまなサブ波長サイズの構造を絶えず設計することにより、科学者は光の特定の透過特性を操作することに成功しました[1,2,3]。メタマテリアルが提案されて以来、この分野の多くの学者の注目を集めており、同時に関連する理論的研究[4、5]、プロセス[6、7]、応用[8]の研究はすべて同じ速度で進んでいます。ホログラフィックイメージング、完全吸収[9]、フラットレンズ[10]など、多くの特有の機能が実現されています。テラヘルツ技術の急速な発展とその独特の特性により、近年、メタマテリアルの分野でも人気のある研究トピックになっています[11、12、13]。
メタマテリアルの用途は非常に広いですが、従来の設計方法では、設計者は設計対象の構造に対して複雑な数値計算を繰り返し実行する必要があります。このプロセスは、膨大な時間とコンピューティングリソースを消費します。したがって、従来の設計手法を簡素化または置き換える新しい方法を見つけることが急務です。
機械学習は学際的な分野として、ライフサイエンス、コンピューターサイエンス、心理学などの多くの分野をカバーしており、コンピューターを使用して人間の学習プロセスを模倣および実装し、新しい知識やスキルを習得するために取り組んできました。機械学習の基本原理は、コンピューターアルゴリズムを使用して、大量のデータ間の相関関係を取得したり、類似したデータ間のルールを予測したりして、最終的に分類または回帰の目的を達成することとして簡単に説明できます。これまで、多くの機械学習アルゴリズムがメタマテリアルの指定に適用され、遺伝的アルゴリズム[14]、線形回帰アルゴリズム[15]、浅いニューラルネットワークなどの重要な結果を達成してきました。構造がますます複雑になり、構造の変化が多様化するにつれて、問題の解決にはより多くの時間が必要になります。同時に、問題の非線形性が高いため、単純な機械学習アルゴリズムで正確な予測を取得することは困難です。さらに、特定の電磁効果に一致するメタマテリアル構造を設計するには、設計者が構造に対して複雑な数値計算を実行する必要があります。これらのプロセスは、膨大な時間とコンピューティングリソースを消費します。
機械学習の分野で最も優れたアルゴリズムの1つとして、ディープラーニングは、コンピュータービジョン[16]、特徴抽出[17]、自然言語処理[18]などのさまざまな関連分野で世界的に有名な成果を上げてきました。同時に、ライフサイエンス、化学[19]、物理学[20] [21]などの多くの基本的な分野を含む、他のコンピュータに関連しない分野での成功は数多くあります。したがって、メタマテリアルの設計にディープラーニングを適用することも現在のホットな研究の方向性であり、多くの優れた作品が登場しています[22、23、24]。
深層学習に着想を得て、この論文では、深層ニューラルネットワークに基づく機械学習アルゴリズムを使用してスプリットリング共振器(SRR)の構造を予測し、オンデマンドで設計するという目的を達成する研究について報告します。さらに、順方向ネットワークと逆方向ネットワークは別々に革新的にトレーニングされているため、ネットワークの精度が向上するだけでなく、柔軟な組み合わせによってさまざまな機能を実現できます。結果は、このメソッドがトレーニングセットと検証セットでそれぞれ0.0058と0.0055のMSEを達成でき、優れた堅牢性と一般化を示していることを示しています。訓練されたモデルがメタマテリアル構造の設計をガイドすることで、設計サイクルを数日または数時間に短縮することができ、効率の向上は明らかです。さらに、この方法はスケーラビリティも優れており、トレーニングセットのデータを変更するだけで、さまざまな入力や構造をオンデマンドで設計できます。
理論と方法
COMSOLモデルの構築
ディープラーニングをメタマテリアル構造の逆設計に適用できることを示すために、金のリング、シリカの底、および金の底からなる3層のSRR構造をモデル化して、入射光。図1に示すように、開き角θ 金の指輪の内半径 r リングの幅、および線幅 d リングのは、この構造の独立変数として選択されます。直線偏光のビームがメタマテリアルに正常に入ると、構造変数を変更することにより、さまざまな構造での波長反射率曲線が得られます。 Auリングの厚さは、SiO 2 の底の30nmです。 は100nm、Auの底は50 nm、メタ原子のサイズは200 nm x 200nmです。
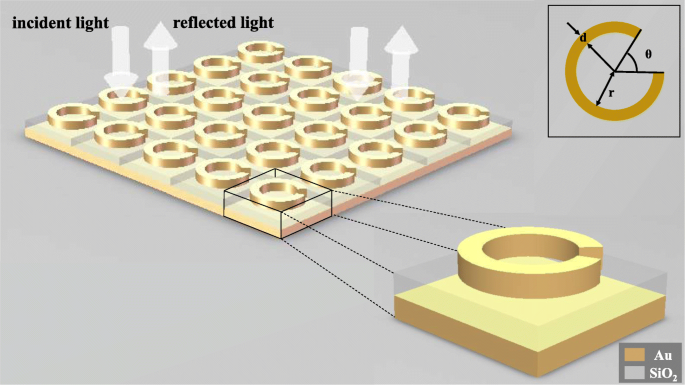
構造の概略図。メタ表面全体は、2方向に繰り返し配置されたメタ原子で構成されており、直線偏光はメタ表面に垂直に入射します。各メタ原子は、上から下に向かって、金の環、シリカの底、金の底で構成されています。最上部の金のリングには、3つの構造パラメータ、つまり線幅 d が含まれています。 、開き角θ 、および内輪半径 r
モデリングにはCOMSOLMultiphysics 5.4 [25]を使用し、3次元空間次元を選択し、物理フィールドに光学、波動光学、電磁波周波数領域(ewfd)を選択し、研究用に波長領域を選択します。上記のモデルをジオメトリで作成します。各部の材質と屈折率を順番に定め、電磁波周波数領域にポートと周期条件を追加します。
深層学習ニューラルネットワークモデルの構築
メタマテリアル構造のリバースネットワークとフォワードネットワークを構築しました。逆ネットワークは、異なる偏光方向を持つ2セットの波長反射率曲線からSRRの構造パラメータを予測できます。フォワードネットワークは、与えられた構造パラメータによって、2つの偏光方向の波長反射率曲線を予測できます。リバースネットワークの機能は、予測機能の本体です。順方向ネットワークの役割は、逆方向ネットワークの予測結果を検証して、予測結果が必要な電磁応答を満たしているかどうかを観察することです。
開発プラットフォームとしてeclipse2019、プログラミング言語としてpython3.7、開発フレームワークとしてTensorFlow1.12.0を使用してください。
2つのネットワークは別々にトレーニングされ、各ネットワークのトレーニング結果が他のネットワークのエラーの影響を受けないようにします。これにより、2つのネットワークのそれぞれの精度が保証されます。
図2に示すように、2つのネットワークを別々にトレーニングすることの別の利点は、異なる接続シーケンスを通じて異なる目的に使用できることです。(a)リバースネットワーク+フォワードネットワーク。特定の波長反射曲線を使用して、パラメータを構築し、予測を行い、予測結果がニーズを満たしているかどうかを検証します。(b)フォワードネットワークのみを使用すると、数値計算方法の計算プロセスを簡素化し、計算時間を短縮できます。
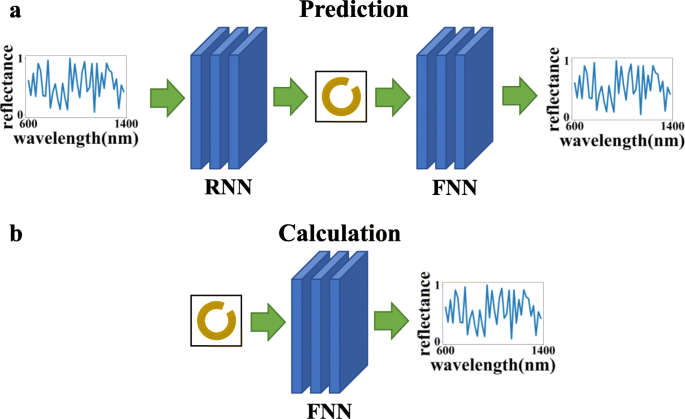
この図では、FNNは順方向ニューラルネットワークを指し、RNNは逆方向ニューラルネットワークを指します。上のグラフ( a )は、2つのネットワークを接続して予測と検証の効果を実現できることを示し、下のグラフ( b )は、順方向応答ネットワークのみを使用して光応答を計算できることを示します
ディープラーニングの方法を使用してトレーニング済みモデルの結果を入力および取得するプロセスは、非常に短時間で済むことは注目に値します。また、シミュレーションや実験を通じて新しいデータが取得された場合はいつでも、モデルを使用してさらにトレーニングを行うことができます。研究によると、トレーニングデータの継続的な増加に伴い、モデルの精度はますます高くなり、一般化のパフォーマンスはますます向上することが示されています[26]。
構造のパラメーターは、回帰問題に属する連続固有値の複数のセットです。近年、完全に接続されたネットワークは、回帰問題に関する深層学習ネットワークの焦点となっており、高い信頼性、大きなデータスループット、および低遅延の特性を示しています。完全に接続されたネットワークでいくつかの調整を行うと、ネットワークは構造をより適切に予測できるようになります。
図3bに示すように、フォワードネットワークは完全に接続されたネットワークであり、2つの隣接するレイヤーのすべてのノードが相互に接続されています。入力データは構造パラメータであり、出力は2つの偏光方向の波長-反射率曲線です。図3aに示すように、逆ネットワークは特徴抽出層(FE層)と完全に接続された層(FC層)で構成されます。 FE層には、相互に接続されていない2セットの完全に接続されたネットワークが含まれ、2方向の直線偏光の波長反射率曲線を処理して、入力データのいくつかの特徴を抽出します。 FC層は、抽出された特徴を学習し、構造パラメーターを出力します。異なる偏光状態での波長反射率曲線間の高い凝集度と低い結合度の特性により、異なる方向の2セットの偏光データの入力を分離することで、データ抽出プロセス中のデータ標準化によってネットワークが妨害されるのを防ぐことができます。フォワードネットワークは、複数の入力セットを必要とせず、データ間の相互干渉を考慮する必要がないため、特徴抽出レイヤーがありません。
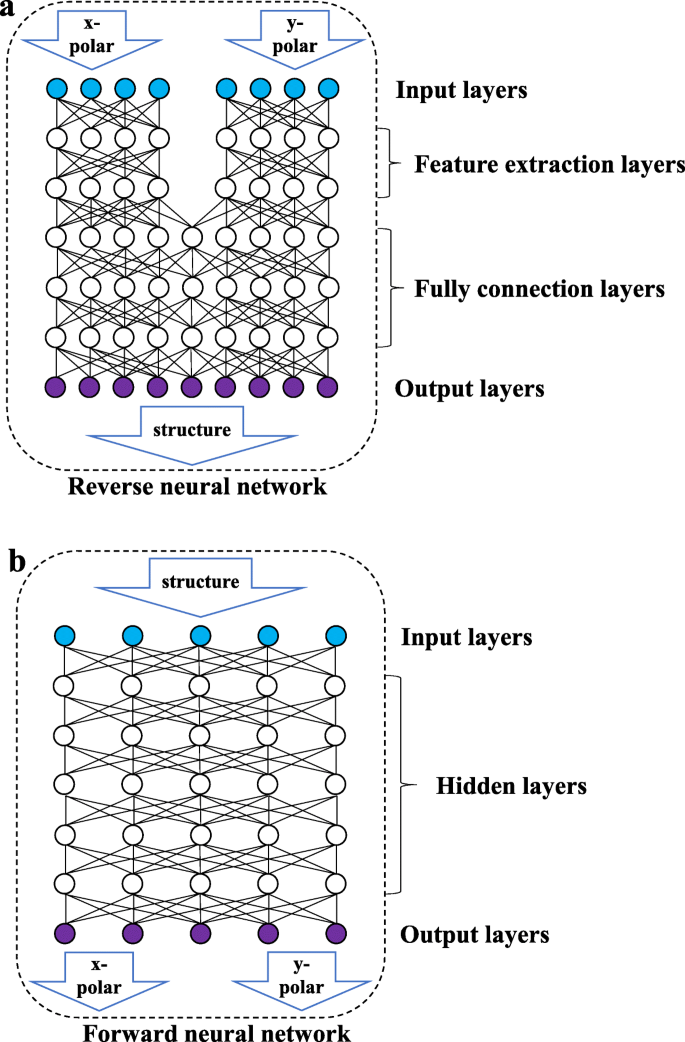
ネットワーク構造の概略図。上の図は、リバースネットワークを示しています。逆ネットワークは、入力層、特徴抽出層、完全に接続された層、および出力層で構成されます。次の図は、入力層、非表示層、および出力層で構成されるフォワードネットワークを示しています
最適なネットワーク構造を決定するために、異なる構造のネットワークが同じデータセットを使用してトレーニングされます。図4に示すように、データが50エポックを経験した後(すべてのデータが完全なトレーニングを受けた後、それはエポックと呼ばれます)、MSEはさまざまな構造のフォワードネットワークによって到達されます。図4の左の写真からわかるように、フォワードネットワークに5つの隠れ層があり、各レイヤーに100ノードが含まれている場合、達成されるMSEの最低値は約0.0174であるため、この構造のフォワードネットワークが選択されます。
>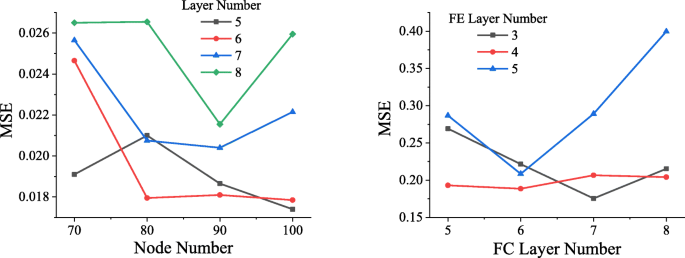
ネットワーク構造の比較。左の図で、横軸は各層のノード数、縦軸はMSE、黒、赤、青、緑は隠れ層に5、6、7、それぞれ8層。右の図で、横軸は完全に接続された層の層数を示し、縦軸はMSEを示し、黒、赤、青の線はFE層に3、4、5が含まれる場合の状況を示します。 、それぞれ
同様に、リバースネットワークのさまざまなネットワークがトレーニングされ、トレーニング量は50エポックに設定されました。結果を図4の右図に示します。FC層の数が7、FE層の数が3の場合、ネットワークは最低のMSEである約0.1756に達します。
ネットワーク層の数が多いと勾配爆発現象が発生し、ネットワークの収束に失敗し、損失が無限大になるため、図には示されていません。
データの前処理
より信頼性の高いフォワードネットワークをトレーニングするために、反射率データが再分割され、AuとSiO 2 の反射率でステッチされます。 各周波数に対応します。次に、照合されたデータは正規化されてフォワードネットワークに入力されます。これにより、フォワードネットワークの精度が大幅に向上します。
値が大きいデータが値が小さいデータよりもネットワークに大きな影響を与えないようにするには、データの各列が標準正規分布に準拠するように入力データを正規化する必要があります(平均値は0、分散は1)、次に処理されたデータ x 次のように表すことができます:
$$ x =\ frac {\ left({x} _0 \ hbox {-} \ mu \ right)} {\ sigma} $$(1)式では、 x 0 サンプルの元のデータ、μです。 サンプルの平均、およびσ サンプルの標準偏差。入力データを再分割しないと、正規化後に反射率が歪んでしまい、ネットワークの精度が低下します。再分割されたデータは、正規化のためにその分布に影響を与えません。
ニューラルネットワークメソッド
ニューラルネットワークの原理は、人間の脳が働き、学習する方法を模倣することによって、多くのニューロン(ノード)を構築することです[27]。ニューロンは相互に接続されており、接続の重みを調整することで出力が調整されます。 j の出力 レイヤーのノードは次のように表すことができます。
$$ {y} _j =\ frac {\ sum \ Limits_ {i =1} ^ nf \ left({w} _i {x} _i + {b} _j \ right)} {n} $$(2)f は活性化関数、 w i 前のレイヤーの i の接続の重みです j に接続されているノード thノード、 x i i の出力です 前のレイヤーの3番目のノード b j はこのノードのバイアス項であり、 n j に接続されている前のレイヤーのノードの数です thノード。
活性化関数の選択
逆問題の高い非線形性を満たすために、ELU関数[28]がニューロンの各層の活性化関数として使用されます[28]。出力 f ( x )のELU関数は、次のように区分的形式で表すことができます。
$$ f(x)=\ left \ {\ begin {array} {c} x \\ {} \ alpha \ left({e} ^ x-1 \ right)\ end {array} \ right。{\ displaystyle \ begin {array} {c}、\\ {}、\ end {array}} {\ displaystyle \ begin {array} {c} x \ ge 0 \\ {} x <0 \ end {array}} $$ (3)この関数では、 x は元の入力であり、αのパラメータ値です。 範囲は0〜1です。
活性化関数を使用する理由は、活性化関数がネットワークの各層の非線形表現能力を変更し、それによってネットワークの全体的な非線形フィッティング能力を向上させるためです。図5に示すように、ELU関数は、シグモイド関数と正規化線形ユニット(ReLU)の活性化関数の利点を組み合わせたものです。 x の場合 <0の場合、ソフトサチュレーションが向上し、入力の変化やノイズに対してネットワークがより堅牢になります。 x の場合> 0の場合、飽和はありません。これは、ネットワークの勾配の消失を軽減するのに役立ちます。 ELUの平均値が1に近いという特徴により、ネットワークの適合が容易になります。この結果は、深層学習の活性化関数としてELUを使用することで、ニューラルネットワークがネットワークの堅牢性を大幅に向上させることを証明しています。
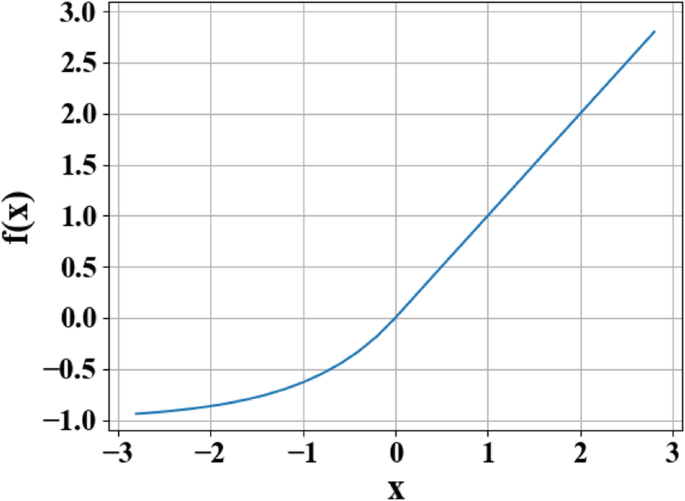
指数線形単位(ELU)関数曲線。図では、 x 元の入力を表し、 f ( x )は関数出力を表します
重みの初期化スキーム
各層のネットワーク重みの初期化方法は、ネットワーク適合の速度を決定し、ネットワークが適合できるかどうかさえ決定します。分散スケーリングの初期化は、各レイヤーでの入力データの量に基づいており、0を中心とする切断正規分布から重みを抽出するため、分散を特定の範囲に減らすことができ、データをネットワーク全体にさらに広げることができます[29 ]。このネットワーク構造では、分散スケーリングの初期化を使用すると、ネットワークの収束速度を大幅に高速化できます。
過剰適合ソリューション
データが不十分なため、ネットワークによって過剰適合が発生します。過剰適合を減らすことで、ネットワークはトレーニングセット外のデータに対して優れた一般化パフォーマンスを発揮できます。 L2正則化(回帰問題では重み減衰とも呼ばれます)は、重み w を処理するために使用されます。 。正則化された出力 L 次のように表すことができます:
$$ L ={L} _0 + \ frac {\ lambda} {2n} \ sum {w} ^ 2 $$(4)式で。 (4)、 L 0 元の損失関数を表し、正則化項\(\ frac {\ lambda} {2n} \ sum {w} ^ 2 \)がこれに基づいて追加されます。ここでλ 正則化係数 n を表します データスループット、および w 重量。正則化項が追加された後、重みの値 w 全体的に減少する傾向があり、過剰な値の発生を回避できるため、 w 重量減衰とも呼ばれます。 L2正則化は、重みを減らして近似曲線の大きな勾配を回避し、それによってネットワークの過剰適合現象を効果的に軽減し、収束を支援します。
これに基づいて、ドロップアウト方式も使用されます。この方法は、複数の「部分ネットワーク」をトレーニングするという目標を達成するために、各トレーニングで特定の規模のネットワークノードを「非表示」にし、各トレーニング中にさまざまなノードを非表示にすることと視覚的に見なすことができます。また、トレーニングを通じて、ほとんどの「部分ネットワーク」はターゲットを正確に表すことができ、すべての「部分ネットワーク」の結果を並べ替えて、ターゲットのソリューションを取得できます。
上記のL2正則化とドロップアウトの方法を使用すると、不十分なデータによって引き起こされる一般化の低さを効果的に軽減できるだけでなく、データセット内の少量の誤ったデータがトレーニング結果に与える影響を減らすことができます。
このネットワーク構造とデータセットで、ドロップアウト=0.2、L2正則化係数λ =0.0001の場合、ネットワークはトレーニングセットとテストセットで同様の精度を取得できるため、高い一般化パフォーマンスを実現できます。
結果と考察
トレーニング後、フォワードネットワークはMSE 0.0015で高度なフィッティングを実現できます。これは、図6に示すように、出力がシミュレーション結果と非常に類似していることを示しています。これにより、リバースネットワークをトレーニングするときにリバースネットワークの結果は確実に検証できます。
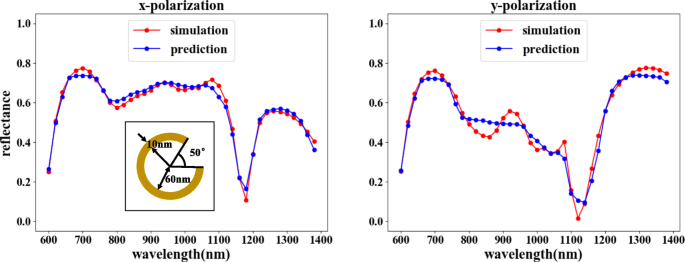
フォワードネットワークトレーニングの結果。対応する構造パラメータはθです =50°、 r =60 nm、および d =10nm。図中、横軸は入射光の波長、縦軸は反射率、赤線はCOMSOLシミュレーション結果、青線はネットワークトレーニング結果を表しています。左の図は、 x に対応する反射率曲線を示しています。 -偏光入力。右の図は、 y に対応する反射率曲線を示しています。 -偏波入力
最後に、学習したネットワークから2つのモデルを生成し、2つのモデルを接続して、予測機能を実現します。
予測関数は、図2aに示す組み合わせを選択できます。リバースネットワークは必要な波長反射率曲線に従って対応する構造を予測し、フォワードネットワークは構造の光学応答を検証します。図7に示すように、検証された反射率を入力反射率と比較することにより、2つの偏光方向の入射光の反射特性は基本的に一貫しています。特定の波長値ではわずかな反射率の不一致が見られますが、誤差が許容範囲内にあるため、全体的な一致傾向は明らかに反駁できません。
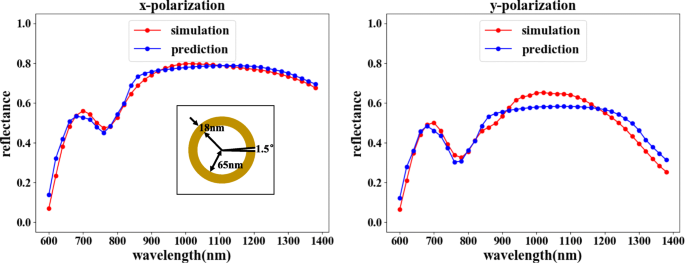
逆方向ネットワークとそれに続く順方向ネットワークは、予測の目的を達成できます。図中、横軸は入射光の波長、縦軸は反射率、赤線はCOMSOLシミュレーション結果、青線はネットワークトレーニング結果を表しています。左の図は、 x に対応する反射率曲線を示しています。 -偏光入力。右の図は、 y に対応する反射率曲線を示しています。 -偏波入力。入力波長反射率曲線の予測結果はθです。 =1.5°、 r =65 nm、および d =18 nm
結論
この記事では、ネットワーク構成の柔軟な組み合わせを採用することでさまざまな効果を生み出すことができる、設計されたディープラーニングネットワークを紹介しました。設計されたリバースネットワークは、入力波長屈折曲線を使用して必要な構造を予測できます。これにより、リバース問題の解決に必要な時間を大幅に短縮し、柔軟な組み合わせを利用してさまざまなニーズに対応できます。この結果は、ネットワークが予測の精度を高めたことを示しています。これは、オンデマンド設計が私たちの方法で解決できることをさらに意味します。ディープラーニングを使用してメタマテリアルの設計をガイドすると、より正確なメタマテリアル構造を自動的に取得できます。これは、従来の設計方法では達成できない結果です。
データと資料の可用性
原稿がシミュレーションネットワークからのものであり、個人的な理由により共有できません。
略語
- ELU:
-
指数線形単位
- FCレイヤー:
-
完全に接続されたレイヤー
- FEレイヤー:
-
特徴抽出レイヤー
- FNN:
-
フォワードニューラルネットワーク
- MSE:
-
平均二乗誤差
- ReLU:
-
正規化線形ユニット
- RNN:
-
逆ニューラルネットワーク
- SRR:
-
スプリットリング共振器
ナノマテリアル
- ディープラーニングにFPGAを活用
- 自動車用プロセッサーは統合されたAIアクセラレーターを備えています
- PiCameraによるAI数字認識
- 視覚ベースの障害物回避を備えた移動ロボット
- 機械学習による資産パフォーマンスの改善
- 人工ニューロンによる教師なし学習
- WNDはSigfoxと提携して、英国にIoTネットワークを提供しています
- Java の Split() String メソッド:例を使用して文字列を分割する方法
- グラファイトナノプレートレットを備えた多層カーボンナノチューブに基づくハイブリッド複合材料の電気的性質
- スーパーキャパシターの電極材料としての階層的多孔質構造を持つ単分散カーボンナノスフェア
- 機械学習でバッテリーの寿命を予測する