


初心者向けの機械学習とその 4 つの主要なタイプに関するキーノート
ビッグデータが将来の技術開発の主要部分であることは間違いありません。ただし、機械学習 (ML) と人工知能 (A.I) はどちらも、この開発において重要な役割を果たします。これら 3 つの関係を簡単に説明します。ビッグデータは材料、機械学習は方法、人工知能は結果です。
機械学習とは?
機械学習 (ML) は、人工知能 (A.I) の一種であり、明示的にプログラムしなくても、経験を通じて自動的に学習、適応、改善する能力がシステムに与えられるようにアルゴリズムが記述されています。 .
機械学習アルゴリズムは、学習対象のデータの種類に基づいた模範的なモデルを構築します。この種類のデータは「トレーニング データ」と呼ばれます。
機械学習の種類?
機械学習アルゴリズムにはさまざまな種類があり、一般的に 4 つのカテゴリに分類できます。さまざまな種類の機械学習は次のとおりです。-
<ウル>
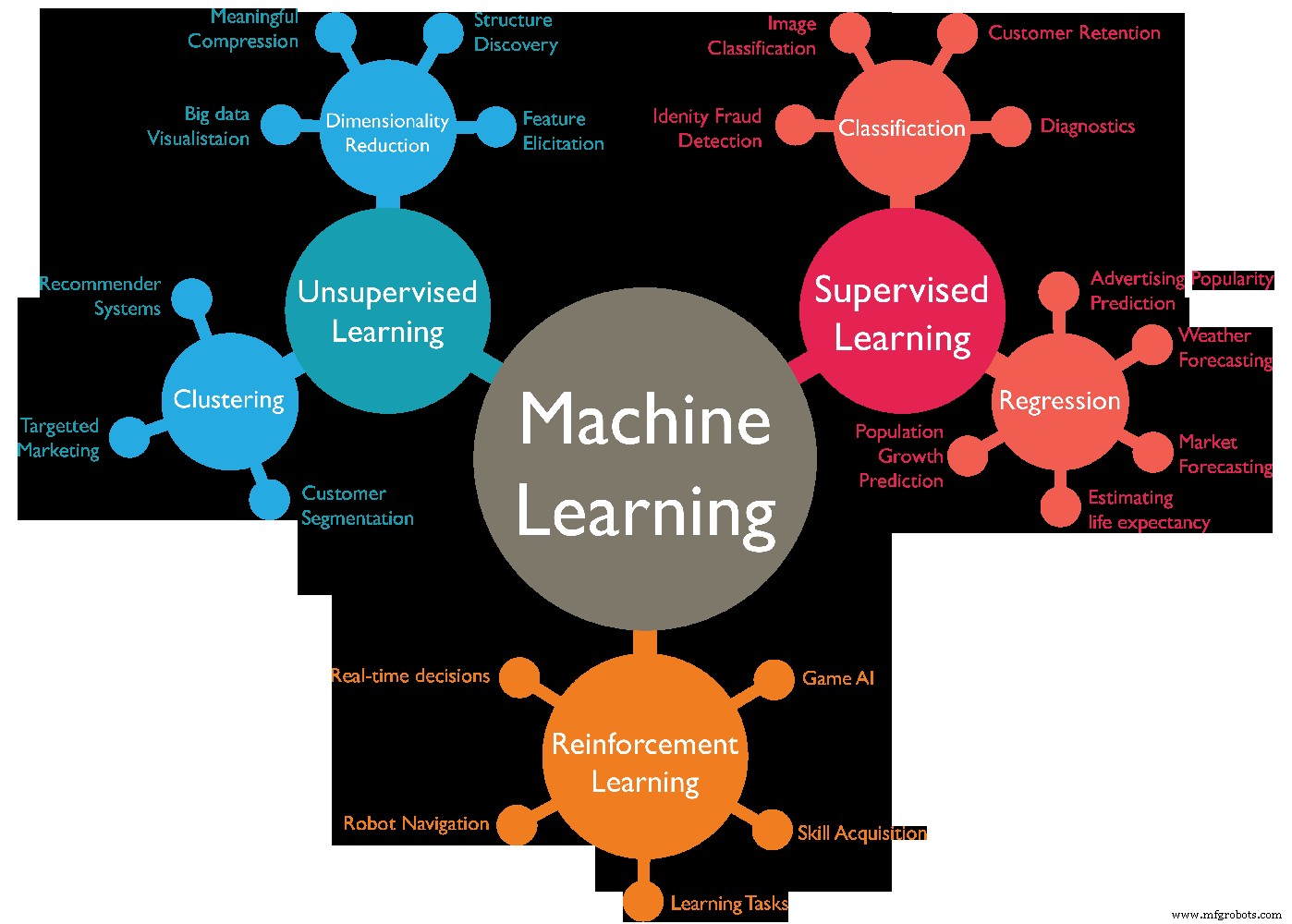
教師あり学習
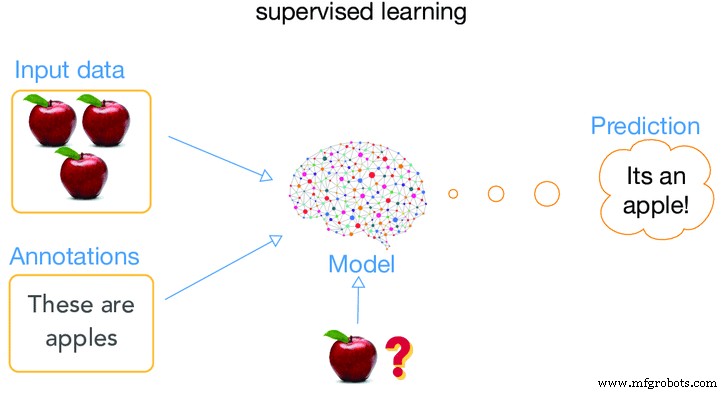
機械が「学習」段階にあるときに監視されている場合、このタイプのトレーニングは教師あり学習と呼ばれます。機械が監視されているとはどういう意味ですか ?.マシンが古いデータ (過去に提供されたデータ) を使用することを学習し、それを使用して、入力されたデータの種類、つまり古いデータを取り巻く将来のイベントを予測できるように、アルゴリズムを適用することが実際に意味すること.
分析が開始され、正しい出力値を予測できるように、トレーニング データセット内のラベル付けされたすべてのマテリアルがマシンと関連付けられます。これは、特定のケースに関する多くの情報をマシンに提供し、ケースの結果を提供することを意味します。結果はラベル付きデータと呼ばれ、残りの情報は入力機能として使用されます。システムは、十分なトレーニングの後、新しい入力のターゲットを提供することもできます。アルゴリズムは、その出力を意図した出力と比較し、違いを見つけてそれに応じてモデルを変更できます。
画像提供人工知能.oodles.io/
ほとんどの場合、この方法は手作業による分類です。これは、コンピュータにとって最も簡単で、人間にとって最も難しい方法です。この方法の例として、マシンに標準的な回答を伝える方法があります。マシンがテストされると、マシンは常に標準的な回答に従って応答するため、信頼性も高くなります。
教師なし学習
教師あり学習とは対照的に、教師なし学習アルゴリズムは、マシンのトレーニングに使用される情報が分類もラベル付けもされていない場合に使用されます。教師なし学習では、その名前が示すように、ユーザーからコンピューターにヘルプが提供されません。
提供された資料にはラベルがなく、機械がデータの特性を照合して資料を分類します。ラベル付けされたトレーニング セットが不足しているため、機械は、人間にはそれほど明白ではないデータ内のパターンを識別します。
image Courtesy data-flair.training/この方法では、人間にとって最も簡単な手動分類はありませんが、コンピューターにとっては最も困難であり、はるかに多くのエラーを引き起こす可能性があります.システムはほとんどの場合、意図した出力を把握しませんが、提供されたデータを調査し、データセットから関係を引き出して、ラベルのないデータから隠された構造を説明できます。したがって、データの教師なし学習のパターンを認識することは非常に有用であり、意思決定にも役立ちます。
半教師あり学習
半教師あり学習は、データのすべての観察に対してラベルが存在しないか、ラベルが存在する教師あり学習および教師なし学習とは異なります。
半教師ありでは、ラベル付き (教師あり) データとラベルなし (教師なし) データの両方がトレーニングに使用されます。 SSL は、少量のデータがラベル付けされ、大量のデータがラベル付けされていないという 2 種類の学習を組み合わせたものです。マシンは、ラベル付けされたデータから特徴を見つけ、基本モデルを使用して、それに応じて他のデータを分類する必要があります。 SSL システムは、学習精度を大幅に向上させるだけでなく、より正確な予測を行うこともできます。
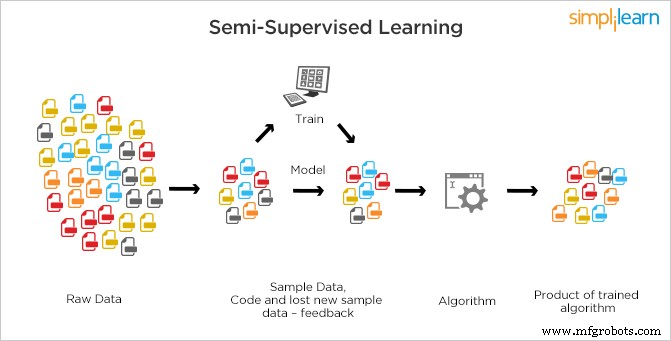
熟練した人間の専門家が必要なため、ラベル付けのコストが高くなるため、最も一般的に使用される方法です。ラベル付けされていないデータの取得には通常、追加のリソースは必要ありませんが、トレーニングしてそこから学習するには関連するリソースが必要です。観測の大部分にラベルがないため、半教師ありアルゴリズムがいくつか存在するため、モデルを構築するための最良の候補として優先されます。
これらのメソッドは、ラベル付けされていないデータがより一般的であるため、グループのメンバーが不明であっても、パラメーターに関する情報はラベル付けされたデータで保持され、それを使用して見つけることができるという考えから恩恵を受けます。
強化学習
強化学習は、人間の学習方法に最も近いものです。 RML アルゴリズムは、マシンが新しいアクションを構築することで環境と繰り返し対話し、エラーや報酬を発見する学習方法です。正または負の報酬ベースのシステムを使用します。
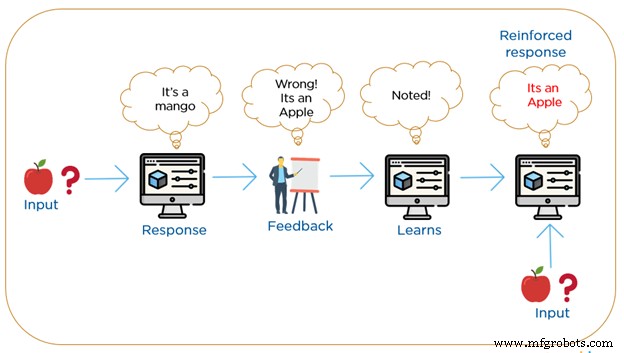
遅延報酬を伴う試行錯誤検索は、強化学習の最も重要な特徴です。機械は、環境との相互作用から収集された観察を使用して行動を構築し、報酬を最大化またはリスクを最小化するアクションを実行します。この方法により、マシンは特定のコンテキスト内で理想的な動作を自動的に決定して、パフォーマンスを向上させることができます。強化学習では、ラベル付けされた資料はありませんが、代わりに、どのステップが正しく、そのステップが間違っているかという単純なフィードバックが必要です。これは強化シグナルとして知られています。

フィードバックの基準に従って、最終的に正しい結果が得られるまで、機械は徐々に分類を修正します。教師なし学習で一定レベルの精度を達成するには、強化学習の統合が必要です。
ビジネス環境で RML を作成して実行するのはおそらく最も難しいですが、自動運転車では一般的に使用されています。
産業技術