


i.MX RT1060 CrossoverMCUを使用してTensorFlowLiteで数字認識を実装する方法
この記事では、MNIST eIQを例として使用した数字の検出と認識について説明します。これは、いくつかの部分で構成されています。数字の認識は、TensorFlowLiteモデルによって実行されます。 、およびGUIを使用して、i.MXRT1060デバイスの使いやすさを向上させます。
i.MX RT1060クロスオーバーMCUは、費用効果の高い産業用アプリケーションや、ディスプレイ機能を必要とする高性能でデータ集約型の消費者向け製品にも同様に適しています。この記事では、ユーザーの手書き入力を検出して分類できる組み込み機械学習アプリケーションを実装する方法を説明することにより、このArm®Cortex®-M7ベースのMCUの機能を示します。
そのために、この記事では、いくつかの部分で構成される人気のあるMNIST eIQの例に焦点を当てます。数字の認識は、TensorFlow Liteモデルによって実行され、GUIを使用してi.MXRT1060デバイスの使いやすさを向上させます。
MNISTデータセットとモデルの概要
この記事全体で使用されるデータセットは、手書き数字の中央に配置されたグレースケール画像の60,000のトレーニングと10,000のテスト例で構成されています。各サンプルの解像度は28x28ピクセルです:

図1。 MNISTデータセットの例
サンプルは、米国の高校生と国勢調査局の従業員から収集されました。したがって、データセットには、北米で書かれている数字の例がほとんど含まれています。たとえば、ヨーロッパスタイルの数値の場合、別のデータセットを使用する必要があります。畳み込みニューラルネットワークは通常、このデータセットで使用すると最良の結果をもたらし、単純なネットワークでも高精度を達成できます。したがって、TensorFlowLiteはこのタスクに適したオプションでした。
この記事で選択したMNISTモデルの実装は、公式のTensorFlowモデルの1つとしてGitHubで入手でき、Pythonで記述されています。このスクリプトは、Kerasライブラリとtf.data、tf.estimator.Estimator、およびtf.layers APIを使用し、テストサンプルで高精度を実現できる畳み込みニューラルネットワークを構築します。
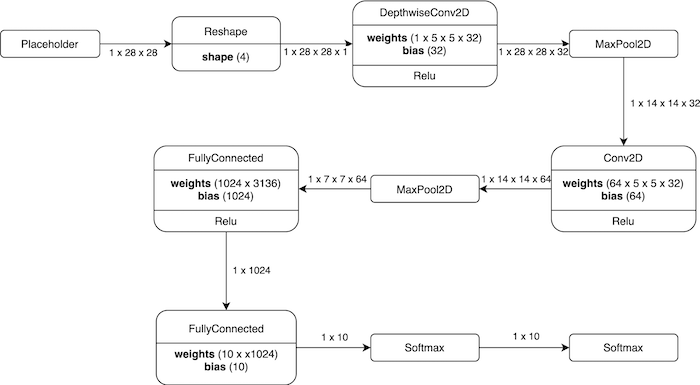
図2。 使用されたモデルの視覚化。
対応するモデル定義を以下の図3に示します。
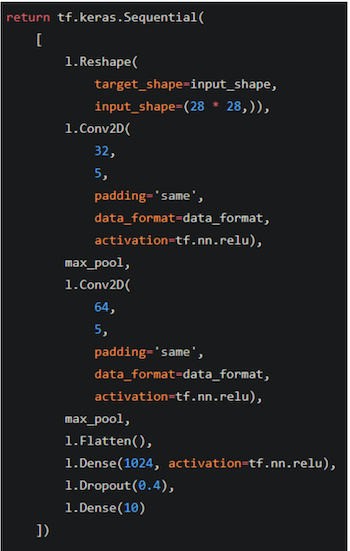
図3。 モデルの視覚化に対応するモデル定義。
TensorFlow Liteとは何ですか?この例ではどのように使用されますか?
TensorFlowは、大企業の本番環境で広く使用されている有名なディープラーニングフレームワークです。これは、Googleによって開発および保守されている、オープンソースのクロスプラットフォームのディープラーニングライブラリです。経験豊富な開発者に役立つ低レベルのPythonAPIと、この場合に使用されるような高レベルのライブラリが利用可能です。さらに、TensorFlowは、大規模なコミュニティと優れたオンラインドキュメント、学習リソース、ガイド、Googleの例によってサポートされています。
モバイルデバイスや組み込みソリューションなどの計算が制限されたマシンにTensorFlowアプリケーションを実行する機能を提供するために、GoogleはTensorFlowフレームワークの完全な操作セットをサポートしないTensorFlowLiteフレームワークを開発しました。このようなデバイスは、TensorFlowLiteに変換された事前トレーニング済みのTensorFlowモデルで推論を実行できます。見返りとして、これらの変換されたモデルはこれ以上トレーニングできませんが、量子化や剪定などの手法で最適化できます。
モデルをTensorFlowLiteに変換する
上記で説明したトレーニング済みのTensorFlowモデルは、i.MX RT1060MCUで使用する前にTensorFlowLiteに変換する必要があります。そのために、tflite_convertを使用して変換されました。互換性の理由から、モデルのトレーニングと変換にはバージョン1.13.2のTensorFlowが使用されました。
tflite_convert
--saved_model_dir =
<コード>-output_file =Converted_model.tflite
--input_shape =1,28,28
--input_array =Placeholder
--output_array =Softmax
--inference_type =FLOAT
--input_data_type =FLOAT
--post_training_quantize
<コード>-target_ops TFLITE_BUILTINS
最後に、xddユーティリティを使用して、TensorFlow Liteモデルをバイナリ配列に変換し、アプリケーションでロードしました。
xxd -i Converted_model.tflite> Converted_model.h
xddは、ファイルのバイナリ形式を対応する16進ダンプ表現に、またはその逆に変換するために使用できる16進ダンプユーティリティです。この場合、TensorFlowLiteバイナリファイルは、eIQプロジェクトに追加できるC / C ++ヘッダーファイルに変換されます。変換プロセスとtflite_convertユーティリティについては、eIQユーザーガイドで詳しく説明されています。このユーティリティについては、Googleの公式ドキュメントにも記載されています。
Embedded WizardStudioの概要
MIMXRT1060-EVKのグラフィック機能を利用するために、このプロジェクトにはGUIが含まれていました。そのために、組み込みデバイスで実行されるアプリケーション用のGUIを開発するためのIDEであるEmbedded WizardStudioが使用されました。 IDEの無料の評価版が利用可能ですが、このバージョンはグラフィカルユーザーインターフェイスの最大の複雑さを制限し、GUIに透かしを追加します。
Embedded Wizard Studioの利点の1つは、XNPのSDKに基づいてMCUXpressoおよびIARプロジェクトを生成できることです。つまり、IDEでユーザーインターフェイスを作成した後、開発者はデバイスですぐにテストできます。
IDEは、ボタン、タッチセンシティブ領域、図形など、キャンバス上に配置されるオブジェクトとツールを提供します。次に、それらのプロパティは、開発者のニーズと期待に合うように設定されます。これらはすべて直感的でユーザーフレンドリーな方法で機能し、GUI開発プロセスを大幅にスピードアップします。
ただし、生成されたGUIプロジェクトはCであり、qIQの例はC / C ++であるため、いくつかの変換手順でGUIプロジェクトを既存のeIQアプリケーションプロジェクトとマージする必要があります。したがって、一部のヘッダーファイルの内容は次のように囲まれている必要があります。
#ifdef __cplusplus
extern "C" {
#endif
<コード> / * Cコード* /
#ifdef __cplusplus
<コード>}
#endif
さらに、ほとんどのソースファイルとヘッダーファイルがSDKのミドルウェアフォルダー内の新しいフォルダーに移動され、これらの変更を反映するために新しいインクルードパスが追加されました。最後に、いくつかのデバイス固有の構成ファイルが比較され、適切にマージされました。
完成したアプリケーションとその機能
アプリケーションのGUIは、タッチセンサー式LCDに表示されます。数字を書き込むための入力領域と、分類の結果を表示するための入力領域が含まれています。推論の実行ボタンは推論を実行し、クリアボタンは入力フィールドと出力フィールドをクリアします。アプリケーションは、予測の結果と信頼度を標準出力に出力します。

図4。 サンプルアプリのGUIには、入力フィールド、出力フィールド、および2つのボタンが含まれています。結果と信頼度も標準出力に出力されます。
TensorFlowLiteモデルの精度
前述のように、このモデルは、米国式の手書きの数字を分類するときに、トレーニングおよびテストデータで高精度を実現できます。ただし、これは、このアプリケーションで使用される場合には当てはまりません。これは、主に、LCDに指で書かれた数字が、紙にペンで書かれた数字と同じになることはないためです。これは、実際の本番データで本番モデルをトレーニングすることの重要性を浮き彫りにします。
より良い結果を得るには、新しいデータセットを収集する必要があります。さらに、手段は同じでなければなりません。この場合、数字を描くためにタッチスクリーン入力を使用してサンプルを収集する必要があります。予測の精度を高めるためのさらなる技術が存在します。 NXPコミュニティのWebサイトには、転移学習手法の使用に関するウォークスルーが含まれています。
実装の詳細
Embedded Wizardは、ユーザーが入力領域上で指をドラッグした場合など、GUIの相互作用に反応するトリガーとしてスロットを使用します。その場合、スロットは指の下にピクセル幅の線を継続的に描画します。その線の色は、メインの色定数によって定義されます。
クリアボタンのスロットは、両方のフィールドのすべてのピクセルの色を背景色に設定し、推論の実行ボタンは、入力領域、基になるビットマップ、および領域の幅と高さへの参照を保存して、ネイティブに渡しますそれらを処理するCプログラム。
機械学習モデルのビットマップのサイズはわずか28x28ピクセルであり、アプリケーションをより快適に使用できるように入力領域は112x112の正方形として作成されているため、画像を縮小する場合は追加の前処理が必要です。そうしないと、そのプロセスによって画像が大きく歪んでしまいます。
最初に、入力領域の次元を持つ8ビット整数の配列が作成され、ゼロで埋められます。次に、画像と配列が繰り返され、画像に描画されたすべてのピクセルが0xFFとして配列に格納されます。入力を処理するとき、メインカラーのピクセルは白と見なされ、それ以外はすべて黒と見なされます。さらに、各ピクセルが3x3の正方形に拡大されて線が太くなり、画像のダウンスケーリングがより安全になります。画像を必要な28x28の解像度に拡大縮小する前に、図面をトリミングして中央に配置し、MNIST画像に似せます。

図5。 前処理された入力データを含む配列の視覚化。
機械学習モデルは、アプリケーションの起動時に割り当て、ロード、準備されます。推論要求ごとに、モデルの入力テンソルに前処理入力が読み込まれ、モデルに渡されます。入力はピクセルごとにテンソルにコピーする必要があり、整数値はプロセスで浮動小数点値に変換する必要があります。このNXPアプリケーションノートには、コードの詳細なメモリフットプリントが含まれています。
TensorFlow Lite:実行可能なソリューション
機械学習を使用した手書き数字認識は、組み込みシステムに問題を引き起こす可能性があり、TensorFlowLiteは実行可能なソリューションを提供します。このソリューションを使用すると、デジタルロックのピン入力フィールドなど、より複雑なユースケースを実装できます。この記事で説明したように、実際の本番データで本番モデルをトレーニングすることは非常に重要です。この記事で使用されたトレーニングデータは、一枚の紙にペンで書かれた数字で構成されていました。これにより、タッチスクリーンに描画された数字を検出するために使用される場合、モデルの全体的な精度が低下します。さらに、地域の違いを考慮に入れる必要があります。
i.MX RTクロスオーバーMCUシリーズは、この記事で提供されている例のように、さまざまな組み込みアプリケーションに実装できます。 NXPには、パフォーマンスと使いやすさのギャップを埋めるのに役立つi.MXRTクロスオーバーMCUシリーズに関する十分な情報があります。
i.MX RTクロスオーバーMCUの詳細については、i.MXRT製品ページにアクセスしてください。
業界記事は、業界パートナーが編集コンテンツに適さない方法でAll About Circuitsの読者と有用なニュース、メッセージ、テクノロジーを共有できるようにするコンテンツの形式です。すべての業界記事は、読者に有用なニュース、技術的専門知識、またはストーリーを提供することを目的とした厳格な編集ガイドラインの対象となります。業界記事で表明されている見解や意見はパートナーのものであり、必ずしもAll AboutCircuitsやそのライターのものではありません。
産業用ロボット
- 自律型ロボットで無駄を減らす方法
- PiCameraによるAI数字認識
- NXPのi.MXRT500クロスオーバーMCUによる電力管理の最適化
- NXPのi.MXRT500クロスオーバーMCUを使用したDSPの有効化について
- TensorFlowを使用して変分オートエンコーダーを構築する方法
- アートワークでのエポキシ樹脂の使用
- Javaのインターフェースとは:例を使用してインターフェースを実装する方法
- CNC マシンの手入れ? Cobot を使った方法はこちら
- 安川ロボットプログラミング入門
- Raspberry Pi 用 RoboDK の使用を開始する方法
- 情報モデルを使用して OPC UA クライアントからファンクション ブロックを呼び出す方法