


ニューラルネットワークへのバイアスノードの組み込み
この記事では、Pythonなどの高級プログラミング言語で実装された多層パーセプトロンにバイアス値を追加する方法を説明します。
エンジニアリングディレクターのRobertKeimによって作成されたニューラルネットワークのAllAboutCircuitsシリーズへようこそ。バイアスノードに関するこのレッスンに進む前に、以下のシリーズの残りの部分に追いつくことを検討してください。
- ニューラルネットワークを使用して分類を実行する方法:パーセプトロンとは何ですか?
- 単純なパーセプトロンニューラルネットワークの例を使用してデータを分類する方法
- 基本的なパーセプトロンニューラルネットワークをトレーニングする方法
- 単純なニューラルネットワークトレーニングを理解する
- ニューラルネットワークのトレーニング理論の概要
- ニューラルネットワークの学習率を理解する
- 多層パーセプトロンを使用した高度な機械学習
- シグモイド活性化関数:多層パーセプトロンニューラルネットワークでの活性化
- 多層パーセプトロンニューラルネットワークをトレーニングする方法
- 多層パーセプトロンのトレーニング式とバックプロパゲーションを理解する
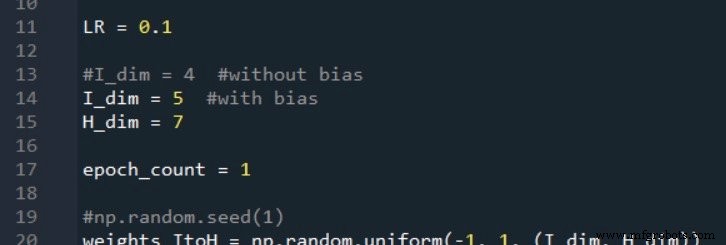
- Python実装のためのニューラルネットワークアーキテクチャ
- Pythonで多層パーセプトロンニューラルネットワークを作成する方法
- ニューラルネットワークを使用した信号処理:ニューラルネットワーク設計での検証
- ニューラルネットワークのデータセットのトレーニング:Pythonニューラルネットワークをトレーニングおよび検証する方法
- ニューラルネットワークにはいくつの隠しレイヤーと隠しノードが必要ですか?
- 隠れ層ニューラルネットワークの精度を高める方法
- バイアスノードをニューラルネットワークに組み込む
パーセプトロンの入力レイヤーまたは非表示レイヤーに追加できるバイアスノードは、設計者が選択した一定の値を生成します。
バイアス値についてはパート11で説明しましたが、バイアスノードとは何か、またはバイアスノードがニューラルネットワークの機能をどのように変更して強化する可能性があるかが不明な場合は、その記事の関連部分を読む(または再読する)ことをお勧めします。
この記事では、最初にバイアス値をネットワークアーキテクチャに組み込む2つの方法を説明し、次にバイアス値が前の記事(パート16)で得た精度パフォーマンスを改善できるかどうかを確認するための実験を行います。
スプレッドシートを介したバイアスの組み込み
次の図は、入力層にはバイアスノードがあり、隠れ層にはないネットワークを示しています。
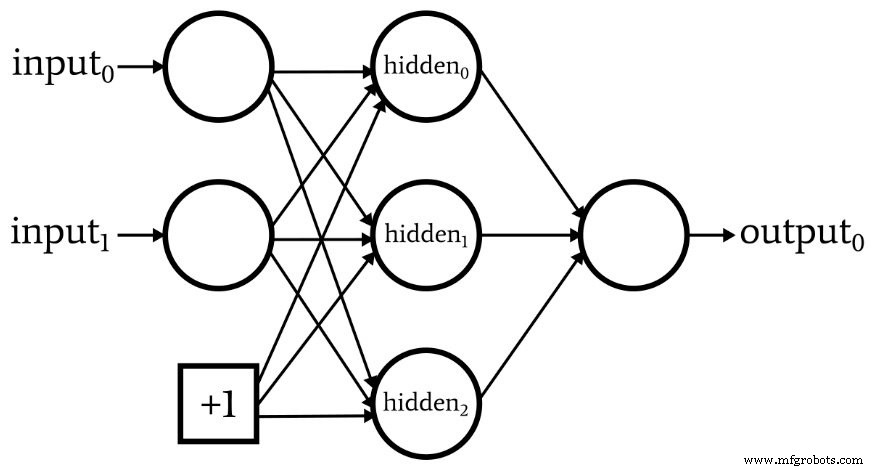
これが探している構成である場合は、トレーニングまたは検証データを含むスプレッドシートを使用してバイアス値を追加できます。
この方法の利点は、コードを大幅に変更する必要がないことです。最初のステップは、スプレッドシートに列を挿入し、バイアス値を入力することです。
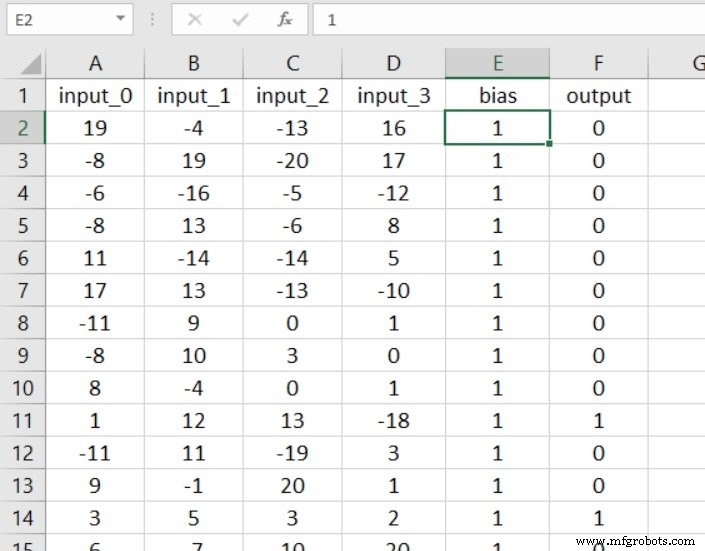
これで、入力レイヤーの次元を1つ増やすだけです。
バイアスをコードに統合する
隠れ層にバイアスノードが必要な場合、またはスプレッドシートでの作業が嫌いな場合は、別のソリューションが必要になります。
入力層と非表示層の両方にバイアスノードを追加したいとします。まず、 I_dim を増やす必要があります および H_dim 、私たちの目標は、バイアスノードを統合して、通常のノードのように機能するが、設計者が選択し、変更されない事前に重み付けされた値を使用することです。
これは次のように実行します:

入力層バイアスノードの作成
ご存知かもしれませんが、次のコードを使用してトレーニングデータセットを組み立て、ターゲット出力値を分離し、トレーニングサンプルの数を抽出します。

これらのステートメントの後、2次元配列の列数 training_data スプレッドシートの入力列の数と等しくなります。入力レイヤーのバイアスノードを考慮して、列の数を1つ増やす必要があります。その間に、この追加の列に目的のバイアス値を入力できます。
次のコードは、これを行う方法を示しています。
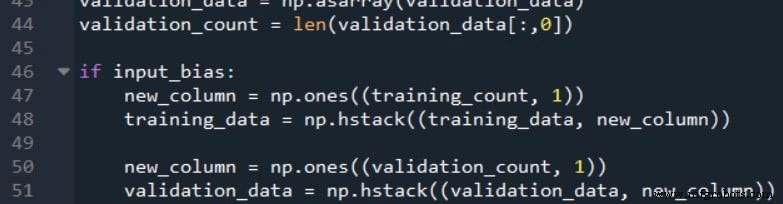
np.ones() 関数は、行数が training_count に等しい1列の配列を作成します 、およびこの配列の各要素に+1の値を割り当てます。次に、 np.hstack()を使用します 元の training_data の右側に1列の配列を追加する関数 配列。
トレーニングデータと検証データの両方に対してこの手順を実行したことに注意してください。目標は実際にトレーニングまたは検証データを変更することではないことを覚えておくことが重要です。むしろ、必要なネットワーク構成を実装する手段としてデータを変更しています。
パーセプトロンのブロック図を見ると、バイアスノードはネットワーク自体の要素として表示されます。したがって、ネットワークによって処理されるサンプルはすべて、この変更を行う必要があります。
隠れ層バイアスノードの作成
隠れ層のアクティブ化後の値を計算するforループを変更し、最後の隠れノード(実際にはバイアスノード)のバイアス値を手動で挿入することで、フィードフォワード処理にバイアスを追加できます。
最初の変更を以下に示します:
ネットワークに隠れ層バイアスノードがないように構成されている場合は、 hidden_bias 0に等しく、forループの実行は変更されません。
一方、隠れ層のバイアスノードを含めることにした場合、forループは、層の最後のノード(つまり、バイアスノード)のアクティブ化後の値を計算しません。
次のステップは、ノード変数をインクリメントして、 postActivation_H のバイアスノードにアクセスするようにすることです。 配列を作成し、バイアス値を割り当てます。

これらの変更は、コードの検証部分にも適用する必要があることに注意してください。
+1以外のバイアス値
私の経験では、+ 1が標準のバイアス値であり、他の数値を使用する正当な理由があるかどうかはわかりません。バイアスは重みによって変更されるため、+ 1を選択しても、バイアスがネットワークの全体的な機能とどのように相互作用するかについて確固たる制限はありません。
ただし、他のバイアス値を試してみたい場合は、簡単に行うことができます。隠れたバイアスについては、 postActivation_H [node] に割り当てられた番号を変更するだけです。 。入力バイアスについては、 new_column を乗算できます。 目的のバイアス値による配列(最初はすべての要素に対して+1があります)。
バイアスの効果のテスト
パート16を読んだ方は、私のパーセプトロンが実験3のサンプルを分類するのに問題があったことをご存知でしょう。これは、「高度な複雑さ」の問題でした。
1つ以上のバイアスノードを追加することで、一貫性のある大幅な改善が得られるかどうかを見てみましょう。
私の仮定では、分類精度の違いはかなり微妙であるため、この実験では、平均して5回ではなく10回実行しました。トレーニングと検証のデータセットは、入力と出力の間の同じ高度な複雑さの関係を使用して生成され、隠れ層の次元は7でした。
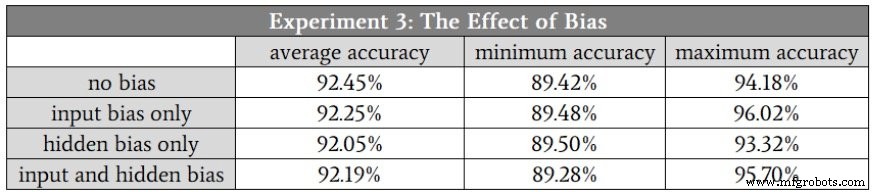
結果は次のとおりです。
結論
ご覧のとおり、バイアスノードは分類パフォーマンスに大きな変化をもたらしませんでした。
これは実際には私を驚かせません。バイアスノードが少し強調されすぎることがあると思います。この実験で使用した入力データの性質を考えると、バイアスノードが役立つ理由はわかりません。
それにもかかわらず、バイアスは一部のアプリケーションでは重要な手法です。バイアスノード機能をサポートするコードを記述して、必要なときにそこにあるようにすることをお勧めします。
産業用ロボット