


クラウドの停止:なぜ、どのように発生するのか?
IT がクラウド サービスに依存するほど、クラウドの停止によるダウンタイムと収益の損失に苦しむ可能性が高くなります。パブリック クラウドを使用する組織の 60% 以上が、2022 年にこれらのインシデントによる損失を報告しているため、企業が直面する可能性が低い異常事態ではありません。
しかし、サービス停止は、クラウドを永久に離れる十分な理由になるのでしょうか?それとも、時折のダウンタイムのリスクがあっても、このインフラストラクチャ タイプを使い続ける必要がありますか?
この記事では、クラウドの停止について知っておく必要があるすべてについて説明します .それらの主な原因を概説し、目を見張るような統計を調べ、クラウドのダウンタイムの影響を最小限に抑える方法を示し、近年発生した最も影響の大きい停止について調べます。

クラウド停止とは
クラウドの停止とは、エンド ユーザーがクラウド プロバイダーのサービスを利用できない期間です。ベンダーのインフラストラクチャが (バグ、停電などにより) ダウンし、プロバイダーが問題を解決するまで、クライアントはクラウドベースの資産にアクセスできなくなります。
影響に関しては、オンサイトのデータ センターのダウンとクラウドの停止に違いはありません。どちらの場合も IT 資産にアクセスできなくなりますが、クラウド コンピューティングへの無干渉アプローチには、いくつかの固有の考慮事項が追加されます。
- クラウドの停止は障害の可視性がほとんどまたはまったくないため、通常、ユーザーは何が問題だったのかわかりません。
- プロバイダーのチームがエラーを修正する責任があるため、クライアントは回復プロセスに参加しません。
- 問題を可視化することも制御することもできないため、サービスがいつオンラインに戻るかを知る方法はありません。
ローカル ハードウェアと同様に、次の 2 種類の停止の可能性があります。
- 計画的 (通常、定期メンテナンスのために発生します)。
- 予定外 (プロバイダーが予期しないエラーに遭遇し、復元措置を実行する必要がある場合に発生します)。
最近の調査によると、計画外の停止は、計画されたダウンタイム (オンプレミスとクラウドの両方) よりも 35% 高いコストがかかることが明らかになりました。価格の差が生じるのは、予期しないインシデントの特定と修正に時間がかかるためです。停止が長引けば長引くほど、被害は大きくなります。
オンサイト ハードウェアと比較して、クラウドベースのインフラストラクチャは、ダウンタイムが頻繁に発生しますが、深刻度は低くなります。 . 100% のアップタイムを提供するホスティング システムはないため、クライアントは、クラウド コンピューティングの利点と引き換えに、時折の停止を許容する準備ができています。この意欲は市場の成長にも表れています。クラウドは、2024 年には全世界の IT 支出の 14.2% を占めるようになります (2020 年の 9.1% から増加)。
クラウド停止の原因
クラウドの停止は、プロバイダーの制御範囲内外のさまざまな原因によって発生します。最も一般的なもののリストは次のとおりです:
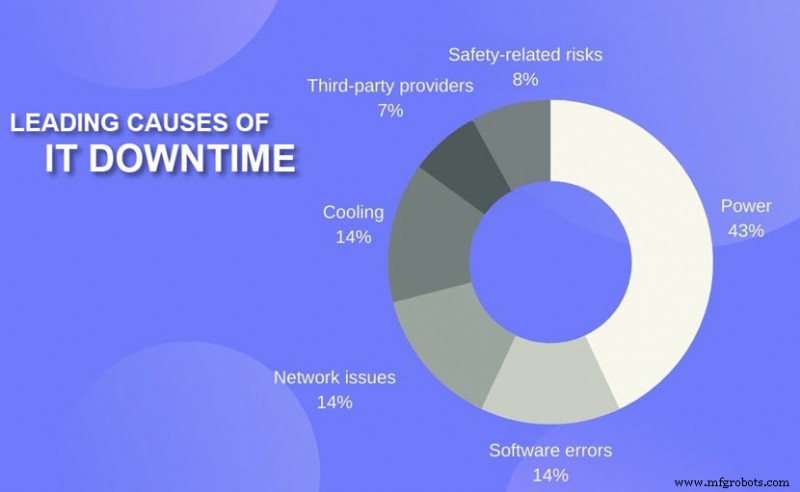
- 停電: 電力関連の問題は、すべてのクラウド停止の 43% を引き起こし、重大なダウンタイムと経済的損失をもたらします。無停電電源装置 (UPS) の障害は、電源事故の最大の原因です。
- サイバーセキュリティ: 分散型サービス拒否 (DDoS) などのサイバー攻撃は、着信トラフィックでデータ センターに過負荷をかけます。その場合、エンドユーザーは同じネットワーク インフラストラクチャを介してサービスにアクセスできません。その他の脅威 (ランサムウェアや SQL インジェクションなど) により、プロバイダーはサービスをシャットダウンし、オフラインで問題を解決する必要があります。
- ヒューマン エラー: たった 1 つのコマンドの誤りや配線の誤りが、IT インフラストラクチャ全体をダウンさせる可能性があります。ヒューマン エラーは、機能停止につながる物理的な問題とソフトウェアの問題の両方を引き起こします。
- 技術的な問題: クラウド サービスはハードウェア技術の複雑なシステムに依存しているため、エラーがレーダーの下に長時間留まると、クラウドの停止につながる可能性があります。
- ソフトウェアのバグ: クラウド データ センターでは、グリッチやバグがよく発生します。問題の背後にある通常の原因は、データ形式のバグ、障害関連のバグ、タイミングのバグ、定数値のバグです。
- ネットワークの問題: ネットワーク通信とサードパーティの通信パートナーに関連する問題も、クラウドの停止の一般的な原因の 1 つです。
- メンテナンス: 定期的なメンテナンスやシステムのアップグレードによってシステムが停止することがありますが、エンドユーザーは通常、これらの発生について事前に知っています。
- 環境要因: ハリケーン、火災、雷雨、地震などのイベントも、施設を危険にさらしたり、地域の送電網に損害を与えたりして、クラウドのダウンタイムを引き起こします。
- より複雑な展開: より複雑な展開モデル (ハイブリッド、分散、マルチクラウドなど) は、データ センターの運用を複雑にし、エラーの可能性を増やします。
クラウドがダウンするとどうなりますか?
最良のシナリオでは、クラウドの停止は数分しか続かず、少数のユーザーまたはサービスに影響を与えます。最悪の場合、サービス停止によりクライアントのビジネスが半日以上麻痺します。企業はすべてのクラウドベースの資産へのアクセスを失い、停止が終わるまで切断されたままになります。
脅威ではありますが、2021 年の深刻なサービス停止の「わずか」7% の原因は、サードパーティ プロバイダによるミスでした .重大な停止には、次の 1 つ (または複数) が含まれる必要があります:
- 重大な経済的損失
- 評判の低下。
- コンプライアンス違反
- 生命の喪失。
差し迫った懸念事項は他にもありますが (下のドーナツ チャートに示すように)、1 分間のダウンタイムの平均コストは 5,600 ドルであることを覚えておいてください。 (この 1 分あたりの数字は、企業では 9,000 ドルになります)。準備ができていない場合 (つまり、データのバックアップや災害復旧などがない場合)、クラウドの停止によってサービスが停止し、収益に大きな打撃を与える可能性があります。
運用の小さなセグメントをクラウドに保持している企業は、停止の影響を受けにくくなります。たとえば、メールをクラウドでのみホストしている場合、1 日中停止しても大惨事にはなりません。インシデントが発生するのを待つか、機能を制限したアプリを実行することができます。これは、クラウドを使用して IoT プラットフォームを実行したり、支払い処理を実行したりする場合には機能しない戦略です。
場合によっては、クラウドの停止によってデータが永久に失われることがあります (失われるデータの量は、バックアップの頻度によって異なります)。また、厳格な業界のクライアントは、停止がデータ侵害や漏えいにつながる場合、法的罰金の責任を負います。そのため、クラウド ストレージに保持するものを決定する際には注意してください。
ユーザーができること
クラウド停止の影響を軽減するために企業が行っていることは次のとおりです。
- 単一障害点を取り除く: オンサイトのサーバー ルームまたはセカンダリ プロバイダーのいずれかで、ミッション クリティカルなすべての IT コンポーネントのバックアップを準備します。クラウドがダウンした場合、フェイルオーバー (スタンバイ サーバー、ハードウェア コンポーネント、ネットワークなどに切り替えるプロセス) を実行して、ビジネスの継続性を確保します。
- 危機管理計画を立てる: ディザスター リカバリー計画では、障害が発生した場合にチームが行うことについて段階的な戦略の概要を説明します。この計画では、データの保護、フェールオーバーの実行、ビジネス継続性の確保、運用の復元について説明します。クラウドの停止をタイムリーに計画することで、ダウンタイム中の最善の行動方針を評価するための時間の無駄を避けることができます。
- 可用性の高い SLA に投資する: ビジネス クリティカルなタスクで長時間のクラウド停止を許容できない場合は、99.999% のアップタイム (年間最大 5.25 分のダウンタイム) を保証するものなど、より可用性の高いサービス レベル アグリーメント (SLA) を探してください。これらの契約は費用がかかりますが、サービスをオンラインに保つことは、クラウド プロバイダーにとってより重要な優先事項になります。
- 定期的なデータ バックアップの実行: バックアップは、クラウドの停止によってデータベースが破損または削除された場合に、チームがファイルの最新バージョンを復元する方法を確保します。理想的には、バックアップは 1 時間に 1 回から 1 日 1 回の範囲で自動的に実行される必要があります (ミッションの重要度によって異なります)。
- 障害をできるだけ早く検出: チームが設定した追加のクラウド監視機能は、プロバイダーの通知を待つのではなく、リアルタイムで停止を特定するのに役立ちます。ダウンタイムの検出を改善し、タイムリーなフェールオーバーを確保するための最適なクラウド モニタリング ツールのリストを以下に示します。
最近の最大のクラウド停止
クラウドを使用する場合、クラウドの停止は避けられず、最も人気のあるプロバイダー (Azure、AWS、Google Cloud など) でさえ、ダウンタイムの影響を受けません。最近の歴史の中で最も重大なクラウド障害のいくつかを見てみましょう.
Azure の停止 (2021 年 10 月)
2021 年 10 月、Microsoft Azure は混乱に見舞われ、仮想マシン サービスが 6 時間停止しました .停止中、多くのユーザーは新しい VM をデプロイしたり、拡張機能を更新したりできませんでした。基本的なサービス管理操作 (開始、作成、削除など) もエラーにつながりました。
クラウドの停止の原因は、VM クエリがアーティファクトの必要なバージョン データを取得できなかったことです。復旧後のレポートでは、Microsoft が VM アーキテクチャの 1 つを移行したときに、ソフトウェア ベースのミスが発生したことが明らかになりました。
Google Cloud の停止(2021 年 11 月)
Google Cloud が約 2 時間ダウンしました 昨年の 11 月中旬に、次のような影響を受けました:
- ホーム デポ。
- スナップチャット。
- Etsy.
- 不和。
- Spotify。
影響を受けた Web サイトでは、訪問者がアクセスしようとすると 404 エラーが表示されました。 Google は、クラウドの停止の原因は、負荷分散を担当するネットワーク構成の不具合であると報告しました。
AWS の停止 (2021 年 12 月)
AWS の主力施設の 1 つで、大規模な接続アクティビティの急増がネットワーク デバイスを圧倒し、さまざまなウェブサイトやアプリに影響を与えました。最も注目すべき「犠牲者」は次のとおりです。
- Amazon のウェブサイト。
- プライム ビデオ。
- ネットフリックス
- IMDb.
- プレイステーション ネットワーク。
データセンターの問題により、内部 AWS ネットワーク内で深刻な遅延が発生しました。お客様のアプリは波及効果を感じ、約 7 時間 トラフィックの遅延や完全なシャットダウンに見舞われました .
その後 2 回の IBM 停止 (2022 年 1 月)
IBM のインフラストラクチャの問題により、ダラス地域のクラウド サービスが 5 時間以上影響を受けました .社内チームが問題を解決しましたが、誤って仮想プライベート クラウドでさらに 1 時間に及ぶ問題が発生しました。二次的な問題は、米国、日本、カナダ、ドイツを含む世界中のユーザーに影響を与えました。
AWS/Slack の停止 (2022 年 2 月)
Slack は 2 月に AWS クラウド リソースの停止に見舞われ、5 時間 通信プラットフォームの通常の使用が妨げられました .報告された 11,000 人を超えるユーザーは、次のことができませんでした:
- メッセージを送受信する
- ファイルをアップロードする
- チャンネルに参加する
- デスクトップ アプリを起動します。
Slack のチームは、クラウドの停止の背後にある理由を決して共有せず、影響を受けたすべてのユーザーにアプリを再起動し、回復後にキャッシュをクリアするように要求しました.
iCloud の停止 (2022 年 3 月)
15 の主要な Apple サービスが 4 時間ダウンしました 3 月に次のようなクラウド障害が発生しました:
- アプリ ストア。
- Apple マップ。
- Apple TV。
Apple の企業および小売システムもダウンしました。同社は後に、根本的な原因が同社のドメイン ネーム システム (DNS) に関連する問題であることを明らかにしました。
Google Cloud の停止(2022 年 3 月)
2022 年 3 月 8 日、Google Cloud のユーザーに 2 時間半のサービス エラーが発生しました . Spotify と Discord は、サービス停止の影響を受けました。
構成を処理するための Traffic Director コードの変更により、エラーが発生しました。復旧後のレポートによると、不適切なコードの変更により構成データ形式の移行が無視されたため、プラットフォームはユーザーのプログラミングをうっかり削除してしまいました。
アトラシアンの機能停止 (2022 年 4 月)
今年最大の Atlassian サービス停止は 4 月 5 日に始まり、4 月 18 日に終了しました (一部のユーザーは 4 月 8 日までにサービスの復旧を開始しました)。同社は、チームのコミュニケーションが不十分であり、インシデント対応計画が不十分だったために停止が発生したと説明しました.
このクラウド停止は ほぼ 2 週間続きましたが、 一部のユーザーについては、クライアント データが大幅に失われたという報告はありませんでした。ただし、Atlassian の主力製品である Trello と Jira の両方のユーザーがこの問題の影響を受けました。
Microsoft Azure の停止 (2022 年 6 月)
6 月 7 日、Azure のお客様は、米国東部 2 リージョン (主にバージニア) でホストされているリソースに接続できませんでした。停止は約 12 時間続きました ゾーン冗長インフラストラクチャに依存する消費者には影響しませんでした。侵害されたサービスには以下が含まれます:
- アプリケーション インサイト
- ログ分析。
- マネージド ID サービス。
- メディア サービス。
- ネットアップ ファイル。
原因は、ローカル データ センターの 1 つで発生した突然の電力変動で、これによりエア ハンドリング ユニット (AHU) がシャットダウンしました。
Cloudflare の停止 (2022 年 6 月)
6 月、Cloudflare での偶発的な停止により、1 時間半続く大規模な混乱が発生しました 、次のような人気のあるサイトを削除します:
- 不和。
- ショピファイ。
- フィットビット。
- ペロトン。
サンフランシスコを拠点とするベンダーは、19 のデータ センターでネットワーク構成が変更されたため、予期しないダウンタイムが発生したと説明しました。
クラウド停止計画の価値を見落とさないでください
近年のクラウド停止の例は、明確なメッセージを伝えています。クラウドは IT のゲームチェンジャーですが、テクノロジーは絶対確実ではありません .エンドユーザーとアプリの可用性を重視する企業は、時折発生するダウンタイムに備える必要があります。そのため、バックアップとディザスター リカバリー (BDR) はクラウドベースのリソースを使用する上で不可欠な要素になります。
クラウドコンピューティング
- トランスファーモールディングとは何ですか?どのように機能しますか?
- パブリッククラウドのパフォーマンスをベンチマークする方法(および理由)
- クラウドセキュリティとは何ですか?なぜそれが必要なのですか?
- クラウドとそれがITの世界をどのように変えているか
- エージェントレスとエージェントベースのアーキテクチャ:なぜそれが重要なのか?
- 難読化されたVPNサーバーとは何ですか?どのように機能しますか
- Google Cloud Storageはどのように機能しますか?
- トランスミッションとは何ですか?それはどのように機能しますか?
- 真空監査を実行する理由と方法
- 産業用クラッチとは何ですか?
- クレーン検査:いつ、なぜ、そしてどのように?