


データ分析プロジェクトで落とし穴を回避する方法
最近のCapgeminiの調査によると、ヨーロッパのビッグデータイニシアチブの15%が失敗しています。あなたのプロジェクトが成功した85%に属することを確実にするために、私は注意すべき4つの主要な落とし穴を要約しました。 (このブログ投稿には最初の2つの落とし穴が含まれており、他の2つは別のブログ投稿で公開されます。 )
これらを認識し、考慮に入れると、データ分析プロジェクトが成功する可能性が大幅に高まります。心配しないでください。これらの課題や落とし穴に直面しているのはあなただけではありません。私たちの最初のデータ分析ワークショップでは、プロジェクトの最後まで、彼らに遭遇している参加者を定期的に見ています。ここでは、多くの成功したワークショップやプロジェクトからの洞察を共有し、主な落とし穴を指摘し、使用例を示して説明したいと思います。
1。イニシエーター–ITと部門
データ分析とビッグデータは、同じように使用されることが多い場合でも、同じではありません。
IT部門は、多くの場合、「ビッグデータグラス」を通じてプロジェクトを表示します。これらは、大量のデータを収集するためのインフラストラクチャを提供します。たとえば、データベースクラスターの形式で。これらのデータベースには大量のデータが格納されており、それ自体では企業に付加価値をもたらすことはありません。そのため、データ分析プロジェクトには、常に明確に定義された技術的目標と商業的目標が必要です。そのためだけにデータを収集しても、会社には何のメリットもありません。
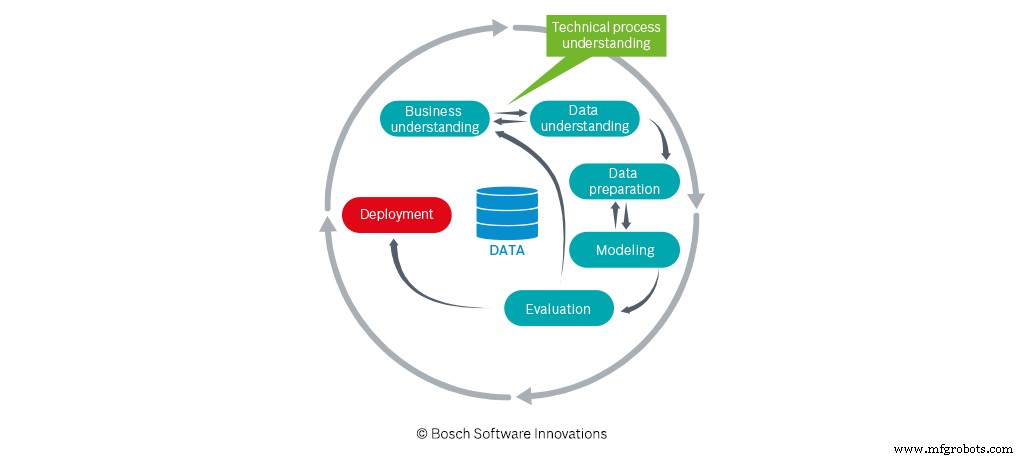
付加価値は、企業がデータと結果として得られる洞察を活用する場合にのみ発生します。ここで、その(非管理)部門が登場します。ビッグデータではなく、データ分析で達成したい目標を定義します。これらは、データサイエンティストがターゲットを絞った方法でデータを操作できるようにする技術的理解を提供します。したがって、定義されたプロジェクトの目標を達成するには、アイデアプロバイダー(部門)とデータサイエンティストの間の緊密な協力が絶対に必要です。
言い換えれば、データ分析プロジェクトの成功または失敗は、データサイエンティストに受け継がれる技術的なプロセスの理解に依存します。ここでは、データ分析エンジニアも重要な役割を果たします。それらは、異なる分野間の「翻訳」と知識の伝達をサポートします。データ分析エンジニアは、製造またはロジスティクスでの運用経験と、データ分析アプローチの基本的な理解を活用します。データの専門家は、プロジェクトの目標だけでなく、特にデータの相関関係も理解する必要があります。さらに重要なことに、彼らは現実世界(機械、センサーなど)との関係および関連するプロセスステップを確認する必要があります。
Capgeminiの調査が示すように、IT部門は多くの場合データ分析プロジェクトの開始者です。他の部門が密接に関与し、プロジェクトの技術目標を定義している限り、これ自体は問題ではありません。
2。すべてのデータが同じように作成されるわけではありません
プロジェクトが開始され、その目標が定義されました– go!
やめて!
データサイエンティストが始める前に、データの質と量を確認する必要があります。
a)データの品質
ここでは、データが利用可能な形式、どこでどのデータを探すか、データがさまざまなソース間で透過的であるかどうかを検討することが重要です。
例:
複数のソースからのデータセットを統合するには、データを正しく照合できるようにする一意の識別子が必要です。これは、たとえば、タイムスタンプまたは部品番号の場合があります。個々のデータソースで異なる日付/時刻形式が使用されている場合(ドイツ語と米国の日付形式、UTSの時刻など)、タイムスタンプを使用すると統合がより複雑になります。ただし、それでも可能です。対照的に、異なるタイムベースが使用されている場合、それは事実上不可能です。これは、すべてのデータソースのタイムスタンプを生成する均一な時刻同期がない場合です。
b)データの量
多いほど良い–ということわざがあります。しかし、データ分析に関しては、これは部分的にしか当てはまりません。もちろん、一般的に言えば、データが多ければ多いほどよいのです。ただし、ここでも、考慮すべき重要な側面がいくつかあります。
技術的な目標の定義によっては、たとえば、基礎となるデータに肯定的な結果だけでなく、十分な数の否定的な結果も含まれていることが重要な場合があります。
例:否定的な結果を予測する
プロジェクトの目標が否定的な結果を予測するためのモデルを開発することである場合、予測モデルのトレーニングに使用されるトレーニングデータセットには、十分な数の否定的な結果が含まれている必要があります。そうしないと、モデルはこれらの否定的な結果を学習できず、したがってそれらを予測できなくなります。その結果、このデータセットでプロジェクトの目標を達成することはできません。このため、トレーニングデータセットをコンパイルするときは、予測するのに十分な量のパラメーター(ターゲット変数)が含まれていることを確認する必要があります。上記の例では、否定的な結果になります。これを実現する1つの方法は、データが収集される期間を延長することです。
c)「正しい」データ
したがって、データの量だけが基準ではないことは明らかです。何よりも、適切なデータが必要です!
「正しいデータ」とはどういう意味ですか?
データには、技術プロジェクトの目標を達成するために必要な関連情報が含まれている必要があります。たとえば、表面粗さ測定によって定義された製品品質を予測するためのモデルを開発する場合は、この変数をデータセットで表す必要があります。後で測定値を保存せずに測定を実行すると、対応するモデルを開発できなくなります。これも解決できない問題ではありませんが、適切なデータベースを最初に生成する必要があるため、進行が遅れる可能性があります(たとえば、追加のセンサーテクノロジーの助けを借りて、関連データを保存するなど)。
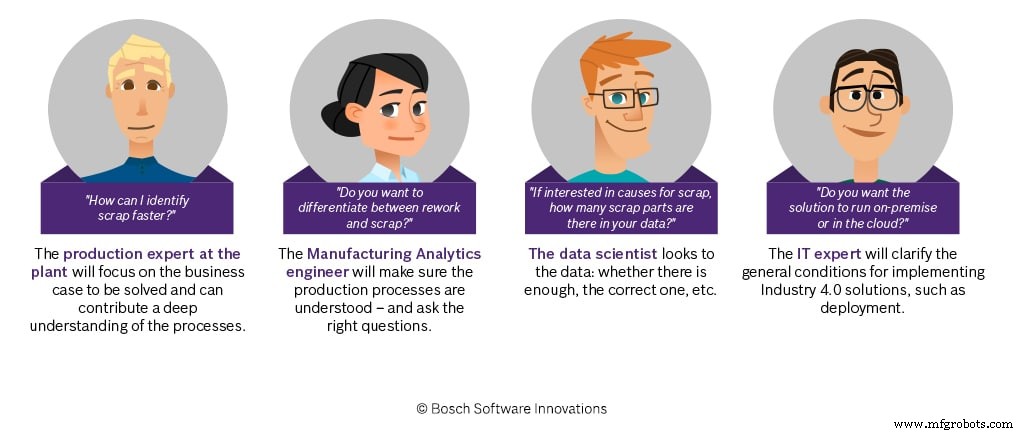
データ分析プロジェクトが成功することを誰が確認しますか?
 出典:Bosch.IO
出典:Bosch.IO
専門家がa)、b)、およびc)を達成できるように、多くの成功したプロジェクトで得た経験を取り入れ、プロジェクトの開始時に提供するデータ品質ガイドラインにプールしました。また、最初のワークショップでは、迅速な成果をもたらすユースケースを特定することでこのトピックに対処します。このようにして、製造の専門家のこれらのトピックに対する認識を高めます。これは、プロセスの次のステップにとって明らかに有利であることが常に証明されています。
産業技術
- エッジ分析によるインダストリー4.0のアップグレード
- ビッグデータ分析による製造の最適化
- 中古CNCマシンの問題を回避する方法
- ビッグデータプロジェクトとAIでビジネスの成果を推進
- ラストマイルデリバリーの3つの落とし穴—そしてそれらを回避する方法
- データサイエンスがコロナウイルスの発生との戦いにどのように役立ったか
- データマイニング、AI:産業ブランドがEコマースに追いつく方法
- クラウド分析がデジタルサプライチェーンの変革をどのようにスピードアップできるか
- IoTプロジェクトが失敗する5つの理由とそれを回避する方法
- 産業機械学習プロジェクトの開発:避けるべき3つの一般的な間違い
- メーカーがより良い顧客体験のためにアナリティクスをどのように使用できるか