


TensorFlowを使用して変分オートエンコーダーを構築する方法
オートエンコーダーの重要な部分、バリエーション型オートエンコーダーがどのように改善されるか、TensorFlowを使用してバリエーション型オートエンコーダーを構築およびトレーニングする方法を学びます。
>長年にわたり、多くの分野や業界が人工知能(AI)の力を活用して研究の限界を押し広げてきました。データの圧縮と再構築も例外ではなく、人工知能のアプリケーションを使用して、より堅牢なシステムを構築できます。
この記事では、データを圧縮し、オートエンコーダーを使用して圧縮データを再構築するためのAIの非常に一般的なユースケースを見ていきます。
オートエンコーダアプリケーション
オートエンコーダーは、機械学習で多くの人々の注目を集めています。この事実は、オートエンコーダーの改良といくつかのバリエーションの発明によって明らかになりました。それらは、ニューラル機械翻訳、創薬、画像ノイズ除去などのいくつかの分野で、いくつかの有望な(最先端ではないにしても)結果をもたらしました。
オートエンコーダの部品
オートエンコーダーは、ほとんどのニューラルネットワークと同様に、勾配を逆方向に伝播して重みのセットを最適化することで学習しますが、オートエンコーダーのアーキテクチャとほとんどのニューラルネットワークのアーキテクチャの最も顕著な違いはボトルネックです。このボトルネックは、データを低次元の表現に圧縮する手段です。オートエンコーダの他の2つの重要な部分は、エンコーダとデコーダです。
これらの3つのコンポーネントを融合すると、「バニラ」オートエンコーダーが形成されますが、より洗練されたコンポーネントにはいくつかの追加コンポーネントが含まれる場合があります。
これらのコンポーネントを個別に見てみましょう。
エンコーダー
これはデータの圧縮と再構築の最初の段階であり、実際にデータの圧縮段階を処理します。エンコーダーは、データ特徴(画像圧縮の場合はピクセルなど)を取り込み、データ特徴のサイズよりも小さいサイズの潜在ベクトルを出力するフィードフォワードニューラルネットワークです。
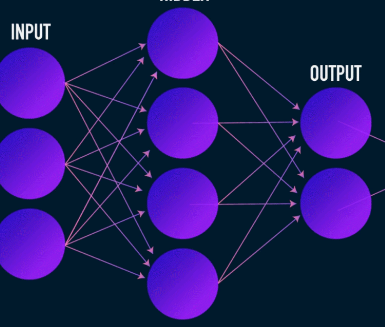
画像はJamesLoyの好意により使用されました
データの再構築を堅牢にするために、エンコーダーはトレーニング中にその重みを最適化して、入力データ表現の最も重要な機能を小さなサイズの潜在ベクトルに絞り込みます。これにより、デコーダーは入力データに関する十分な情報を取得して、最小限の損失でデータを再構築できます。
潜在ベクトル(ボットレネック)
オートエンコーダのボトルネックまたは潜在ベクトルコンポーネントは最も重要な部分であり、サイズを選択する必要がある場合はさらに重要になります。
エンコーダーの出力は、潜在ベクトルを提供するものであり、入力データの最も重要な特徴表現を保持することになっています。また、デコーダー部分への入力として機能し、再構築のために有用な表現をデコーダーに伝播します。
潜在ベクトルに小さいサイズを選択すると、入力データに関する情報が少なくなり、入力データの特徴の表現が得られます。はるかに大きな潜在ベクトルサイズを選択すると、オートエンコーダによる圧縮の概念全体が軽視され、計算コストも増加します。
デコーダー
この段階で、データの圧縮と再構築のプロセスが完了します。エンコーダーと同様に、このコンポーネントもフィードフォワードニューラルネットワークですが、エンコーダーとは構造的に少し異なります。この違いは、デコーダーがデコーダーからの出力よりも小さいサイズの潜在ベクトルを入力として受け取るという事実に起因します。
デコーダーの機能は、入力に非常に近い潜在ベクトルから出力を生成することです。
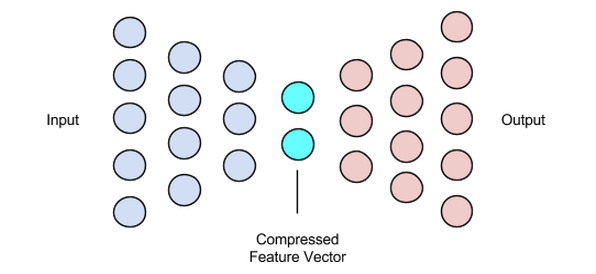
画像はChimanKwanの好意により使用されました
オートエンコーダのトレーニング
通常、オートエンコーダのトレーニングでは、これらのコンポーネントを個別に構築するのではなく、一緒に構築します。最急降下法やADAMオプティマイザーなどの最適化アルゴリズムを使用してエンドツーエンドでトレーニングします。
損失関数
議論する価値のあるオートエンコーダトレーニング手順の一部は、損失関数です。データの再構築は生成タスクであり、正しいクラスを予測する確率を最大化することを目的とする他の機械学習タスクとは異なり、ネットワークを駆動して入力に近い出力を生成します。
この目的は、l1、l2、平均二乗誤差などのいくつかの損失関数を使用して達成できます。これらの損失関数に共通しているのは、入力と出力の差(つまり、どれだけ離れているか、または同一であるか)を測定し、それらのいずれかを適切な選択にすることです。
オートエンコーダネットワーク
この間、私たちは多層パーセプトロンを使用してエンコーダーとデコーダーの両方を設計してきましたが、畳み込みニューラルネットワーク(CNN)などのより特殊なフレームワークを使用して、入力データに関するより多くの空間情報をキャプチャできることがわかりました。画像データ圧縮の場合。
驚くべきことに、テキストデータのオートエンコーダーとして使用されるリカレントネットワークは非常にうまく機能することが研究によって示されていますが、この記事の範囲ではそれについては説明しません。多層パーセプトロンで使用されるエンコーダー潜在ベクトルデコーダーの概念は、畳み込みオートエンコーダーにも当てはまります。唯一の違いは、畳み込み層を使用してデコーダーとエンコーダーを設計していることです。
これらのオートエンコーダネットワークはすべて、圧縮タスクには非常にうまく機能しますが、1つの問題があります。
私たちが議論したネットワークは創造性がゼロです。私がゼロの創造性とは、彼らが見た、または訓練されたアウトプットしか生成できないということです。
アーキテクチャの設計を少し調整することで、ある程度の創造性を引き出すことができます。結果は、変分オートエンコーダとして知られています。
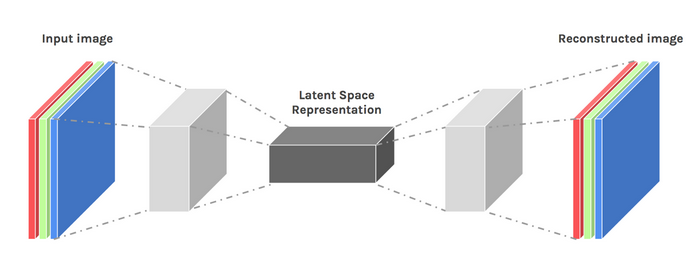
画像はDawidKopczykの好意により使用されました
変分オートエンコーダ
変分オートエンコーダは、2つの主要な設計変更を導入します。
- 入力を潜在的なエンコーディングに変換する代わりに、平均と分散の2つのパラメータベクトルを出力します。
- KL発散損失と呼ばれる追加の損失項が初期損失関数に追加されます。
変分オートエンコーダーの背後にある考え方は、エンコーダーによって生成された平均ベクトルと分散ベクトルによってパラメーター化された分布からサンプリングされた潜在ベクトルを使用して、デコーダーにデータを再構築させたいということです。
ディストリビューションからのサンプリング機能は、デコーダーに生成元の制御されたスペースを付与します。変分オートエンコーダーをトレーニングした後、入力データを使用してフォワードパスを実行するたびに、エンコーダーは潜在ベクトルをサンプリングする分布を決定するための平均と分散のベクトルを生成します。
平均ベクトルは、入力データのエンコーディングを中心とする場所を決定し、分散は、現実的な出力を生成するためにエンコーディングを選択する半径方向の空間または円を決定します。これは、同じ入力データを使用するすべてのフォワードパスで、変分オートエンコーダーが平均ベクトルを中心に分散空間内で出力のさまざまなバリアントを生成できることを意味します。
比較のために、標準のオートエンコーダーを見ると、ネットワークがトレーニングされていない出力を生成しようとすると、エンコーダーが生成する潜在的なベクトル空間の不連続性のために非現実的な出力が生成されます。
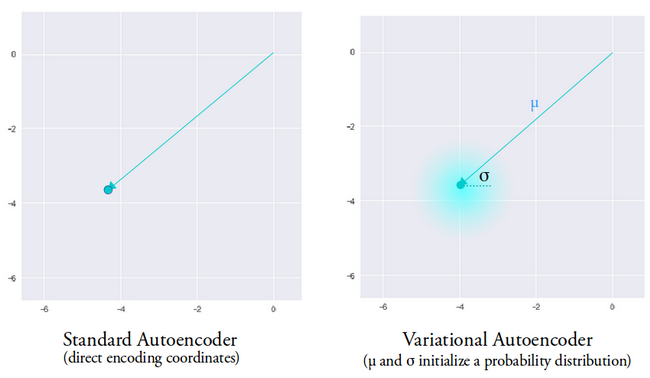
画像はIrhumShafkatの好意により使用されました
変分オートエンコーダーを直感的に理解できたので、TensorFlowでオートエンコーダーを構築する方法を見てみましょう。
変分オートエンコーダのTensorFlowコード
データセットを準備することから例を開始します。わかりやすくするために、MNISTデータセットを使用します。
(train_images、_)、(test_images、_)=tf.keras.datasets.mnist.load_data()
train_images =train_images.reshape(train_images.shape [0]、28、28、1).astype( 'float32')
test_images =test_images.reshape(test_images.shape [0]、28、28、1).astype( 'float32')
#画像を[0.、1。]の範囲に正規化する
train_images / =255。
test_images / =255。
#Binarization
train_images [train_images> =.5] =1。
train_images [train_images <.5] =0。
test_images [test_images> =.5] =1。
test_images [test_images <.5] =0。
TRAIN_BUF =60000
BATCH_SIZE =100
TEST_BUF =10000
train_dataset =tf.data.Dataset.from_tensor_slices(train_images).shuffle(TRAIN_BUF).batch(BATCH_SIZE)
test_dataset =tf.data.Dataset.from_tensor_slices(test_images).shuffle(TEST_BUF).batch(BATCH_SIZE)
データセットを取得し、タスク用に準備します。
class CVAE(tf.keras.Model):
def __init __(self、leistent_dim):
super(CVAE、self).__ init __()
self.latent_dim =潜在_dim
self.inference_net =tf.keras.Sequential(
<コード> [
tf.keras.layers.InputLayer(input_shape =(28、28、1))、
<コード> tf.keras.layers.Conv2D(
<コード> filters =32、kernel_size =3、strides =(2、2)、activation ='relu')、
<コード> tf.keras.layers.Conv2D(
<コード> filters =64、kernel_size =3、strides =(2、2)、activation ='relu')、
tf.keras.layers.Flatten()、
#アクティベーションなし
tf.keras.layers.Dense(latent_dim +潜在_dim)、
<コード>]
<コード>)
self.generative_net =tf.keras.Sequential(
<コード> [
tf.keras.layers.InputLayer(input_shape =(latent_dim、))、
tf.keras.layers.Dense(units =7 * 7 * 32、activation =tf.nn.relu)、
tf.keras.layers.Reshape(target_shape =(7、7、32))、
tf.keras.layers.Conv2DTranspose(
<コード> filters =64、
kernel_size =3、
strides =(2、2)、
padding ="SAME"、
Activation ='relu')、
tf.keras.layers.Conv2DTranspose(
<コード> filters =32、
kernel_size =3、
strides =(2、2)、
padding ="SAME"、
Activation ='relu')、
#アクティベーションなし
tf.keras.layers.Conv2DTranspose(
filters =1、kernel_size =3、strides =(1、1)、padding ="SAME")、
<コード>]
<コード>)
@ tf.function
def sample(self、eps =None):
epsがNoneの場合:
eps =tf.random.normal(shape =(100、self.latent_dim))
return self.decode(eps、apply_sigmoid =True)
def encode(self、x):
平均、logvar =tf.split(self.inference_net(x)、num_or_size_splits =2、axis =1)
return mean、logvar
def reparameterize(self、mean、logvar):
eps =tf.random.normal(shape =mean.shape)
return eps * tf.exp(logvar * .5)+ mean
def decode(self、z、apply_sigmoid =False):
logits =self.generative_net(z)
if apply_sigmoid:
probs =tf.sigmoid(logits)
return probs
return logits
2つのコードスニペットは、データセットを準備し、変分オートエンコーダモデルを構築します。モデルコードスニペットには、エンコード、サンプリング、およびデコードを実行するためのヘルパー関数がいくつかあります。
勾配を計算するための再パラメーター化
まだ説明していない再パラメータ化機能がありますが、変分オートエンコーダネットワークの非常に重大な問題を解決します。デコード段階で、エンコーダーによって生成された平均および分散ベクトルによって制御される分布から潜在ベクトルエンコードをサンプリングすることを思い出してください。これにより、ネットワークを介してデータを順方向に伝播する場合は問題は発生しませんが、サンプリング操作は微分不可能であるため、デコーダーからエンコーダーに勾配を逆方向に伝播する場合に大きな問題が発生します。
簡単に言うと、サンプリング操作から勾配を計算することはできません。
この問題の適切な回避策は、再パラメーター化のトリックを適用することです。これは、最初に平均0と分散1の標準ガウス分布を生成し、次にエンコーダーによって生成された平均と分散を使用して、この分布に対して微分可能な加算および乗算演算を実行することによって機能します。
コード内で分散を対数空間に変換していることに注意してください。これは、数値の安定性を確保するためです。追加の損失項であるカルバック・ライブラー発散損失は、生成する分布が平均0と分散1の標準ガウス分布にできるだけ近くなるようにするために導入されました。
分布の平均をゼロに駆動することで、生成する分布が互いに非常に近くなり、分布間の不連続性を防ぐことができます。 1に近い分散は、エンコーディングを生成するためのより適度な(つまり、それほど大きくも小さくもない)スペースがあることを意味します。
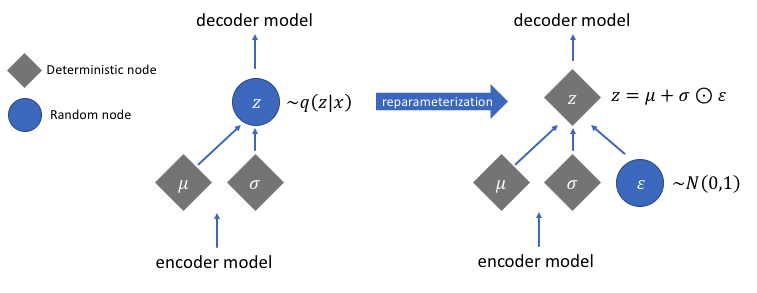
画像はJeremyJordanの好意により使用されました
再パラメーター化のトリックを実行した後、分散ベクトルに標準のガウス分布を乗算し、その結果を平均ベクトルに追加することによって得られる分布は、平均ベクトルと分散ベクトルによってすぐに制御される分布と非常によく似ています。
変分オートエンコーダを構築するための簡単な手順
変分オートエンコーダを構築する手順を要約して、このチュートリアルを締めくくりましょう。
- エンコーダーとデコーダーのネットワークを構築します。
- エンコーダとデコーダの間にパラメータ再設定のトリックを適用して、バックプロパゲーションを可能にします。
- 両方のネットワークをエンドツーエンドでトレーニングします。
上記で使用されている完全なコードは、TensorFlowの公式ウェブサイトにあります。
ChimanKwanから変更された注目の画像
産業用ロボット
- 3Dプリンターが金属オブジェクトを構築する方法
- 自律型ロボットで無駄を減らす方法
- クラウドテクノロジーを保護する方法は?
- データをどうすればいいですか?!
- IoTがHVACビッグデータにどのように役立つか:パート2
- TechDataとIBMPart2を使用してIOTを現実のものにする方法
- TechDataとIBMPart1を使用してIoTを現実のものにする方法
- サプライチェーン企業がAIを使用してロードマップを構築する方法
- データマイニング、AI:産業ブランドがEコマースに追いつく方法
- ツールライフとは何ですか?機械データを使用してツーリングを最適化する方法
- CNC マシンの手入れ? Cobot を使った方法はこちら