


MROデータクレンジングでコストを削減
今日の産業および製造業で競争と技術が進化し続けるにつれて、企業は、生産品質を維持しながらコストを削減し、効率を向上させるというますます増大する課題に直面しています。これらの製造会社は、多くの場合、地理的に広い地域に複数のサイトがあり、それぞれに数千の保守、修理、運用(MRO)スペアパーツがあり、運用を継続しています。このような大規模な組織では、複数の異なる従業員が各サイトのさまざまな企業資産管理(EAM)システムにアイテムを入力します。標準のガイドラインはほとんど、またはまったくなく、多くの場合、複数の言語で入力されます。時間の経過とともに、この標準化の欠如により、材料データの一貫性が失われ、不正確になり、ビジネスのすべての部門で感じられる可能性のある多くの悪影響が生じます。
破損した材料データによって引き起こされる最も一般的な影響は次のとおりです。
- 識別できないアイテム
- 過剰在庫
- 複製
- 誤った在庫切れ
- 機器のダウンタイム
- 非効率的なパーツ検索
- マーベリック購入の増加(直接購入)
- EAMシステムによる限定的なメリット
これらの非効率性は、企業が重要なデータ主導の意思決定を行うことを妨げながら、企業に多大な時間とお金を費やす可能性があります。
データクレンジングプロセス
破損したデータを一貫した品質のデータに変換するには、データクレンジングプロセスを実装して、組織全体で維持できる1つの共通の企業カタログを作成する必要があります。
データクレンジングプロセスは本質的に非常に単純に見えるかもしれませんが、非常にユニークで特殊なソフトウェア、人員、および手順のセットが必要です。一部のデータクレンジング会社は、自動化されたソフトウェアの使用による効率と速度に誇りを持っていますが、実際には、人間の介入なしに大量のデータファイルを正確にクレンジングできるソフトウェアアプリケーションはありません。データクレンジングプロセスは実際にははるかに詳細であり、最も正確な結果を得るには、自動化されたソフトウェアアプリケーションを使用し、一貫性、正確性、効率を確保するためにクレンジングスペシャリストの関与を組み合わせる必要があります。
データクレンジングプロセスを最初から最後まで説明するために、9つのステップに分けられています。すべてのプロジェクトは特定の顧客の要件に基づいて異なりますが、これらの9つのステップは、すべてのデータクレンジングプロジェクトに関連する標準的な手順をカバーしています。
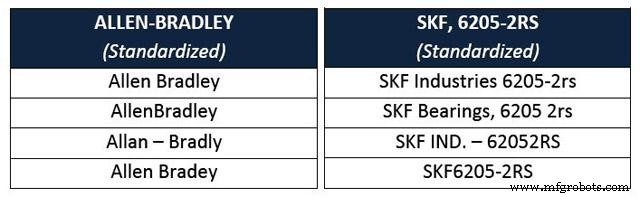
ステップ1–メーカー名と部品番号を分離して標準化する
自動化されたソフトウェアを使用して、メーカー名と部品番号が抽出され、構造化されていないフリーテキストの説明から分離されます。分離されると、メーカー名と部品番号が修正および標準化され、一意のメーカー名と部品番号がデータベース全体で1つの一貫した構造を維持するようになります。
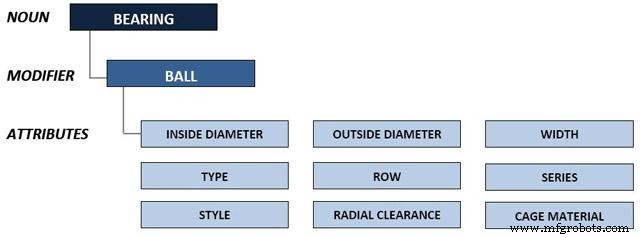
ステップ2–名詞修飾子と必要な属性を割り当てる
メーカー名と部品番号の分離と標準化に続いて、名詞修飾子辞書を使用して、各アイテムに正しい識別子と説明的なプロパティを割り当てます。以下に示すように、名詞修飾子ディクショナリを使用して、各アイテムに名詞修飾子ペアが割り当てられます。ここで、名詞はプライマリ識別子であり、修飾子はセカンダリ識別子です。各名詞修飾子のペアには、平均して5〜7個の関連する属性も含まれています。これらの属性は、そのアイテムの特性をさらに詳しく説明しています。
ステップ3–属性を入力する
顧客の生の説明で提供される情報を標準化して入力した後、残りの属性は、数百万の事前標準化されたアイテムを含むマスターパーツライブラリなどの内部および外部ツールを使用して入力されます。オンライン調査ツールは、追加の部品情報の検索と収集を支援します。これらの強力なツールを使用すると、メーカーのカタログから直接取得した情報を使用して、アイテムの説明を正確かつ効率的に強化できます。
ステップ4–分類コードを割り当てる
すべてのアイテムが名詞、修飾子、および対応する属性によって正しく記述されたら、顧客指定の分類コードを割り当てることができます。分類コードは通常、商品のセグメンテーション、支出分析、およびその他のカスタムレポートに使用され、企業が購入を活用して、調達関連の効率を改善するための洞察を得ることができます。
ステップ5–重複アイテムを特定する
クレンジングと分類が完了した後、データベース内の重複アイテムは、直接重複(同じメーカー名と部品番号)またはform-fit-function(異なるメーカー名と部品番号ですが、タイプ、サイズ、材料によって同じ)によって識別されます。重複が特定されると、1つの共通の企業部品番号が割り当てられ、説明が複製されてデータベース全体で同一に表示され、アイテムに顧客レビューのフラグが付けられます。
ステップ6–品質管理レビュー
品質と一貫性に重点が置かれているため、次のステップでは、すべてのアイテムの最終的な人間によるレビューが行われます。通常、割り当てられたプロジェクトリーダーまたは専任の品質管理担当者が実施します。品質管理プロセスにより、すべてのアイテムが事前定義された顧客基準に従って適切な形式と命名法に従うようになり、拡張された説明が正しく、正確で、完全であることを確認します。
ステップ7–レビューリストを顧客に送信する
平均して、材料データベースの10%がレビュー項目であることがわかります。つまり、製造元名や部品番号などの正確な部品識別のための重要な情報が不足している項目を意味します。データクレンジングプロセス中に、これらのアイテムにフラグが付けられ、カスタマーレビューリストにまとめられます。レビューリストは顧客に返送され、顧客は倉庫内でアイテムを物理的に見つけて、材料マスターに追加する必要のある部品情報を記録する必要があります。
ステップ8–データを顧客のERPシステムにフォーマットする
すべてのレビュー項目について欠落している情報が収集され、クレンジングされたデータベース全体が品質管理によって承認されると、それは完全であると見なされ、IT部門に転送されます。この段階で、ITスペシャリストは、データを顧客指定のエンタープライズリソースプランニング(ERP)システムにフォーマットし、それをリターンファイルに抽出します。すべてのERPシステムには独自のレイアウト、ヘッダー、フィールド制限があるため、フォーマット段階は目的の最終結果を達成するために重要です。
ステップ9–クレンジングされたファイルを返す
データファイル全体がクレンジング、標準化、拡張、重複排除、レビューされ、顧客のERPシステムにフォーマットされると、電子的に顧客に配信されます。この時点で、データをお客様のERPシステムに直接アップロードできるようになりました。
結果
審美的には、データは組織全体で1つの一貫した形式と命名法を明確に維持しながら、部品の識別を改善するための拡張情報を含んでいるため、データクレンジングの結果は明らかです。ただし、実際のメリットは、視覚的には明らかではないかもしれませんが、投資収益率が最大になることです。最も価値のある利点は、時間が重要なときに部品をすばやく検索して見つける能力を向上させ、機器のダウンタイムを最小限に抑える一方で、余分な、陳腐化した、重複したアイテムを識別して削除する機能から得られる利点です。主なメリットは次のとおりです。
1.コスト削減
- 過剰にアクティブで廃止された在庫の特定
- 重複アイテムの識別と削除
- 機器のダウンタイムの削減
- 異端者の購入の削減
- 迅速な部品注文の削減
2.メンテナンス効率の向上
- 効率的なパーツ検索
3.最大のERP / EAMのメリット
- 改善されたレポート機能
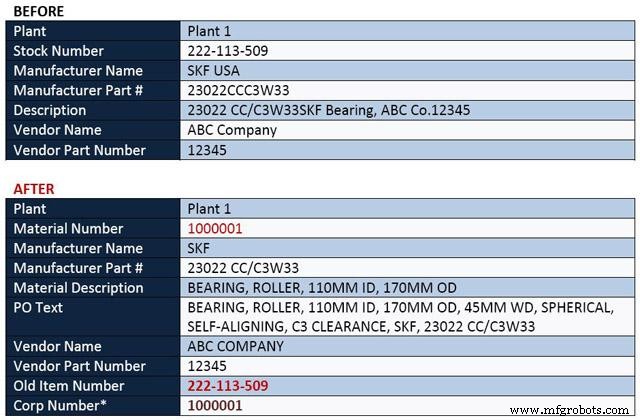
長期的な観点から、高品質の材料データは、運用コストと効率を維持するための鍵です。データクレンジングプロジェクトが完了すると、このプロセスは終了しません。継続的なデータ品質を維持するには、新しいアイテムが追加されたり、既存のアイテムが変更または一時停止されたりするときに正確性と一貫性を確保するための一連の厳密なカタログ管理手順が必要です。ほとんどのデータクレンジング会社は、クレンジングされたカタログの品質を維持するために、顧客に何らかの種類のカタログ管理ソフトウェアまたはサービスを提供しています。ただし、顧客がカタログを管理するための内部リソースを割り当てることができない限り、このアクティビティを最初にデータベースをクレンジングした専門家にアウトソーシングすると、常に最良の結果が得られます。
作者について
Jocelyn Facciottiは、I.M.A。のマーケティングマネージャーです。 MROデータクレンジングおよび関連サービスを専門とする会社。詳細については、www.imaltd.comにアクセスするか、info @ imaltd.comにお問い合わせください。
機器のメンテナンスと修理