


大規模な人工知能の運用によるより良いビジネス成果
人工知能(AI)は、さまざまな業界の企業に新たな常識をもたらしています。たとえば、小売業者はAIを使用して、過去の在庫データの発注書を予測し、インテリジェントな補充決定を推進できます。カスタマーサポートチームはAIを使用して、優先度の高いカスタマーサポートチケットに自動的に応答し、適切なチームにルーティングできます。 AI、特にMLを使用して、実用的なビジネス成果を推進できる可能性の世界があります。
Deloitte Insightsによると、エンタープライズAIの早期導入者の83%が、本番環境のプロジェクトからの投資収益率(ROI)がプラスであると考えています。これらには、AIを使用したサードパーティのエンタープライズソフトウェアの実装、チャットボットと仮想アシスタントの使用、eコマースプラットフォーム用の推奨エンジンなどの例が含まれていました。調査対象の企業の83%は、2019年にAIへの支出を増やすことを計画していました。AIに投資している企業のうち、63%がMLを採用していました。
AIとMLを実用的に使用してビジネス目標を達成するための戦略を構築することは、多くの企業にとって最優先事項です。多くの人にとって、MLを正常に運用するための主な課題は、組織全体での全体的なML展開の管理を理解、計画、および実行することです。
MLを運用するための重要な考慮事項
データサイエンスのライフサイクルに取り組む「正しい」方法は、組織によって異なります。データサイエンスのライフサイクル手順を体系化および標準化するために、多くの試みがなされてきました。ただし、すべての企業のニーズを取り入れたアプローチはありません。
データとデータサイエンスのための持続可能で維持可能な戦略を採用することは、各企業に固有の進化し続ける演習です。すべての企業のニーズ、構造、機能は独自のものであるため、柔軟でスケーラブルなMLモデルを構築し、全体的なデータサイエンス戦略を実行するには、企業全体の利害関係者に相談する必要があります。
各企業が対処しなければならない運用上の課題とインフラストラクチャおよび開発慣行の変更は異なります。
データサイエンスのライフサイクルを定義および進化させる際には、組織が文化、システム、およびニーズを考慮することが重要です。チーム間で提示する基本フレームワークを持つことは、MLの運用化を開発および進化させ続けながら、コミュニケーションの共通基盤を開発するのに役立ちます。
組織がMLの旅を始めるのに役立つ標準的なフレームワークを見ていきましょう。
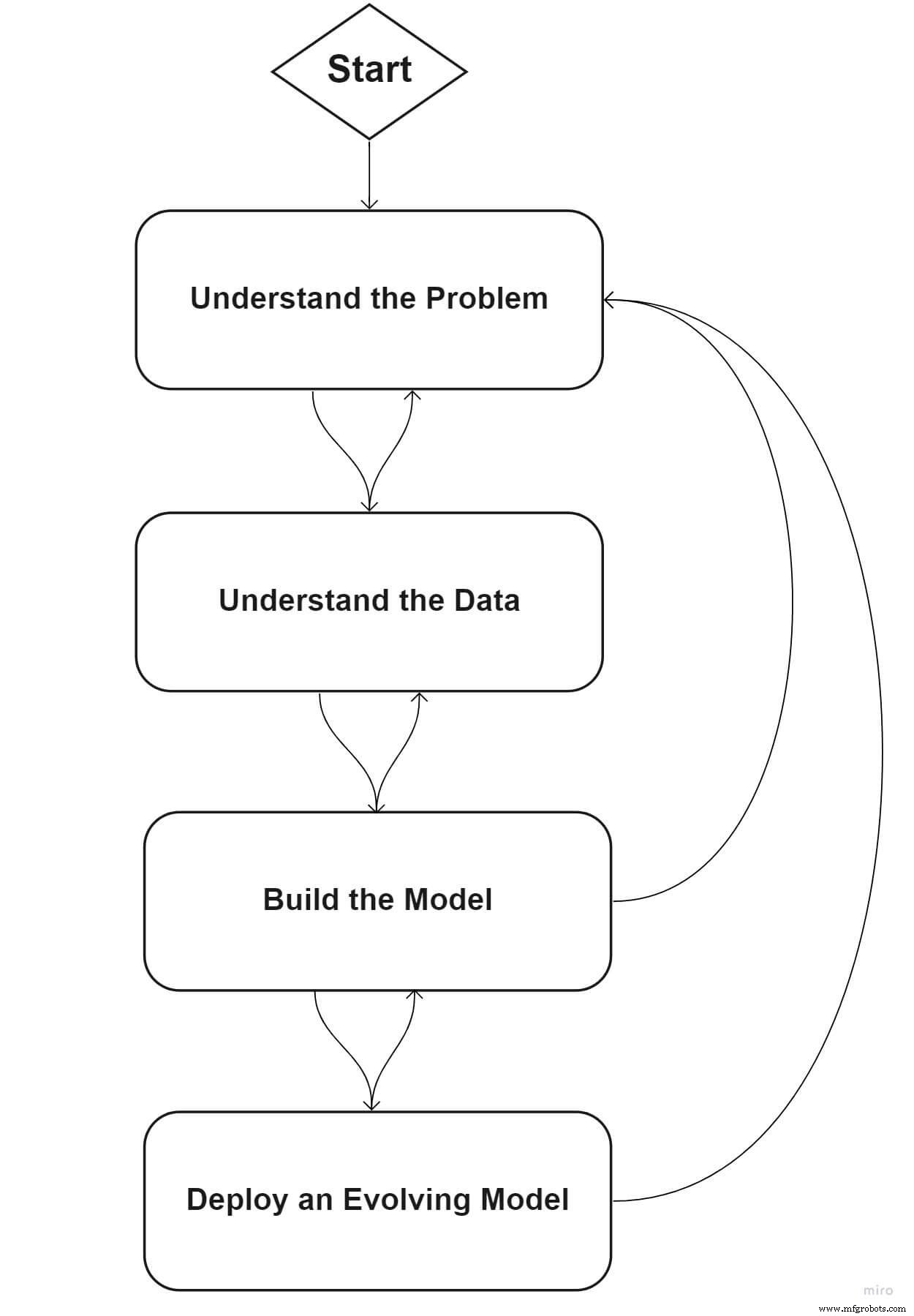
フェーズ1:問題を定義する
MLイニシアチブの中核には、2つの質問があります。
1.どのような問題を解決しようとしていますか?
2. MLとデータの理解を深めることで、目前の問題を解決できると思うのはなぜですか?
これらの質問に対する答えは、会社が戦略についてどのように考え、ビジネス上の問題を評価するかによって異なります。
フェーズ1では、主要な利害関係者が集まって、問題の初期範囲とその要件を定義する必要があります。
フェーズ2:データを理解する
あなたのデータのストーリーは何ですか?データはどこから来ており、特定のビジネス上の問題を解決するのに役立つデータソースはいくつありますか?
このフェーズでは、企業は次のことに重点を置きます。
-
関連するデータソースとそれらが存在する環境のマッピング(このような環境は、オンプレミスまたはクラウドにあり、データウェアハウス、データレイク、またはストリーミングデータプラットフォームとして設定されている場合があります)
-
現在存在するデータパイプラインと、データの検証、クリーンアップ、および調査のために構築する必要のあるデータパイプラインを定義する
-
データが更新される頻度を理解する
-
データの信頼性を理解する
-
データプライバシーの考慮事項と要件の評価
-
視覚化、生データと変換されたデータの統計的特性などを通じてデータ探索を可能にします。
データを理解することは簡単な作業ではありません。このフェーズに繰り返し取り組むことが重要です。データについて詳しく知ると、問題を解決する能力に影響を与える問題が見つかる可能性があります。そのため、フェーズ1から問題を再定義または再スコープする必要があります。
フェーズ3:MLモデルを構築する
データの準備ができたら、データサイエンティストがMLモデルを構築します。堅牢なMLモデルを構築するための一般的な手順は次のとおりです。
-
機能の抽出とエンジニアリング(ビニング、データホワイトニング、統計変換の適用を含む)
-
機能の選択
-
モデルのトレーニング(データを任意の数のトレーニング、相互検証、および検証データセットに分割することを含む)
-
ハイパーパラメータの調整
-
モデルの評価
-
統計的有意性の検証
モデルを開発するには、ビジネスの利害関係者からの継続的なフィードバックが必要です。たとえば、ビジネス上の問題では、特異性に対する感度への親和性が必要になる場合があります。同様に、わずかな予測パフォーマンス(F1スコアなど)をモデルの運用パフォーマンス(予測の高速化など)またはモデルの説明可能性とトレードオフすることもできます。
データサイエンティストの目標は、データを使用してビジネス上の問題に関連する明確なストーリーを伝えるモデルを構築することです。問題が進展し、要件が変化するにつれて、モデリングへのアプローチも進化して、現在のコンテキストに対応する必要があります。
フェーズ4:進化するモデルを展開する
初期モデルの構築は、MLの旅の始まりにすぎません。進化するモデルを展開することは、組織の長期的な価値創造にとって重要なステップです。
進化するモデルを展開するには、次のものが必要です。
-
モデルを提供する(モデルの可用性を高め、水平方向にスケーラブルにする)
-
モデルバージョンの管理(ロールバックおよびカナリア/チャレンジャーの展開を含む)
-
モデルの再トレーニング(新しいデータがシステムに入力されたときに新しいモデルを変更または構築する)
-
モデルの監視(サービス時間とトレーニング時間での運用とユーザーエクスペリエンスの両方のメトリックの追跡)
データとモデルのドリフトを監視し、対象となる組織内のユースケースに合わせてモデルを特殊化する必要があり、(他の維持項目の中でも)データパイプラインを維持することは、モデルの継続的な成功にとって重要です。
企業全体および業界全体の要件は急速に進化し、データソースと入力に影響を与える可能性があります。たとえば、大規模なガバナンスとコンプライアンスは、データサイエンスのライフサイクル全体にわたる考慮事項です。
欧州連合(EU)の一般データ保護規則(GDPR)などの規制への準拠には、データバージョン管理、モデルバージョン管理、およびモデル入力レイヤーでのより深いレベルのトレーサビリティが必要です。データを通じてこれらの業界の変化と要件に対応する戦略を構築することで、企業は引き続きMLを活用して、収益の増加、コストの削減、リスクの軽減などのビジネス成果を向上させることができます。
次は?
MLを柔軟で、保守可能で、スケーラブルな方法で運用するには、このブログで概説した高レベルの範囲を超えた多くの手順と考慮事項が必要です。悪魔は細部に宿っています。
次のブログでは、技術的な考慮事項、大規模なMLシステムのアドホック実装から発生する可能性のある課題、およびUiPathが企業顧客の一般的な課題への取り組みにどのように役立つかについて詳しく説明します。
自動制御システム